HashMap源码个人解读
HashMap的源码比较复杂,最近也是结合视频以及其余大佬的博客,想着记录一下自己的理解或者当作笔记
JDK1.8后,HashMap底层是数组+链表+红黑树。在这之前都是数组+链表,而改变的原因也就是如果链表过长,查询的效率就会降低,因此引入了红黑树。
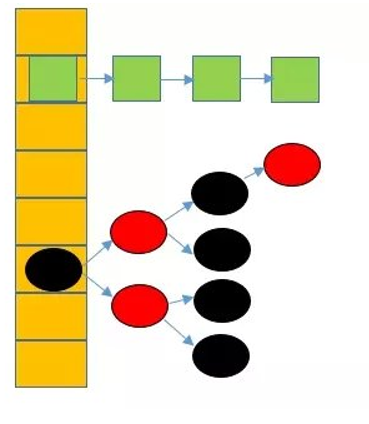
这里的链表是一个单向链表
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
接下来是类的属性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16默认的初始容量是16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;//负载因子
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;//树化阈值
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;//树降级成为链表的阈值
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;//桶中的结构转化为红黑树对应的table,也就是桶的最小数量。
transient Node<K,V>[] table;//存放元素的数组,总是2的幂次方
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;存放具体元素的集
/**
* The number of key-value mappings contained in this map.
*/
transient int size;存放元素的个数,不是数组的长度
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;//每次扩容和更改map结构的计数器
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;//临界值,当实际大小(容量*负载因子)超过临界值时,会进行扩容
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;//负载因子
构造方法中将两个参数的构造方法
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)//初始容量不能小于0,否则报错
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)//初始容量不能大于最大值,否则为最大值
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))//负载因子不能小于或者等于0,不能为非数字
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;//初始化填充因子
this.threshold = tableSizeFor(initialCapacity);//初始化threshold大小
}
tableSizeFor(initialCapacity)这个方法的作用就是返回大于等于initialCapacity的最小的二的次方数。注意是最小
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;//0b1001
n |= n >>> 1;//1001 | 0100 = 1101
n |= n >>> 2;//1101 | 0011 = 1111
n |= n >>> 4;//1111 | 0000 = 1111
n |= n >>> 8;
n |= n >>> 16;//那么后面这两步就得到的结果还是1111。
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;//1111就是15.加1等于16
}
加色cap等于10,那么n = 10-1 = 9。n转化为二进制的话,就是0b1001。那么无符号右移一位,就是0100。
这里cap-1的操作就是为了保证最后得到的n是最小的大于等于initialCapacity的二的次方数。比如这里比10大的2的次方数就是16。如果没有减1.经过上述多次右移和或运算之后,得到的就不是16了。而是32。就不是最小的了。就变成了2倍了。
接下来分析put方法。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
首先研究hash(key)这个方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个就叫扰动函数,他让hash值得高16位与第16位进行异或处理。这样可以减少碰撞。采用位运算也是因为这样更高效。并且当数组的长度很短时,只有低位数的hashcode值能参与运算。而让高16位参与运算可以更好的均匀散列,减少碰撞,进一步降低hash冲突的几率。并且使得高16位和低16位的信息都被保留了。
然后讲述putVal方法,执行过程可以用下面图来理解:
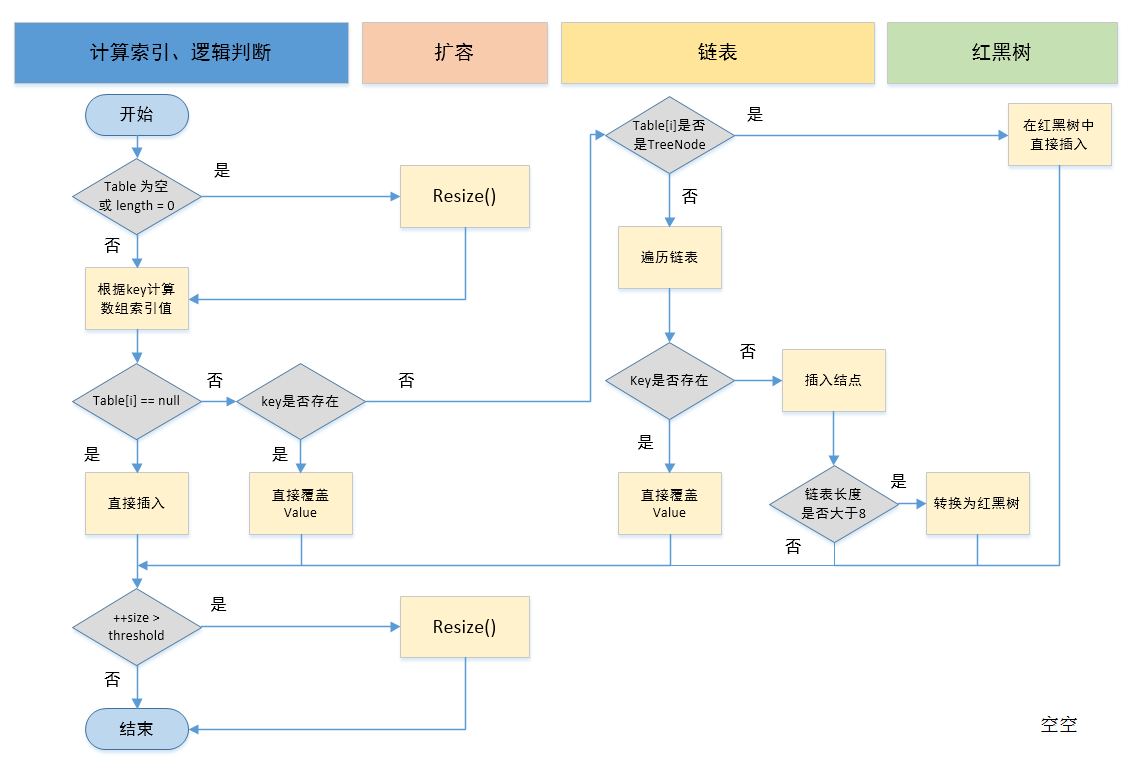
1.判断数组table是否为空或者位null,否则执行resize()进行扩容;
