Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据
1.豆瓣地址:https://movie.douban.com/top250?start=25&filter=
2.主要流程是抓取该网址下的Top250的数据,存入本地的txt文件中,并将数据持久化写入数据库中
环境准备:
1.本地安装mysql数据库,具体下载以及安装参照:https://blog.csdn.net/chic_data/article/details/72286329
2.安装好数据后创建database和table,并创建字段
如:我安装的版本是mysqlV8.0
CREATE TABLE doubanTop250(
ID int PRIMARY KEY AUTO_INCREMENT,
rankey int,
name varchar(50),
alias varchar(100),
director varchar(50),
showYear varchar(50),
makeCountry varchar(50),
movieType varchar(50),
movieScore float,
scoreNum int,
shortFilm varchar(255)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
最后我们直接来看代码:
from urllib import request
import re
import pymysql
class MovieTop(object):
def __init__(self):
self.start = 0
self.param = '&filter'
self.headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/65.0.3325.146 Safari/537.36"}
self.movieList = []
self.filePath = './DoubanTop250.txt' def get_page(self):
try:
url = 'https://movie.douban.com/top250?start=' + str(self.start) + '&filter='
myRequest = request.Request(url, headers=self.headers)
response = request.urlopen(myRequest)
page = response.read().decode('utf-8')
print('正在获取第' + str((self.start+25)//25) + '页数据...')
self.start += 25
return page
except request.URLError as e:
if hasattr(e, 'reason'):
print('获取失败,失败原因:', e.reason) def get_page_info(self):
patern = re.compile(u'<div.*?class="item">.*?'
+ u'<div.*?class="pic">.*?'
+ u'<em.*?class="">(.*?)</em>.*?'
+ u'<div.*?class="info">.*?'
+ u'<span.*?class="title">(.*?)</span>.*?'
+ u'<span.*?class="other">(.*?)</span>.*?'
+ u'<div.*?class="bd">.*?'
+ u'<p.*?class="">.*?'
+ u'导演:\s(.*?)\s.*?<br>'
+ u'(.*?) / '
+ u'(.*?) / (.*?)</p>.*?'
+ u'<div.*?class="star">.*?'
+ u'<span.*?class="rating_num".*?property="v:average">'
+ u'(.*?)</span>.*?'
+ u'<span>(.*?)人评价</span>.*?'
+ u'<span.*?class="inq">(.*?)</span>'
, re.S) while self.start <= 225:
page = self.get_page()
movies = re.findall(patern, page)
for movie in movies:
self.movieList.append([movie[0],
movie[1],
movie[2].lstrip(' / '),
movie[3],
movie[4].lstrip(),
movie[5],
movie[6].rstrip(),
movie[7],
movie[8],
movie[9]]) def write_page(self):
print('开始写入文件...')
file = open(self.filePath, 'w', encoding='utf-8')
try:
for movie in self.movieList:
file.write('电影排名:' + movie[0] + '\n')
file.write('电影名称:' + movie[1] + '\n')
file.write('电影别名:' + movie[2] + '\n')
file.write('导演:' + movie[3] + '\n')
file.write('上映年份:' + movie[4] + '\n')
file.write('制作国家/地区:' + movie[5] + '\n')
file.write('电影类别:' + movie[6] + '\n')
file.write('评分:' + movie[7] + '\n')
file.write('参评人数:' + movie[8] + '\n')
file.write('简短影评:' + movie[9] + '\n')
file.write('\n')
print('成功写入文件...')
except Exception as e:
print(e)
finally:
file.close() def upload(self):
db = pymysql.connect("localhost", "root", "root", "PythonTest", charset='utf8')
cursor = db.cursor() insertStr = "INSERT INTO doubanTop250(rankey, name, alias, director," \
"showYear, makeCountry, movieType, movieScore, scoreNum, shortFilm)" \
"VALUES (%d, '%s', '%s', '%s', '%s', '%s', '%s', %f, %d, '%s')" try:
for movie in self.movieList:
insertSQL = insertStr % (int(movie[0]), str(movie[1]), str(movie[2]), str(movie[3]),
str(movie[4]), str(movie[5]), str(movie[6]), float(movie[7]),
int(movie[8]), str(movie[9]))
cursor.execute(insertSQL)
db.commit()
print('成功上传至数据库...')
