jstorm系列-1:入门
一、 Storm整体介绍
Storm 是一个类似Hadoop MapReduce的系统, 用户按照指定的接口实现一个任务,然后将这个任务递交给JStorm系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个Worker 发生意外故障, 调度器立即分配一个新的Worker替换这个失效的Worker。
因此,从应用的角度,JStorm 应用是一种遵守某种编程规范的分布式应用。从系统角度, JStorm一套类似MapReduce的调度系统。 从数据的角度, 是一套基于流水线的消息处理机制。
实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的Hadoop MapReduce,逐渐满足不了需求,因此在这个领域需求不断。
1.1. Storm组件和Hadoop组件对比
|
Storm |
Hadoop |
|
|
角色 |
Nimbus |
JobTracker |
|
Supervisor |
TaskTracker |
|
|
Worker |
Child |
|
|
应用名称 |
Topology |
Job |
|
编程接口 |
Spout/Bolt |
Mapper/Reducer |
1.2. 优点
在Storm和JStorm出现以前,市面上出现很多实时计算引擎,但自Storm和JStorm出现后,基本上可以说一统江湖: 究其优点:
- 开发非常迅速:接口简单,容易上手,只要遵守Topology、Spout和Bolt的编程规范即可开发出一个扩展性极好的应用,底层RPC、Worker之间冗余,数据分流之类的动作完全不用考虑
- 扩展性极好:当一级处理单元速度,直接配置一下并发数,即可线性扩展性能
- 健壮强:当Worker失效或机器出现故障时, 自动分配新的Worker替换失效Worker
- 数据准确性:可以采用Ack机制,保证数据不丢失。 如果对精度有更多一步要求,采用事务机制,保证数据准确。
二、 安装
参考文档:
https://github.com/alibaba/jstorm/wiki/%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85
三、 storm详细讲解
3.1. storm的整体架构
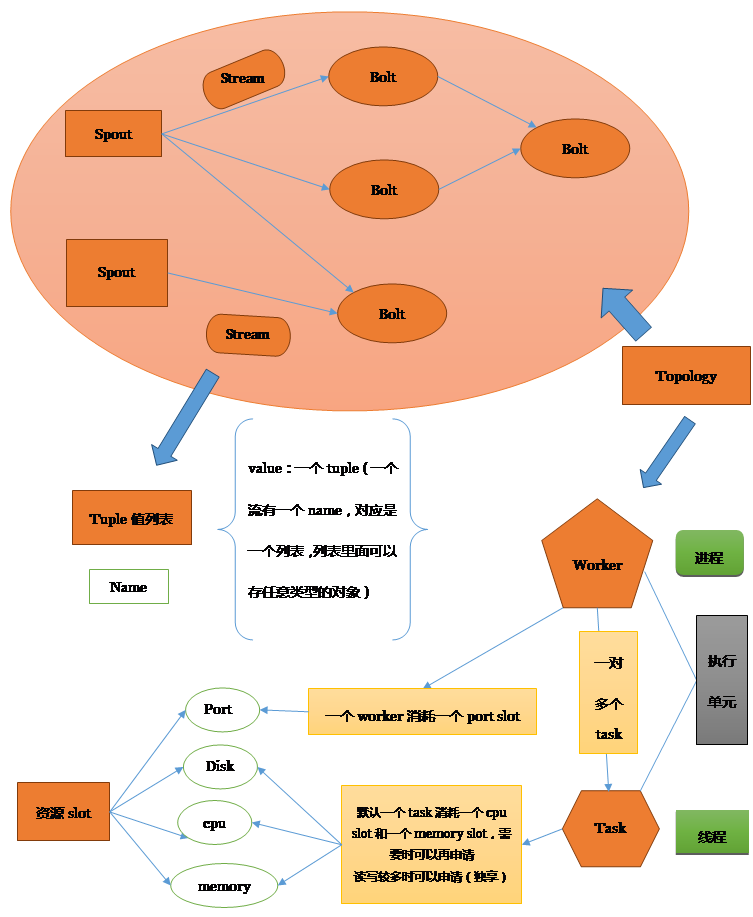
3.2. 基本概念简介
图中  这种颜色标识的是storm中的基本组件,包括:
这种颜色标识的是storm中的基本组件,包括:
Topology,bolt,spout,worker,task,slot,stream,tuple
3.2.1. Topology
Storm的核心是topology,程序以topology作为一个整体提交到集群上

3.2.2. Spout
数据流入口:spout程序负责从数据源读入数据,然后发射出去,形成一个stream流,可以被多个bolt接受,形成多个流
3.2.3. Bout
数据的消费者,从stream流中读取数据,处理数据
可以从不同的流中读取数据
3.2.4. Stream
Spout发射的数据形成数据流,
3.2.5. Worker
可以理解为一个topology承包给多少个包工头(worker)
3.2.6. Task
可以理解为工人,一个worker下面有多个task,每个task运行一个bolt或spout的实例
3.3. Bolt,spout和worker,task的关系

jstorm系列-1:入门的更多相关文章
- .NET 4 并行(多核)编程系列之一入门介绍
.NET 4 并行(多核)编程系列之一入门介绍 本系列文章将会对.NET 4中的并行编程技术(也称之为多核编程技术)以及应用作全面的介绍. 本篇文章的议题如下: 1. 并行编程和多线程编程的区别. ...