2.根据键值key计算数组hash值得到插入的数组索引i,如果table[i]==null,那么就可以直接新建节点添加到该处。转向6,如果不为空,转向3
3.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向4,这里的相同指的是hashCode以及equals;
4.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向5;
5.遍历table[i],判断链表长度是否大于8(且),大于8的话(且Node数组的数量大于64)把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
6.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
————————————————
版权声明:本文为CSDN博主「钱多多_qdd」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/moneywenxue/article/details/110457302
源码如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//定义了辅助变量tab:引用当前hashMap的散列表;p:表示当前散列表的元素,n:表示散列表数组的长度 i:表示路由寻址结果
//这里是延迟初始化逻辑,第一次调用putVal时会初始化hashMap对象中的最耗内存的散列表
// 步骤1
if ((tab = table) == null || (n = tab.length) == 0)//table就是Hash,table就是HashMap的一个数组,类型是Node[],这里说明散列表还没创建出来
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//n在上面已经赋值了。这是步骤2。 tab[i = (n - 1) & hash])这一块就是路由算法,赋予p所在table数组的位置,并把这个位置的对象,赋给p,如果这个位置的节点位null,那么表示这个位置还没存放元素。
tab[i] = newNode(hash, key, value, null);就在该位置创建一个新节点,这个新节点封装了key value
else {//桶中这个位置有元素了
Node<K,V> e; K k;//步骤3
if (p.hash == hash &&//如果当前索引位置对应的元素和准备添加的key的hash值一样
((k = p.key) == key || (key != null && key.equals(k))))并且满足准备加入的key和该位置的key是同一个对象,那么后续就会进行替换操作。
e = p;
else if (p instanceof TreeNode)//步骤4.判断该链是否是红黑树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);如果是,则放入该树中
else {//步骤5 该链为链表 使用尾插法插入数据
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//桶的位置的next为e,如果e为null,在for的循环中就说明没有找到一样的key的位置,那么久加入末尾
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st加入后判断是否会树化
treeifyBin(tab, hash);
break;//然后跳出
}
if (e.hash == hash &&//这种情况就是找到了一个key以及hash都一样了,那么久要进行替换。
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;//这是循环用的,与前面的e=p.next组合,可以遍历链表。
}
}
if (e != null) { // existing mapping for key//这里就是替换操作,表示在桶中找到key值,hash值与插入元素相等的节点
V oldValue = e.value;//记录e的value
if (!onlyIfAbsent || oldValue == null)
e.value = value;//用心智替换旧值,
afterNodeAccess(e);//访问后回调
return oldValue;//返回旧值
}
}
++modCount;//结构性修改
if (++size > threshold)//步骤6,如果超过最大容量就扩容。
resize();
afterNodeInsertion(evict);//插入后回调
return null;
}
总结一下流程:1根据key计算得到key.hash = (h = k.hashCode())^(h>>>16);
2.根据key.hash计算得到桶数组中的索引,其路由算法就是index = key.hash &(table.length-1),就是哈希值与桶的长度-1做与操作,这样就可以找到该key的位置
2.1如果该位置没有数据,那正好,直接生成新节点存入该数据
2.2如果该位置有数据,且是一个红黑树,那么执行相应的插入/更新操作;
