HanLP用户自定义词典源码分析
HanLP用户自定义词典源码分析
1. 官方文档及参考链接
关于词典问题Issue,首先参考:FAQ
自定义词典其实是基于规则的分词,它的用法参考这个issue
如果有些数量词、字母词需要分词,可参考:P2P和C2C这种词没有分出来,希望加到主词库
关于词性标注:可参考词性标注
2. 源码解析
分析 com.hankcs.demo包下的DemoCustomDictionary.java 基于自定义词典使用标准分词HanLP.segment(text)的大致流程(HanLP版本1.5.3)。首先把自定义词添加到词库中:
CustomDictionary.add("攻城狮");
CustomDictionary.insert("白富美", "nz 1024");//指定了自定义词的词性和词频
CustomDictionary.add("单身狗", "nz 1024 n 1")//一个词可以有多个词性
添加词库的过程包括:
若启用了归一化
HanLP.Config.Normalization = true;,则会将自定义词进行归一化操作。归一化操作是基于词典文件 CharTable.txt 进行的。判断自定义词是否存在于自定义核心词典中
public static boolean add(String word)
{
if (HanLP.Config.Normalization) word = CharTable.convert(word);
if (contains(word)) return false;//判断DoubleArrayTrie和BinTrie是否已经存在word
return insert(word, null);
}
- 当自定义词不在词典中时,构造一个CoreDictionary.Attribute对象,若添加的自定义词未指定词性和词频,则词性默认为 nz,频次为1。然后试图使用DAT树将该 Attribute对象添加到核心词典中,由于自定义的词未存在于核心词典中,因为会添加失败,从而将自定义词放入到BinTrie中。因此,不在核心自定义词典中的词(动态增删的那些词语)是使用BinTrie树保存的。
public static boolean insert(String word, String natureWithFrequency)
{
if (word == null) return false;
if (HanLP.Config.Normalization) word = CharTable.convert(word);
CoreDictionary.Attribute att = natureWithFrequency == null ? new CoreDictionary.Attribute(Nature.nz, 1) : CoreDictionary.Attribute.create(natureWithFrequency);
if (att == null) return false;
if (dat.set(word, att)) return true;
//"攻城狮"是动态加入的词语. 在核心词典中未匹配到,在自定义词典中也未匹配到, 动态增删的词语使用BinTrie保存
if (trie == null) trie = new BinTrie<CoreDictionary.Attribute>();
trie.put(word, att);
return true;
}
将自定义添加到BinTrie树后,接下来是使用分词算法分词了。假设使用的标准分词(viterbi算法来分词):
List<Vertex> vertexList = viterbi(wordNetAll);
分词具体过程可参考:
分词完成之后,返回的是一个 Vertex 列表。如下图所示:
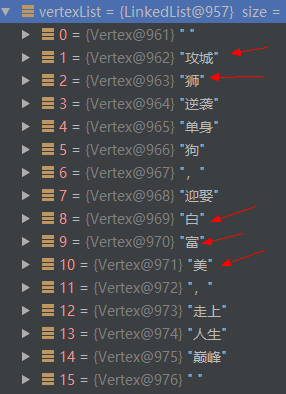
然后根据 是否开启用户自定义词典 配置来决定将分词结果与用户添加的自定义词进行合并。默认情况下,config.useCustomDictionary是true,即开启用户自定义词典。
if (config.useCustomDictionary)
{
if (config.indexMode > 0)
combineByCustomDictionary(vertexList, wordNetAll);
else combineByCustomDictionary(vertexList);
}
combineByCustomDictionary(vertexList)由两个过程组成:
合并DAT 树中的用户自定义词。这些词是从 词典配置文件 CustomDictionary.txt 中加载得到的。
合并BinTrie 树中的用户自定义词。这些词是 代码中动态添加的:
CustomDictionary.add("攻城狮")
//DAT合并
DoubleArrayTrie<CoreDictionary.Attribute> dat = CustomDictionary.dat;
....
// BinTrie合并
if (CustomDictionary.trie != null)//用户通过CustomDictionary.add("攻城狮"); 动态增加了词典
{
....
合并之后的结果如下:
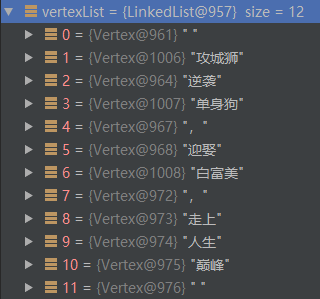
3. 关于用户自定义词典
总结一下,开启自定义分词的流程基本如下:
- HanLP启动时加载词典文件中的CustomDictionary.txt 到DoubleArrayTrie中;用户通过
CustomDictionary.add("攻城狮");将自定义词添加到BinTrie中。 - 使用某一种分词算法分词
- 将分词结果与DoubleArrayTrie或BinTrie中的自定义词进行合并,最终返回输出结果
HanLP作者在HanLP issue783:上面说:词典不等于分词、分词不等于自然语言处理;推荐使用语料而不是词典去修正统计模型。由于分词算法不能将一些“特定领域”的句子分词正确,于是为了纠正分词结果,把想要的分词结果添加到自定义词库中,但最好使用语料来纠正分词的结果。另外,作者还说了在以后版本中不保证继续支持动态添加自定义词典。以上是阅读源码过程中的一些粗浅理解,仅供参考。
原文:http://www.cnblogs.com/hapjin/p/8992280.html
HanLP用户自定义词典源码分析的更多相关文章
- HanLP用户自定义词典源码分析详解
1. 官方文档及参考链接 l 关于词典问题Issue,首先参考:FAQ l 自定义词典其实是基于规则的分词,它的用法参考这个issue l 如果有些数量词.字母词需要分词,可参考:P2P和C2C这种词 ...