- Google C++测试框架系列:入门
Google C++测试框架系列:入门 原始链接:V1_6_Primer 注 GTest或者Google Test: Google的C++测试框架. Test Fixtures: 这个词实在找不到对应 ...
- Pandas系列之入门篇
Pandas系列之入门篇 简介 pandas 是 python用来数据清洗.分析的包,可以使用类sql的语法方便的进行数据关联.查询,属于内存计算范畴, 效率远远高于硬盘计算的数据库存储.另外pand ...
- Pandas系列之入门篇——HDF5
Pandas系列之入门篇--HDF5 简介 HDF5(层次性数据格式)作用于大数据存储,其高效的压缩方式节约了不少硬盘空间,同时也给查询效率带来了一定的影响, 压缩效率越高,查询效率越低.pandas ...
- Python系列之入门篇——HDFS
Python系列之入门篇--HDFS 简介 HDFS (Hadoop Distributed File System) Hadoop分布式文件系统,具有高容错性,适合部署在廉价的机器上.Python ...
- Python系列之入门篇——MYSQL
Python系列之入门篇--MYSQL 简介 python提供了两种mysql api, 一是MySQL-python(不支持python3),二是PyMYSQL(支持python2和python3) ...
- 【转】C# 串口操作系列(1) -- 入门篇,一个标准的,简陋的串口例子。
C# 串口操作系列(1) -- 入门篇,一个标准的,简陋的串口例子. 标签: c#objectnewlineexceptionbytestring 2010-05-17 01:10 117109人阅读 ...
- jstorm系列-2:入门
有了基本的概念之后,我们用jstorm来做一点小事情吧 做一个很无聊的事情:给定一个时间戳,输出对应的问候语 规则是:时间戳的十位对应的数字对应不同的时间段,0-2代表早上,3代表中午,4-6代表下午 ...
- pyqt系列原创入门教程
pyqt4入门教程 python pyqt4 PyQt是一个创建GUI应用程序的工具包.它是Python编程语言和Qt库的成功融合.Qt库是目前最强大的库之一. 通过pyqt可以实现很多我们想要的功能 ...
随机推荐
- POJ2689:Prime Distance——题解
http://poj.org/problem?id=2689 题目大意,给不超过int的l,r,其中r-l+1<=1000000,筛出其中的素数,并且求出相邻素数差值最大和最小的一对. ———— ...
- HDU4812 D tree 【点分治 + 乘法逆元】
D树 时间限制:10000/5000 MS(Java / Others)内存限制:102400/102400 K(Java / Others) 总共提交5400个已接受的提交1144 问题描述 南京理 ...
- Kubernetes - Launch Single Node Kubernetes Cluster
Minikube is a tool that makes it easy to run Kubernetes locally. Minikube runs a single-node Kuberne ...
- JavaScript知识之判断字符串中出现最多的字符及次数
var str = 'asdddasdfdseeeeeweeeeeeeeeeeee'; var json = {}; // 定义json一个对象 for(var i = 0; i < str.l ...
- 如何根据域名来得到对应的IP
如何根据域名来得到对应的IP呢? windows下打开cmd窗口,然后ping.如下图: 这样就可以看到IP了. 如何查看自己电脑对应的IP? 当通过代理上网时,可能无法通过网络连接信息查看自己电脑的 ...
- 2015/9/2 Python基础(7):元组
为什么要创造一个和列表差别不大的容器类型?元组和列表看起来不同的一点是元组用圆括号而列表用方括号.而最重要的是,元组是不可变类型.这就保证了元组的安全性.创造元组给它赋值和列表完全一样.除了一个元素的 ...
- word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method
最近接到任务研究word2vec,感觉网络上关于这个的资料层次不齐,总感觉解释的都没有那么完善.或许就连作者本人也不是非常清楚为什么他的模型好使.论文中提到的negtive sampling给了我很大 ...
- asp.net 文件上传,大文件上传。
新建一个asp.net页面,在工具栏里拖入 FileUpload 上传控件.一个按钮 Button ! ! ! 进入Button事件 //----------------------- ...
- [LA3135]node形式的优先队列
n个触发器,每个触发器每period秒就产生一个编号为qnum的事件,求前k个事件. n<=1000 k<=10000 node形式的优先队列 主要在于重载小于号,确定优先顺序. #in ...
- 【Foreign】Game [博弈论][DP]
Game Time Limit: 20 Sec Memory Limit: 512 MB Description 从前有个游戏.游戏分为 k 轮. 给定一个由小写英文字母组成的字符串的集合 S, 在 ...