R中apply函数族
参考于:http://blog.fens.me/r-apply/
1. apply的家族函数
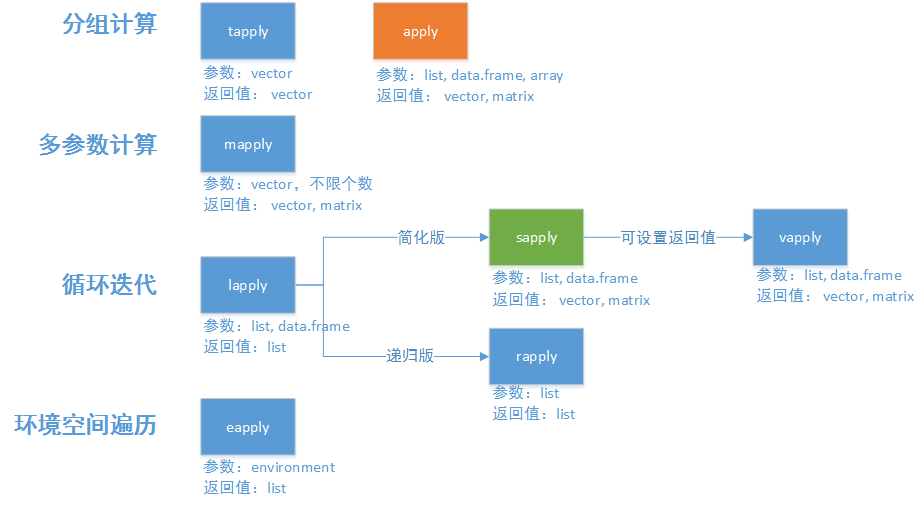
2. apply函数
apply函数是最常用的代替for循环的函数。apply函数可以对矩阵、数据框、数组(二维、多维),按行或列进行循环计算,对子元素进行迭代,并把子元素以参数传递的形式给自定义的FUN函数中,并以返回计算结果。
函数定义:
apply(X, MARGIN, FUN, ...)
参数列表:
- X:数组、矩阵、数据框
- MARGIN: 按行计算或按按列计算,1表示按行,2表示按列
- FUN: 自定义的调用函数
- …: 更多参数,可选
比如,对一个矩阵的每一行求和,下面就要用到apply做循环了。
> x<-matrix(1:12,ncol=3)
> apply(x,1,sum)
[1] 15 18 21 24
下面计算一个稍微复杂点的例子,按行循环,让数据框的x1列加1,并计算出x1,x2列的均值。
# 生成data.frame
> x <- cbind(x1 = 3, x2 = c(4:1, 2:5)); x
x1 x2
[1,] 3 4
[2,] 3 3
[3,] 3 2
[4,] 3 1
[5,] 3 2
[6,] 3 3
[7,] 3 4
[8,] 3 5 # 自定义函数myFUN,第一个参数x为数据
# 第二、三个参数为自定义参数,可以通过apply的'...'进行传入。
> myFUN<- function(x, c1, c2) {
+ c(sum(x[c1],1), mean(x[c2]))
+ } # 把数据框按行做循环,每行分别传递给myFUN函数,设置c1,c2对应myFUN的第二、三个参数
> apply(x,1,myFUN,c1='x1',c2=c('x1','x2'))
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 4.0 4 4.0 4 4.0 4 4.0 4
[2,] 3.5 3 2.5 2 2.5 3 3.5 4
对于上面的需求,还可以这样实现,那就是完成利用了R的特性,通过向量化计算来完成的。
> data.frame(x1=x[,1]+1,x2=rowMeans(x))
x1 x2
1 4 3.5
2 4 3.0
3 4 2.5
4 4 2.0
5 4 2.5
6 4 3.0
7 4 3.5
8 4 4.0
3. lapply函数
lapply函数是一个最基础循环操作函数之一,用来对list、data.frame数据集进行循环,并返回和X长度同样的list结构作为结果集,通过lapply的开头的第一个字母’l’就可以判断返回结果集的类型。
函数定义:
lapply(X, FUN, ...)