- [源码分析] 分布式任务队列 Celery 之 发送Task & AMQP
[源码分析] 分布式任务队列 Celery 之 发送Task & AMQP 目录 [源码分析] 分布式任务队列 Celery 之 发送Task & AMQP 0x00 摘要 0x01 ...
- 深入理解 spring 容器,源码分析加载过程
Spring框架提供了构建Web应用程序的全功能MVC模块,叫Spring MVC,通过Spring Core+Spring MVC即可搭建一套稳定的Java Web项目.本文通过Spring MVC ...
- 【集合框架】JDK1.8源码分析之TreeMap(五)
一.前言 当我们需要把插入的元素进行排序的时候,就是时候考虑TreeMap了,从名字上来看,TreeMap肯定是和树是脱不了干系的,它是一个排序了的Map,下面我们来着重分析其源码,理解其底层如何实现 ...
- 【JUC】JDK1.8源码分析之ThreadPoolExecutor(一)
一.前言 JUC这部分还有线程池这一块没有分析,需要抓紧时间分析,下面开始ThreadPoolExecutor,其是线程池的基础,分析完了这个类会简化之后的分析,线程池可以解决两个不同问题:由于减少了 ...
- 【Pig源码分析】谈谈Pig的数据模型
1. 数据模型 Schema Pig Latin表达式操作的是relation,FILTER.FOREACH.GROUP.SPLIT等关系操作符所操作的relation就是bag,bag为tuple的 ...
- Struts2 源码分析——过滤器(Filter)
章节简言 上一章笔者试着建一个Hello world的例子.是一个空白的struts2例子.明白了运行struts2至少需要用到哪一些Jar包.而这一章笔者将根据前面章节(Struts2 源码分析—— ...
- Orchard源码分析(1):Orchard架构
本文主要参考官方文档"How Orchard works"以及Orchardch上的翻译. 源码分析应该做到庖丁解牛,而不是以管窥豹或瞎子摸象.所以先对Orchard架构有 ...
- Mahout源码分析之 -- 文档向量化TF-IDF
fesh个人实践,欢迎经验交流!Blog地址:http://www.cnblogs.com/fesh/p/3775429.html Mahout之SparseVectorsFromSequenceFi ...
随机推荐
- python活用isdigit方法显示系统进程
如何利用字符串的内置函数isdigit(),判断一个字符串是一个纯数字.如果是纯数字会返回True,否则返回fasle. 利用isdigit()方法编写一个python脚本显示所有系统进程pid.os ...
- 如何改变Android标准键的颜色?
本文选自StackOverflow(简称:SOF)精选问答汇总系列文章之一,本系列文章将为读者分享国外最优质的精彩问与答,供读者学习和了解国外最新技术,本文为大家讲解如何改变Android标准键的颜色 ...
- 【Luogu2664】树上游戏(点分治)
[Luogu2664]树上游戏(点分治) 题面 洛谷 题解 很好的一道点分治题. 首先直接点分治,考虑过每个分治重心的链的贡献. 我们从分治重心开始找每种颜色,强制令一种颜色只在其到分治重心的链上第一 ...
- POJ2411 铺地砖 Mondriaan's Dream
Mondriaan's Dream Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 15962 Accepted: 923 ...
- cf1000F One Occurrence (线段树)
这题我是离线做的 设i位置的数上次出现的位置是pre[i](如果第一次出现那就是0) 可以想到,用线段树维护一个区间的pre的最小值,如果它小于区间左端点,那这个数就是一个合法的答案 但直接这样做是错 ...
- angularjs优化方略
angular优化方略,闲的没事想重构的人来瞅瞅. 1.减少$watch 减少$watch,减少$watch,减少$watch.不仅仅是$watch监听,还有ng-model,别闲的没事就加个ng-m ...
- 编写高质量代码:改善Java程序的151个建议 --[0~25]
警惕自增的陷阱 public class Client7 { public static void main(String[] args) { int count=0; for(int i=0; i& ...
- [WC2019] 数树
[WC2019] 数树 Zhang_RQ题解(本篇仅概述) 前言 有进步,只做了半天.... 一道具有极强综合性的数数好题! 强大的多合一题目 精确地数学推导和耐心. 有套路又不失心意. 融合了: 算 ...
- 【P2303】Longge的问题
题目大意:求\[\sum\limits_{i=1}^ngcd(n,i)\] 题解:发现 gcd 中有很多是重复的,因此考虑枚举 gcd. \[\sum\limits_{i=1}^ngcd(n,i)=\ ...
- HTTPS笔记:使用 SSLEngine 为 aioserver 服务器提供 SSL 访问支持
现在 HTTPS 的普及率是越来越高,闲来无事,花了二三天时间,为五年前写的 aioserver 服务器提供了 SSL 访问支持. 查看网上资料,为了提高服务器的高并发,建议使用:SSLEngine ...