距离度量以及python实现(一)
1. 欧氏距离(Euclidean Distance)
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。
(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
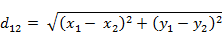
(2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:
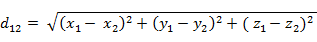
(3)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
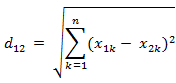
(4)也可以用表示成向量运算的形式:

python中的实现:
方法一:
import numpy as np
x=np.random.random(10)
y=np.random.random(10) #方法一:根据公式求解
d1=np.sqrt(np.sum(np.square(x-y))) #方法二:根据scipy库求解
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
d2=pdist(X)
2. 曼哈顿距离(Manhattan Distance)
从名字就可以猜出这种距离的计算方法了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的来源, 曼哈顿距离也称为城市街区距离(City Block distance)。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离
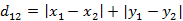
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
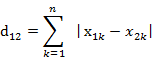
python中的实现 :
import numpy as np
x=np.random.random(10)
y=np.random.random(10) #方法一:根据公式求解
d1=np.sum(np.abs(x-y)) #方法二:根据scipy库求解
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
d2=pdist(X,'cityblock')
3. 切比雪夫距离 ( Chebyshev Distance )
国际象棋玩过么?国王走一步能够移动到相邻的8个方格中的任意一个。那么国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?自己走走试试。你会发现最少步数总是max(
| x2-x1 | , | y2-y1 | ) 步 。有一种类似的一种距离度量方法叫切比雪夫距离。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离
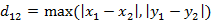
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的切比雪夫距离

这个公式的另一种等价形式是
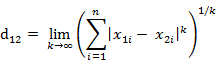
看不出两个公式是等价的?提示一下:试试用放缩法和夹逼法则来证明。
在python中的实现:
import numpy as np
x=np.random.random(10)
y=np.random.random(10) #方法一:根据公式求解
d1=np.max(np.abs(x-y)) #方法二:根据scipy库求解
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
d2=pdist(X,'chebyshev')
4. 闵可夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义。
(1) 闵氏距离的定义
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:

也可写成
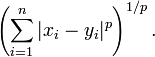
其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
(2)闵氏距离的缺点
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点。
举个例子:二维样本(身高,体重),其中身高范围是150~190,体重范围是50~60,有三个样本:a(180,50),b(190,50),c(180,60)。那么a与b之间的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c之间的闵氏距离,但是身高的10cm真的等价于体重的10kg么?因此用闵氏距离来衡量这些样本间的相似度很有问题。
简单说来,闵氏距离的缺点主要有两个:(1)将各个分量的量纲(scale),也就是“单位”当作相同的看待了。(2)没有考虑各个分量的分布(期望,方差等)可能是不同的。
python中的实现:
import numpy as np
x=np.random.random(10)
y=np.random.random(10) #方法一:根据公式求解,p=2
d1=np.sqrt(np.sum(np.square(x-y))) #方法二:根据scipy库求解
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
d2=pdist(X,'minkowski',p=2)
5. 标准化欧氏距离 (Standardized Euclidean distance )
(1)标准欧氏距离的定义
标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,好吧!那我先将各个分量都“标准化”到均值、方差相等吧。均值和方差标准化到多少呢?这里先复习点统计学知识吧,假设样本集X的均值(mean)为m,标准差(standard
deviation)为s,那么X的“标准化变量”表示为:
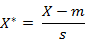
标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:

如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。
python中的实现:
import numpy as np
x=np.random.random(10)
y=np.random.random(10) X=np.vstack([x,y]) #方法一:根据公式求解
sk=np.var(X,axis=0,ddof=1)
d1=np.sqrt(((x - y) ** 2 /sk).sum()) #方法二:根据scipy库求解
from scipy.spatial.distance import pdist
d2=pdist(X,'seuclidean')
6. 马氏距离(Mahalanobis Distance)
(1)马氏距离定义
有M个样本向量X1~Xm,协方差矩阵记为S,均值记为向量μ,则其中样本向量X到u的马氏距离表示为:
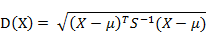
而其中向量Xi与Xj之间的马氏距离定义为:

