【8.23校内测试】【贪心】【线段树优化DP】

$m$的数据范围看起来非常有问题??仔细多列几个例子可以发现,在$m<=5$的时候,只要找到有两行状态按位$&$起来等于$0$,就是可行方案,如果没有就不行。
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std; int cnt[<<+], n, m; int main ( ) {
freopen ( "prob.in", "r", stdin );
freopen ( "prob.out", "w", stdout );
int T;
scanf ( "%d", &T );
while ( T -- ) {
memset ( cnt, , sizeof ( cnt ) );
scanf ( "%d%d", &n, &m );
for ( int i = ; i <= n; i ++ ) {
int t = ;
for ( int j = ; j < m; j ++ ) {
int a;
scanf ( "%d", &a );
t |= a << j;
}
cnt[t] ++;
}
int flag = ;
int tot = ( << m ) - ;
for ( int i = ; i <= tot; i ++ )
for ( int j = i + ; j <= tot; j ++ ) {
if ( !cnt[i] || !cnt[j] ) continue;
if ( ( i & j ) == ) {
flag = ; break;
}
}
if ( flag ) printf ( "YES\n" );
else printf ( "NO\n" );
}
return ;
}
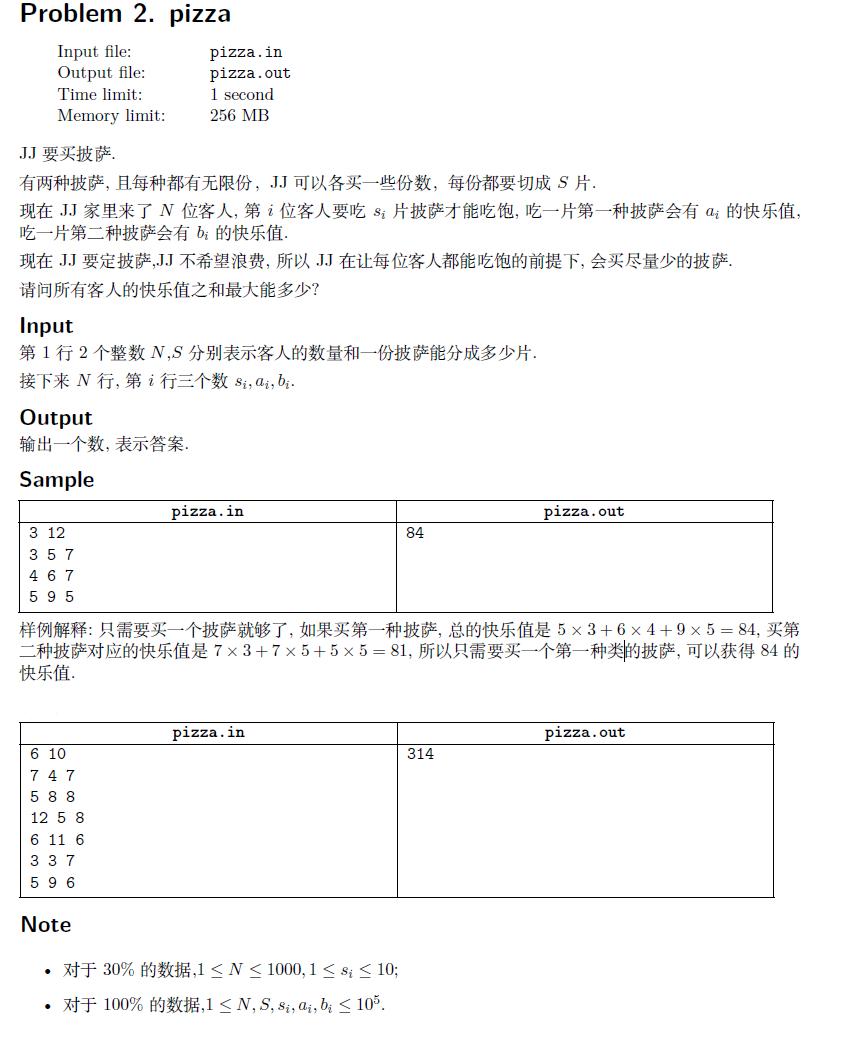
考场上想了好久,觉得这道题是个好复杂的分组背包aaa!!$qwq$,复杂度怎么可能达得到要求!!!