参数列表:
- X:list、data.frame数据
- FUN: 自定义的调用函数
- …: 更多参数,可选
比如,计算list中的每个KEY对应该的数据的分位数。
4. sapply函数
sapply函数是一个简化版的lapply,sapply增加了2个参数simplify和USE.NAMES,主要就是让输出看起来更友好,返回值为向量,而不是list对象。
函数定义:
sapply(X, FUN, ..., simplify=TRUE, USE.NAMES = TRUE)
参数列表:
- X:数组、矩阵、数据框
- FUN: 自定义的调用函数
- …: 更多参数,可选
- simplify: 是否数组化,当值array时,输出结果按数组进行分组
- USE.NAMES: 如果X为字符串,TRUE设置字符串为数据名,FALSE不设置
我们还用上面lapply的计算需求进行说明。
如果simplify=FALSE和USE.NAMES=FALSE,那么完全sapply函数就等于lapply函数了。
5. vapply函数
vapply类似于sapply,提供了FUN.VALUE参数,用来控制返回值的行名,这样可以让程序更健壮。
函数定义:
vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)
参数列表:
- X:数组、矩阵、数据框
- FUN: 自定义的调用函数
- FUN.VALUE: 定义返回值的行名row.names
- …: 更多参数,可选
- USE.NAMES: 如果X为字符串,TRUE设置字符串为数据名,FALSE不设置
比如,对数据框的数据进行累计求和,并对每一行设置行名row.names
通过使用vapply可以直接设置返回值的行名,这样子做其实可以节省一行的代码,让代码看起来更顺畅,当然如果不愿意多记一个函数,那么也可以直接忽略它,只用sapply就够了。
6. mapply函数
mapply也是sapply的变形函数,类似多变量的sapply,但是参数定义有些变化。第一参数为自定义的FUN函数,第二个参数’…’可以接收多个数据,作为FUN函数的参数调用。
函数定义:
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE,USE.NAMES = TRUE)
参数列表:
- FUN: 自定义的调用函数
- …: 接收多个数据
- MoreArgs: 参数列表
- SIMPLIFY: 是否数组化,当值array时,输出结果按数组进行分组
- USE.NAMES: 如果X为字符串,TRUE设置字符串为数据名,FALSE不设置
比如,比较3个向量大小,按索引顺序取较大的值。
> set.seed(1) # 定义3个向量
> x<-1:10
> y<-5:-4
> z<-round(runif(10,-5,5)) # 按索引顺序取较大的值。
> mapply(max,x,y,z)
[1] 5 4 3 4 5 6 7 8 9 10
由于mapply是可以接收多个参数的,所以我们在做数据操作的时候,就不需要把数据先合并为data.frame了,直接一次操作就能计算出结果了。
7. tapply函数
tapply用于分组的循环计算,通过INDEX参数可以把数据集X进行分组,相当于group by的操作。
函数定义:
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
参数列表:
- X: 向量
- INDEX: 用于分组的索引
- FUN: 自定义的调用函数
- …: 接收多个数据
- simplify : 是否数组化,当值array时,输出结果按数组进行分组
比如,计算不同品种的鸢尾花的花瓣(iris)长度的均值。
# 通过iris$Species品种进行分组
> tapply(iris$Petal.Length,iris$Species,mean)
setosa versicolor virginica
1.462 4.260 5.552
对向量x和y进行计算,并以向量t为索引进行分组,求和。
> set.seed(1) # 定义x,y向量
> x<-y<-1:10;x;y
[1] 1 2 3 4 5 6 7 8 9 10
[1] 1 2 3 4 5 6 7 8 9 10 # 设置分组索引t
> t<-round(runif(10,1,100)%%2);t
[1] 1 2 2 1 1 2 1 0 1 1 # 对x进行分组求和
> tapply(x,t,sum)
0 1 2
8 36 11
8. rapply函数
rapply是一个递归版本的lapply,它只处理list类型数据,对list的每个元素进行递归遍历,如果list包括子元素则继续遍历。
函数定义:
rapply(object, f, classes = "ANY", deflt = NULL, how = c("unlist", "replace", "list"), ...)
参数列表:
- object:list数据
- f: 自定义的调用函数
- classes : 匹配类型, ANY为所有类型
- deflt: 非匹配类型的默认值
- how: 3种操作方式,当为replace时,则用调用f后的结果替换原list中原来的元素;当为list时,新建一个list,类型匹配调用f函数,不匹配赋值为deflt;当为unlist时,会执行一次unlist(recursive = TRUE)的操作
- …: 更多参数,可选
比如,对一个list的数据进行过滤,把所有数字型numeric的数据进行从小到大的排序。
> x=list(a=12,b=1:4,c=c('b','a'))
> y=pi
> z=data.frame(a=rnorm(10),b=1:10)
> a <- list(x=x,y=y,z=z)
# 进行排序,并替换原list的值
> rapply(a,sort, classes='numeric',how='replace')
$x
$x$a
[1] 12
$x$b
[1] 4 3 2 1
$x$c
[1] "b" "a"
$y
[1] 3.141593
$z
$z$a
[1] -0.8356286 -0.8204684 -0.6264538 -0.3053884 0.1836433 0.3295078
[7] 0.4874291 0.5757814 0.7383247 1.5952808
$z$b
[1] 10 9 8 7 6 5 4 3 2 1
> class(a$z$b)
[1] "integer"
从结果发现,只有$z$a的数据进行了排序,检查$z$b的类型,发现是integer,是不等于numeric的,所以没有进行排序。
9. eapply函数
对一个环境空间中的所有变量进行遍历。如果我们有好的习惯,把自定义的变量都按一定的规则存储到自定义的环境空间中,那么这个函数将会让你的操作变得非常方便
函数定义:
eapply(env, FUN, ..., all.names = FALSE, USE.NAMES = TRUE)
参数列表:
- env: 环境空间
- FUN: 自定义的调用函数
- …: 更多参数,可选
- all.names: 匹配类型, ANY为所有类型
- USE.NAMES: 如果X为字符串,TRUE设置字符串为数据名,FALSE不设置
很少用~
R中apply函数族的更多相关文章
- R语言apply函数族笔记
为什么用apply 因为我是一个程序员,所以在最初学习R的时候,当成“又一门编程语言”来学习,但是怎么学都觉得别扭.现在我的看法倾向于,R不是一种通用型的编程语言,而是一种统计领域的软件工具.因此,不 ...