2.3如果该位置有数据,且是一个链表,如果该链表有这个数据,那么就找到这个点并且更新这个数据。如果没有,则采用尾插法插入链表中。
接下来讲解最重要的resize()方法。
扩容的目的就是为了解决哈希冲突导致的链化影响查询效率的问题。扩容可以缓解。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab引用扩容前的哈希表
////oldCap表示扩容之前table数组的长度
//oldTab==null就是第一次new HashMap()的时候,那时候还没有放值,数组就是null。那么初始化的时候
//也要扩容。这句就是如果旧的容量为null的话,那么oldCap是0,否则就是oldTab的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;//表示扩容之前的扩容阈值,也就是触发本次扩容的阈值
//newCap:扩容之后table数组的大小
//newThr:扩容之后,下次再次触发扩容的条件
int newCap, newThr = 0;
if (oldCap > 0) {//条件如果成立,那么就是代表hashMap中的散列表已经初始化过了,这是一次正常的扩容
if (oldCap >= MAXIMUM_CAPACITY) {//扩容之前的table数组大小已经达到最大阈值后,则不扩容,且设置扩容条件为int最大值,这种情况非常少数
threshold = Integer.MAX_VALUE;
return oldTab;
}
//oldCap左移一位实现数值翻倍,并且赋值给newCap,newCap小于数组最大值限制 且 扩容之前的阈值>=16
* //这种情况下,则下一位扩容的阈值等于当前阈值翻倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold这里阈值翻倍也可以理解,如果原先table是16长度,那么oldThr就是16*0.75=12;那么oldCap翻倍的时候,那么新的阈值就是2*16*0.75 = 24;
}
//这是oldCap==0的第一种情况,说明hashMap中的散列表是null
//哪些情况下散列表为null,但是阈值却大于零呢
//1.new HashMap(initCap,loadFactor);
//2.new HashMap(initial);
//3.new HashMap(map);并且这个map有数据,着三种情况下oldThr是有值得
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { 这是oldCap==0,oldThr==0的情况,是new HashMap();的时候// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;//16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//12
}
if (newThr == 0) {//newThr为0时,通过newCap和loadFactor计算出一个newThr
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//接下来才是真正扩容,
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//创建一个大小为newCap的新的数组
table = newTab;//把新的数组赋值给table
if (oldTab != null) {//说明hashmap本次扩容之前,table不为null
for (int j = 0; j < oldCap; ++j) {//将旧数组中的所有数据都要处理,所以来个循环
Node<K,V> e;//当前node节点
if ((e = oldTab[j]) != null) {//说明当前桶位中有数据,但是数据具体是单个数据,还是链表还是红黑树并不知道
oldTab[j] = null;//将旧的数组的这个点置空,用于方便VM GC时回收内存
if (e.next == null)//如果当前的下一个不为空,也就是在桶位中是单个数据,
newTab[e.hash & (newCap - 1)] = e;//那么根据路由算法e的hash与上新的table的长度-1,得到索引,然后该索引放入e这个单个数据
else if (e instanceof TreeNode)//第二种情况,当前节点已经树化。
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order//第三种情况,链表的时候,图可看下,
//低位链表:存放在扩容之后的数组的下标位置,与当前数组的下标位置一致
Node<K,V> loHead = null, loTail = null;
//高位链表:存放在扩容之后的数组的下标位置为当前数组下标位置+扩容之前数组的长度。可见下方解释。
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {//这里是判断节点应该在高链还是低链。
next = e.next;
//假如oldCap = 16,那么就是0b10000
//假如hash为 .....1 1111.前面的不用看,就看着五位
//或者hash为 .....0 1111.