正解贪心...其实正确性还是显然的,因为饼数一定,我们把喜欢吃$a$饼和喜欢$b$饼的人分开,分别按他们的喜欢程度从大到小排序(喜欢程度指$a_i-b_i$或者$b_i-a_i$),我们尽量满足喜欢程度大的人的需求,可是在喜欢$a$和喜欢$b$之间有一个分界线,那里两边的人可能会在$a$和$b$中浮动,可能各选择一部分,因为我们按喜欢程度排的序,就算分界线上的人吃了不太喜欢的那种饼,也是总的快乐值亏得最少的情况。
所以我们先定一个$tot1$,是完全使喜欢$a$饼的全吃到$a$饼,此时可能$b$饼数量不够分给喜欢$b$的人,喜欢$b$中最喜欢$a$的那几个可能被迫吃到$a$,此时是一种情况。另一种则是少给$a$组分配一个,多给$b$组一个,$a$中最喜欢$b$的那几个就会被迫吃到$b$。这两种情况中更优的那个即是答案。可以证明其他情况(多给$a$两个饼少给$b$两个饼)一定会是更劣的,因为这样喜欢吃某种饼的人吃到喜欢的变少了,无用的变多了。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#define ll long long
using namespace std; int n, S, num1, num2; struct node {
int a, b, delta;
ll s;
node ( ll s = , int a = , int b = , int delta = ) :
s ( s ), a ( a ), b ( b ), delta ( delta ) { }
} cos1[], cos2[];
bool cmp ( node a, node b ) { return a.delta > b.delta; } ll sov ( ll tot1, ll tot2 ) {
ll s1 = tot1 * S, s2 = tot2 * S;
ll ans = ;
for ( int i = ; i <= num1; i ++ ) {
ll qwq = cos1[i].s;
qwq -= min ( qwq, s1 ); s1 -= min ( s1, cos1[i].s );
ans += 1ll * cos1[i].a * ( cos1[i].s - qwq );
if ( qwq ) { ans += 1ll * qwq * cos1[i].b; s2 -= qwq; }
}
for ( int i = ; i <= num2; i ++ ) {
ll qwq = cos2[i].s;
qwq -= min ( qwq, s2 ); s2 -= min ( s2, cos2[i].s );
ans += 1ll * cos2[i].b * ( cos2[i].s - qwq );
if ( qwq ) { ans += 1ll * qwq * cos2[i].a; s1 -= qwq; }
}
return ans;
} int main ( ) {
freopen ( "pizza.in", "r", stdin );
freopen ( "pizza.out", "w", stdout );
scanf ( "%d%d", &n, &S );
ll s = , sum1 = , sum2 = ;
for ( int i = ; i <= n; i ++ ) {
int s, a, b;
scanf ( "%d%d%d", &s, &a, &b );
int delta = a - b;
if ( delta >= ) sum1 += s, cos1[++num1] = node ( s, a, b, delta );
else sum2 += s, cos2[++num2] = node ( s, a, b, -delta );
}
sort ( cos1 + , cos1 + + num1, cmp );
sort ( cos2 + , cos2 + + num2, cmp );
ll tot = ( sum1 + sum2 + S - ) / S, tot1 = ( sum1 + S - ) / S;
ll tot2 = tot - tot1;
ll tmp = sov ( tot1, tot2 );
if ( tot2 - > ) tmp = max ( tmp, sov ( tot1 + , tot2 - ) );
if ( tot1 - > ) tmp = max ( tmp, sov ( tot1 - , tot2 + ) );
printf ( "%I64d\n", tmp );
return ;
}

首先思考暴力做法,定义$dp[i][j]$表示到第$i$个冰淇淋用了$j$个桶时可以得到的最多颜色数。$dp[i][j]=max{dp[k][j-1]+c[k+1][i]}$,$1<=k<=i-1$,其中$c[i][j]$表示从第$i$个冰淇淋到第$j$个的颜色数。
直接暴力枚举复杂度是$O(n^2)$的。考虑如何优化。
可以发现上面的$dp$转移方程中,$j$只会从$j-1$转移得到,我们可以压维。我们把$dp[k][j-1]+c[k+1][i]$看成一个值,问题其实是求一段区间内的最大值。可以用线段树,每个$j$新建一棵线段树,叶子节点储存上述值。