except Exception as e:
print(e)
db.rollback()
finally:
db.close() if __name__ == '__main__':
mt = MovieTop()
mt.get_page_info()
mt.write_page()
mt.upload()
执行结果: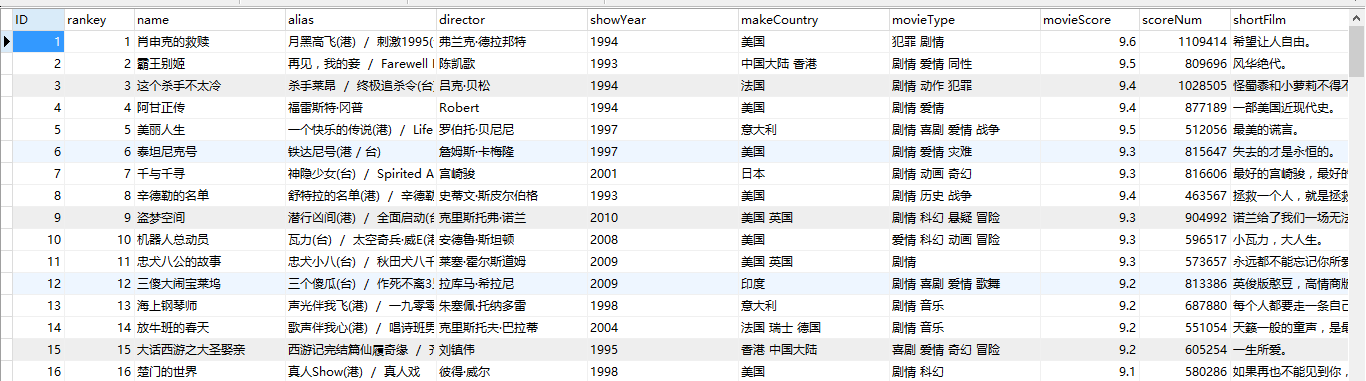
参照原文地址:https://www.cnblogs.com/AlvinZH/p/8576841.html#_label0
Python小爬虫——抓取豆瓣电影Top250数据的更多相关文章
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- python2.7抓取豆瓣电影top250
利用python2.7抓取豆瓣电影top250 1.任务说明 抓取top100电影名称 依次打印输出 2.网页解析 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用 ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- Python3 抓取豆瓣电影Top250
利用 requests 抓取豆瓣电影 Top 250: import re import requests def main(url): global num headers = {"Use ...
- scrapy抓取豆瓣电影相关数据
1. 任务分析及说明 目标网站:https://movie.douban.com/tag/#/ 抓取豆瓣电影上,中国大陆地区,相关电影数据约1000条:数据包括:电影名称.导演.主演.评分.电影类型. ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
随机推荐
- sublime插件不能使用,提示plugin_host has exited unexpectedly
sublime Text3一打开软件就提示plugin_host has exited unexpectedly,插件不能使用 解决方法很简单: 1.首先,ctrl + shift + p --&g ...
- 美团2016秋招笔试B
1.下述解决死锁的方法中,属于死锁预防策略的是? 资源有序分配法 银行家算法:避免死锁 资源有序分配法:预防死锁 资源分配图化简法:检测死锁 撤销进程法:解决死锁 2. 什么是死锁? 如果一个进 ...
- python中读取文件的read、readline、readlines方法区别
#读取文件所有内容,返回字符串对象,python默认以文本方式读取文件,遇到结束符读取结束. fr = open('lenses.txt')read = fr.read()print(type(rea ...
- mybatis配置文件配错
UG] 2017-10-04 20:04:30,582(137226) --> [http-bio-8082-exec-9] org.springframework.web.servlet.ha ...
- 抽象代数-p22商群
G/e={g{e}|g∈G}={{g}|g∈G}=G G/G={gG|g∈G}={G} (gG=G左乘g是G上的双射,它的逆映射是左乘g^-1) 所以 G/G 只有一个元素,所有G 就只能是 ...
- 现代程序设计 homework-10
经过大半学期的学习和练习, 我们把学到的东西综合起来. 通过<现代程序设计>这门课,自己的确学到了好多东西.其实并不是说讲课有多棒,一是因为讲课的次数其实并不多,二是讲课的内容其实感觉并没 ...
- MySQL 高可用性—keepalived+mysql双主
MySQL 高可用性—keepalived+mysql双主(有详细步骤和全部配置项解释) - 我的博客 - CSDN博客https://blog.csdn.net/qq_36276335/articl ...
- linux下编译tex,bib成pdf文件
参考linux下编译bib.tex生成pdf文件 为了编译出出正确的pdf文件,需要执行4条命令完成整个编译过程. 编译命令及输出 $ pdflatex bb.tex #目录下会生成bb.aux.bb ...
- Prime Permutation
Prime Permutation 原题地址: http://codeforces.com/problemset/problem/123/A 题目大意: 给你一个字符串(只包含小写字母),从1开始存放 ...
- hive权限配置
基于CDH5.x的Hive权限配置 1.打开权限控制,默认是没有限制的 set hive.security.authorization.enabled=true; 2.配置默认权限 hive.secu ...