若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了:
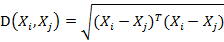
也就是欧氏距离了。
若协方差矩阵是对角矩阵,公式变成了标准化欧氏距离。
python 中的实现:
import numpy as np
x=np.random.random(10)
y=np.random.random(10) #马氏距离要求样本数要大于维数,否则无法求协方差矩阵
#此处进行转置,表示10个样本,每个样本2维
X=np.vstack([x,y])
XT=X.T #方法一:根据公式求解
S=np.cov(X) #两个维度之间协方差矩阵
SI = np.linalg.inv(S) #协方差矩阵的逆矩阵
#马氏距离计算两个样本之间的距离,此处共有10个样本,两两组合,共有45个距离。
n=XT.shape[0]
d1=[]
for i in range(0,n):
for j in range(i+1,n):
delta=XT[i]-XT[j]
d=np.sqrt(np.dot(np.dot(delta,SI),delta.T))
d1.append(d) #方法二:根据scipy库求解
from scipy.spatial.distance import pdist
d2=pdist(XT,'mahalanobis')
马氏优缺点:
1)马氏距离的计算是建立在总体样本的基础上的,这一点可以从上述协方差矩阵的解释中可以得出,也就是说,如果拿同样的两个样本,放入两个不同的总体中,最后计算得出的两个样本间的马氏距离通常是不相同的,除非这两个总体的协方差矩阵碰巧相同;
2)在计算马氏距离过程中,要求总体样本数大于样本的维数,否则得到的总体样本协方差矩阵逆矩阵不存在,这种情况下,用欧式距离计算即可。
3)还有一种情况,满足了条件总体样本数大于样本的维数,但是协方差矩阵的逆矩阵仍然不存在,比如三个样本点(3,4),(5,6)和(7,8),这种情况是因为这三个样本在其所处的二维空间平面内共线。这种情况下,也采用欧式距离计算。
4)在实际应用中“总体样本数大于样本的维数”这个条件是很容易满足的,而所有样本点出现3)中所描述的情况是很少出现的,所以在绝大多数情况下,马氏距离是可以顺利计算的,但是马氏距离的计算是不稳定的,不稳定的来源是协方差矩阵,这也是马氏距离与欧式距离的最大差异之处。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关;由标准化数据和中心化数据(即原始数据与均值之差)计算出的二点之间的马氏距离相同。马氏距离还可以排除变量之间的相关性的干扰。缺点:它的缺点是夸大了变化微小的变量的作用。
参考:
http://www.cnblogs.com/daniel-D/p/3244718.html
http://www.cnblogs.com/likai198981/p/3167928.html
距离度量以及python实现(一)的更多相关文章
- 概率分布之间的距离度量以及python实现(四)
1.f 散度(f-divergence) KL-divergence 的坏处在于它是无界的.事实上KL-divergence 属于更广泛的 f-divergence 中的一种. 如果P和Q被定义成空间 ...
- 概率分布之间的距离度量以及python实现(三)
概率分布之间的距离,顾名思义,度量两组样本分布之间的距离 . 1.卡方检验 统计学上的χ2统计量,由于它最初是由英国统计学家Karl Pearson在1900年首次提出的,因此也称之为Pearson ...
- 概率分布之间的距离度量以及python实现
1. 欧氏距离(Euclidean Distance) 欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式.(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧 ...
- 距离度量以及python实现(二)
接上一篇:http://www.cnblogs.com/denny402/p/7027954.html 7. 夹角余弦(Cosine) 也可以叫余弦相似度. 几何中夹角余弦可用来衡量两个向量方向的差异 ...
- ML 07、机器学习中的距离度量
机器学习算法 原理.实现与实践 —— 距离的度量 声明:本篇文章内容大部分转载于July于CSDN的文章:从K近邻算法.距离度量谈到KD树.SIFT+BBF算法,对内容格式与公式进行了重新整理.同时, ...
- 海量数据挖掘MMDS week2: LSH的距离度量方法
http://blog.csdn.net/pipisorry/article/details/48882167 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- Mahout系列之----距离度量
x = (x1,...,xn) 和y = (y1,...,yn) 之间的距离为 (1)欧氏距离 EuclideanDistanceMeasure (2)曼哈顿距离 ManhattanDis ...
- 机器学习方法、距离度量、K_Means
特征向量 1.特征向量:以人为例,每个元素可能就对应这人的某些方面,这就是特征,例如:身高.年龄.性别.国际....2.特征工程:目的就是将现有数据中可作为信号的特征与那些仅是噪声的特征区分开来:当数 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
随机推荐
- driver匹配元素定位用法大全
# -*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.common.by import By fr ...
- Oracle 启动监听命令
win10系统,在win右击"运行"-->输入"services.msc" ,来到服务窗口,找Oracle的相关服务 OracleOraDb10g_hom ...
- 在MFC中对Excel的一些操作
首先要在程序中加载CExcel.h和CExcel.cpp文件,这里面包装了很多函数和对Excel文件的操作,下面所有程序中的m_excel都是类CExcel的对象,如: private: _Appli ...
- BZOJ_3993_[SDOI2015]星际战争_二分+网络流
BZOJ_3993_[SDOI2015]星际战争_二分+网络流 Description 3333年,在银河系的某星球上,X军团和Y军团正在激烈地作战.在战斗的某一阶段,Y军团一共派遣了N个巨型机器人进 ...
- 通过jQuery和C#分别实现对.NET Core Web Api的访问以及文件上传
准备工作: 建立.NET Core Web Api项目 新建一个用于Api请求的UserInfo类 public class UserInfo { public string name { get; ...
- CountDownLatch和CyclicBarrier 区别
CountDownLatch : 一个线程(或者多个), 等待另外N个线程完成某个事情之后才能执行. CyclicBarrier : N个线程相互等待,任何一个线程完成之前,所有的线程都 ...
- Windbg分析高内存占用问题
1. 问题简介 最近产品发布大版本补丁更新,一商超客户升级后,反馈系统经常奔溃,导致超市的收银系统无法正常收银,现场排队付款的顾客更是抱怨声声.为了缓解现场的情况, 客户都是手动回收IIS应用程序池才 ...
- window.history.back(-1);与window.go(-1);的区别
history.back(-1):直接返回当前页的上一页,数据全部消息,是个新页面 history.go(-1):也是返回当前页的上一页,不过表单里的数据全部还在 history.back(1) 前进 ...
- 跟我一起学opencv 第四课之图像的基本操作
1.图像是由像素组成的,所以修改了像素就可以实现图像的改变. 2先看灰度图像(单通道): *****2.获取灰度图像的像素值使用: int gray = gray_src.at<uchar&g ...
- Android版数据结构与算法(二):基于数组的实现ArrayList源码彻底分析
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 本片我们分析基础数组的实现--ArrayList,不会分析整个集合的继承体系,这不是本系列文章重点. 源码分析都是基于"安卓版" ...