如何使用强化学习算法解决15-puzzle问题,即所谓的“十五谜题”推盘游戏
相关:
数字华容道15-Puzzle问题可以使用人工智能算法中的强化学习算法来进行求解,也可以使用人工智能算法中的启发式算法来进行求解。15-Puzzle问题存在不可解的情况,因此在对该问题进行求解时需要先确定给出的问题是否存在可行解。15-Puzzle 的最优解至多有 80 步;而 8-Puzzle 的最优解至多有 31 步。
启发式算法:
启发式函数考虑的因素可以有:
- 放错的方块的数量。
- 所有放错的方块到各自目标位置的欧几里得距离之和。
- 所有放错的方块到各自目标位置的曼哈顿距离之和。
强化学习算法:
使用强化学习可以用表格法,值迭代和策略迭代算法都是可以的;使用强化学习算法的关键点在于如何定义state状态,在https://medium.com/@amshali/15-puzzle-with-reinforcement-learning-8bcfc1aa54e7中给出了state状态的定义方法:
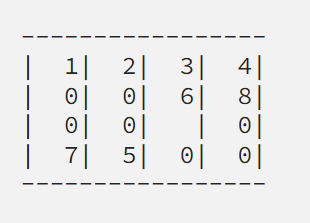
因为游戏的棋牌状态可以表示为:

我们可以把问题分解为三步,第一步就是解决第一行,第二步就是解决第二行,第三步就是解决第三行和第四行。在不同步骤的时候除了要考虑的行上正确时的数字和空格以外可以把其他的数字位置当做相同的数字0来进行处理,于是就有了第一步骤时的棋牌状态的表示:

采用该种表示方法后可以知道16-5=11,5为1,2,3,4以及空格这5个表示的可能,于是可以得到此时的棋牌状态的可以表示数量为:
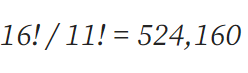
当第一行正确排列完成后我们假设不再对第一行的数字进行改动,因此此时的棋牌状态表示为:
同理,我们可以得到此时的棋牌的表示数量为(16-4=12,11-4=7):
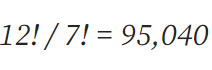
而到了解决最后两行时我们不再对前两行正确排列的位置进行变动,因此此时的最后两行的状态数量为:
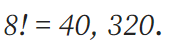
降阶法:
不论是启发式算法还是强化学习算法来解决15-puzzle问题,我们都可以通过降阶的方法,也就是先解决最外圈的数字的正确位置,把44问题转为33问题,然后再依次解决最外圈的数字位置问题,把33的puzzle转为22的问题。
关于棋牌的初始状态是否存在可行解的判断
目前没有找到相关的权威答案,也就是说从网上的资料来看还没有什么确切的方法来判断可行解的存在。对此,一个想法思路是从最终棋牌状态开始,进行一定次数的随机交换(比如1000次随机交换或10000次随机交换),那么最终的棋牌状态必然存在可行解,使用该种方法我们可以构建出一定数量的棋牌初始状态。
网上目前没有找到使用强化学习方法解决该问题的详实方法,这里只给出网上的关于启发式方法的解决资料:
如何使用强化学习算法解决15-puzzle问题,即所谓的“十五谜题”推盘游戏的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- A*算法解决15数码问题_Python实现
1问题描述 数码问题常被用来演示如何在状态空间中生成动作序列.一个典型的例子是15数码问题,它是由放在一个4×4的16宫格棋盘中的15个数码(1-15)构成,棋盘中的一个单元是空的,它的邻接单元中的数 ...
- 强化学习算法Policy Gradient
1 算法的优缺点 1.1 优点 在DQN算法中,神经网络输出的是动作的q值,这对于一个agent拥有少数的离散的动作还是可以的.但是如果某个agent的动作是连续的,这无疑对DQN算法是一个巨大的挑战 ...
- Linux学习之用户管理命令与用户组管理命令(十五)
Linux学习之用户管理命令与用户组管理命令 目录 用户管理命令 用户添加命令useradd 修改用户密码passwd 修改用户信息usermod 修改用户密码状态chage 删除用户userdel ...
- 算法:数字推盘游戏--重排九宫(8-puzzle)
一.数字推盘游戏 数字推盘游戏(n-puzzle)是一种最早的滑块类游戏,常见的类型有十五数字推盘游戏和八数字推盘游戏等.也有以图画代替数字的推盘游戏.可能Noyes Palmer Chapman在1 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
随机推荐
- m3u8文件转换mp4 ffmpeg
m3u8文件转换mp4 ffmpeg 命令行执行下面语句: ffmpeg -i input.m3u8 -c copy output.mp4 ffmpeg.exe 和 input.m3u8 放在同一目录 ...
- “Newtonsoft.Json”已拥有为“Microsoft.CSharp”定义的依赖项。
安装较低版本的Newtonsoft.Json: Newtonsoft.Json官网:https://www.nuget.org/packages/Newtonsoft.Json/ Install-Pa ...
- mysql GROUP_CONCAT使用
完整的语法如下: 1 group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符']) 基本查询 1 2 3 4 5 ...
- Bean Searcher v4.3.0 重大更新!
往期阅读: 我这样写代码,比直接使用 MyBatis 效率提高了 100 倍 最近火起的 Bean Searcher 与 MyBatis Plus 倒底有啥区别? Bean Searcher v3.8 ...
- Windows 下自动预约申购 i茅台
今天分享一个自动预约抢茅子的工具! 前期准备工作: 1.需安装:.Net6 依赖 (根据操作系统选择 x64 或 x86 版本进行下载.) 安装软件 1.软件下来下来之后,解压并进入软件目录,我们双击 ...
- kafka事务流程
流程 kafka事务使用的5个API // 1. 初始化事务 void initTransactions(); // 2. 开启事务 void beginTransaction() throws Pr ...
- tempCode
package com.cmbchina.monitor.service.imp; import com.alibaba.fastjson.JSON; import com.cmbchina.moni ...
- Nuxt 3组件开发与管理
title: Nuxt 3组件开发与管理 date: 2024/6/20 updated: 2024/6/20 author: cmdragon excerpt: 摘要:本文深入探讨了Nuxt 3的组 ...
- 使用getevent在Android中调试输入子系统
# Android getevent用法详解 背景 在调试安卓设备按键,想使用hexdump,但是发现没有找到,反而找到了这个更好用的工具. 以下是我的调试片段 # getevent -l /dev/ ...
- 创建docker
创建docker 准备实验环境 1. 安装前准备 Centos7 Linux 内核:官方建议 3.10 以上,3.8以上貌似也可. 1.1 查看当前的内核版本 uname -r 1.2 使用 root ...