可是线段树怎么更新$c$数组?我们每遍历到一个冰淇淋$i$,因为当前是要把$k+1-i$装到一个桶,$i$影响的实际上是上一个$i$的颜色出现的位置到$i$,这段区间的$c$值需要$+1$,所以我们遍历到$i$时,先更新区间,然后直接查询当前最大的$dp$值即可。复杂度$O(nmlog_n)$。
【注意】因为叶子节点$k$储存的是$dp[k][j-1]+c[k+1][i]$,所以我们要更新$pre[i]+1$到$i$的$c$值,实际上是更新线段树上$pre[i]$到$i-1$这段区间。查询同理。
#include<iostream>
#include<cstdio>
using namespace std; int n, m, pre[], las[], a[];
int dp[][], TR[*], tag[*], now; void update ( int nd ) {
TR[nd] = max ( TR[nd<<], TR[nd<<|] );
} void push_down ( int nd ) {
if ( tag[nd] ) {
TR[nd<<] += tag[nd];
TR[nd<<|] += tag[nd];
tag[nd<<] += tag[nd];
tag[nd<<|] += tag[nd];
tag[nd] = ;
}
} void build ( int nd, int l, int r ) {
tag[nd] = ;
if ( l == r ) {
TR[nd] = dp[now^][l];
return ;
}
int mid = ( l + r ) >> ;
build ( nd << , l, mid );
build ( nd << | , mid + , r );
update ( nd );
} void add ( int nd, int l, int r, int L, int R, int d ) {
if ( l >= L && r <= R ) {
TR[nd] += d;
tag[nd] += d;
return ;
}
push_down ( nd );
int mid = ( l + r ) >> ;
if ( L <= mid ) add ( nd << , l, mid, L, R, d );
if ( R > mid ) add ( nd << | , mid + , r, L, R, d );
update ( nd );
} int query ( int nd, int l, int r, int L, int R ) {
if ( l >= L && r <= R ) return TR[nd];
push_down ( nd );
int mid = ( l + r ) >> , ans = ;
if ( L <= mid ) ans = max ( ans, query ( nd << , l, mid, L, R ) );
if ( R > mid ) ans = max ( ans, query ( nd << | , mid + , r, L, R ) );
return ans;
} int main ( ) {
freopen ( "scream.in", "r", stdin );
freopen ( "scream.out", "w", stdout );
scanf ( "%d%d", &n, &m );
for ( int i = ; i <= n; i ++ ) {
scanf ( "%d", &a[i] );
pre[i] = las[a[i]];
las[a[i]] = i;
}
for ( int i = ; i <= n; i ++ ) dp[now][i] = dp[now][i-] + ( pre[i] == );
for ( int j = ; j <= m; j ++ ) {
now ^= ;
build ( , , n );
for ( int i = ; i <= n; i ++ ) {
if ( i < j ) dp[now][i] = ;
else {
add ( , , n, max ( pre[i], ), i-, );
dp[now][i] = query ( , , n, , i- );
}
}
}
printf ( "%d", dp[now][n] );
return ;
}
【8.23校内测试】【贪心】【线段树优化DP】的更多相关文章
- [AGC011F] Train Service Planning [线段树优化dp+思维]
思路 模意义 这题真tm有意思 我上下楼梯了半天做出来的qwq 首先,考虑到每K分钟有一辆车,那么可以把所有的操作都放到模$K$意义下进行 这时,我们只需要考虑两边的两辆车就好了. 定义一些称呼: 上 ...
- Codeforces Round #426 (Div. 2) D 线段树优化dp
D. The Bakery time limit per test 2.5 seconds memory limit per test 256 megabytes input standard inp ...
- BZOJ2090: [Poi2010]Monotonicity 2【线段树优化DP】
BZOJ2090: [Poi2010]Monotonicity 2[线段树优化DP] Description 给出N个正整数a[1..N],再给出K个关系符号(>.<或=)s[1..k]. ...