- R中apply等函数用法[转载]
转自:https://www.cnblogs.com/nanhao/p/6674063.html 1.apply函数——对矩阵 功能是:Retruns a vector or array or lis ...
- 数据操作-apply函数族
R 作为一种向量化的编程语言,一大特征便是以向量计算替代了循环计算,使效率大大提升.apply函数族正是为解决数据循环处理问题而生的 -- 面向不同数据类型,生成不同返回值的包含8个相关函数的函数族. ...
- 【R.转载】apply函数族的使用方法
为什么用apply 因为我是一个程序员,所以在最初学习R的时候,当成"又一门编程语言"来学习,但是怎么学都觉得别扭.现在我的看法倾向于,R不是一种通用型的编程语言,而是一种统计领域 ...
- 掌握R语言中的apply函数族(转)
转自:http://blog.fens.me/r-apply/ 前言 刚开始接触R语言时,会听到各种的R语言使用技巧,其中最重要的一条就是不要用循环,效率特别低,要用向量计算代替循环计算. 那么,这是 ...
- R中的apply族函数和多线程计算
一.apply族函数 1.apply 应用于矩阵和数组 # apply # 1代表行,2代表列 # create a matrix of 10 rows x 2 columns m <- ma ...
- 使用 apply 函数族
之前,我们讨论过可以使用 for 循环,在一个向量或列表上进行迭代,重复执行某个表达式.但是在实践中,for 循环往往是最后的选择,因为每次迭代都是相互独立的,所以我们可以使用更简洁更方便的读写方式来 ...
- R中基本函数学习[转载]
转自:https://www.douban.com/note/511740050/ 1.数据管理 numeric:数值型向量 logical:逻辑型向量 character:字符型向量list:列表 ...
- R中字符串操作
简介 Stringr中包含3个主要的函数族 字符操作 空格处理 模式匹配 常用函数 在平常的数据分析工作中,经常要用到如下的函数 函数 操作 str_length() 获取字符串长度 str_sub( ...
随机推荐
- hdu 1018 Big Number 数学结论
Big Number Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total ...
- 利用yum下载rpm离线包
# 利用yum下载rpm包 ### 简介-----------------------------yum是基于red hat系统的默认包管理器.使用yum可以安装或更新一个rpm包,并且他会自动解决包 ...
- word中特殊符号的替换
首先在word里替换快捷键是ctrl+H,点击“更多”,会出现更多选项,在特殊格式那里可以选在各种符号,比如回车,空格什么的. 有的时候在word里看不到一些格式,需要点一下下图的对着的两个箭头图标: ...
- PHPCMS v9.6.0后台getshell
思路来自于 http://www.cnbraid.com/2016/09/18/phpcms/ 这里自己复现了一下,自己写了一下 因为是后台的,还得登陆两次..所以不好用,主要是学习学习 漏洞来自于R ...
- JAVA转化Unicode编码
package yyl.example.basic.codec; import java.util.Locale; import java.util.regex.Matcher; import jav ...
- 开发高性能的MongoDB应用—浅谈MongoDB性能优化
关联文章索引: 大数据时代的数据存储,非关系型数据库MongoDB 性能与用户量 “如何能让软件拥有更高的性能?”,我想这是一个大部分开发者都思考过的问题.性能往往决定了一个软件的质量,如果你开发的是 ...
- Android ----------------- 面试题 整理 一
1. XML的解析方式都有哪些? 每一种解析方式的运行流程? 设XML为:<a>a<b>bc<c>c1</c></b></a> ...
- 【C++自我精讲】基础系列五 隐式转换和显示转换
[C++自我精讲]基础系列五 隐式转换和显示转换 0 前言 1)C++的类型转换分为两种,一种为隐式转换,另一种为显式转换. 2)C++中应该尽量不要使用转换,尽量使用显式转换来代替隐式转换. 1 隐 ...
- 你的企业是否须要开发APP?
移动互联网时代的到来,粗分出"新兴行业"与"传统行业".除了互联网公司,其它似乎都被归到了"传统行业".连传统行业中最传统的房地产公司代表人 ...
- Chem 3D软件可以改变背景吗
化学绘图过程中常常需要绘制三维结构的图形,Chem 3D软件是ChemOffice套件中专门用于绘制三维结构的组件.用过它的用户会发现,其背景颜色通常都默认为深蓝色,但是不是每个场景都适合用深蓝色的背 ...