- 【bzoj3939】[Usaco2015 Feb]Cow Hopscotch 动态开点线段树优化dp
题目描述 Just like humans enjoy playing the game of Hopscotch, Farmer John's cows have invented a varian ...
- POJ 2376 Cleaning Shifts (线段树优化DP)
题目大意:给你很多条线段,开头结尾是$[l,r]$,让你覆盖整个区间$[1,T]$,求最少的线段数 题目传送门 线段树优化$DP$裸题.. 先去掉所有能被其他线段包含的线段,这种线段一定不在最优解里 ...
- 洛谷$P2605\ [ZJOI2010]$基站选址 线段树优化$dp$
正解:线段树优化$dp$ 解题报告: 传送门$QwQ$ 难受阿,,,本来想做考试题的,我还造了个精妙无比的题面,然后今天讲$dp$的时候被讲到了$kk$ 先考虑暴力$dp$?就设$f_{i,j}$表示 ...
- D - The Bakery CodeForces - 834D 线段树优化dp···
D - The Bakery CodeForces - 834D 这个题目好难啊,我理解了好久,都没有怎么理解好, 这种线段树优化dp,感觉还是很难的. 直接说思路吧,说不清楚就看代码吧. 这个题目转 ...
- 4.11 省选模拟赛 序列 二分 线段树优化dp set优化dp 缩点
容易想到二分. 看到第一个条件容易想到缩点. 第二个条件自然是分段 然后让总和最小 容易想到dp. 缩点为先:我是采用了取了一个前缀最小值数组 二分+并查集缩点 当然也是可以直接采用 其他的奇奇怪怪的 ...
- Codeforces 1603D - Artistic Partition(莫反+线段树优化 dp)
Codeforces 题面传送门 & 洛谷题面传送门 学 whk 时比较无聊开了道题做做发现是道神题( 介绍一种不太一样的做法,不观察出决策单调性也可以做. 首先一个很 trivial 的 o ...
- 2021.12.08 P1848 [USACO12OPEN]Bookshelf G(线段树优化DP)
2021.12.08 P1848 [USACO12OPEN]Bookshelf G(线段树优化DP) https://www.luogu.com.cn/problem/P1848 题意: 当农夫约翰闲 ...
随机推荐
- HDU 1148 Rock-Paper-Scissors Tournament (模拟)
题目链接 Problem Description Rock-Paper-Scissors is game for two players, A and B, who each choose, inde ...
- Neuroph studio 入门教程
PERCEPTRON Perceptron is a simple two layer neural network with several neurons in input layer, and ...
- python slots源码分析
上次总结Python3的字典实现后的某一天,突然开窍Python的__slots__的实现应该也是类似,于是翻了翻CPython的源码,果然如此! 关于在自定义类里面添加__slots__的效果,网上 ...
- Deep Learning基础--各个损失函数的总结与比较
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好.损失函数是经验 ...
- [转载]锁无关的(Lock-Free)数据结构
锁无关的(Lock-Free)数据结构 在避免死锁的同时确保线程继续 Andrei Alexandrescu 刘未鹏 译 Andrei Alexandrescu是华盛顿大学计算机科学系的在读研究生,也 ...
- Python学习笔记——数据结构和算法(二)
1.字典中一个键映射多个值 可以使用collections中的defaultdict来实现,defalultdict接受list或者set为参数 from collections import def ...
- java关键字(详解)
目录 1. 基本类型 1) boolean 布尔型 2) byte 字节型 3) char 字符型 4) double 双精度 5) float 浮点 6) int 整型 7) long 长整型 8) ...
- plt-3D打印1
plt-3D打印 import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D ...
- 20165301 2017-2018-2 《Java程序设计》第七周学习总结
20165301 2017-2018-2 <Java程序设计>第七周学习总结 教材学习内容总结 第十一章:JDBC与MySQL数据库 MySQL数据库管理系统 启动MySQL数据库服务器 ...
- hdu 5839(三维几何)
Special Tetrahedron Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Othe ...