那么与上 000000.. 1 0000.前面都是0。所以与完之后,如果为0,那么就是下面这种.....0 1111,就代表应该在低位链。
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {否则就是高位链。
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);//这里是循环链表,完成所有的分配
if (loTail != null) {//如果原先旧数组中的链表中低位链后面不为null,也就是后面是高位链的。复制到新的数组中就要置为null。
loTail.next = null;
newTab[j] = loHead;//然后把这个低链表的头节点放到新的数组中的索引位置。这样低位链的这个节点,就到了新的数组的地方了
}
if (hiTail != null) {//同理
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
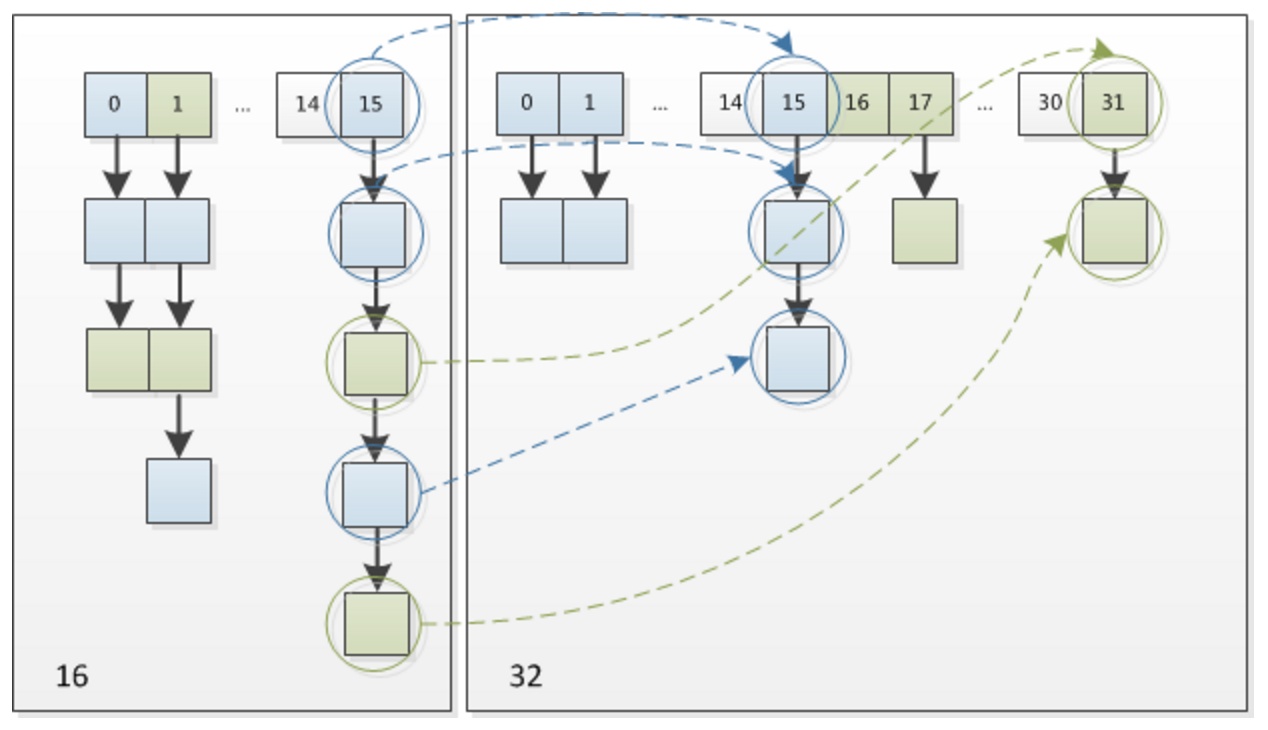
从下图可以看出上面扩容的第三种情况,链表的情况。在第15这个桶位的时候,为啥扩容到32的长度的时候,有的链表节点还在15,而有一些却到31处了。因为旧数组中的索引15是根据路由算法算出来的,
公式为hash&(table.length-1),此时索引为15,那么就是hash&(table.length-1) =15.又因为table.length-1=15,也就是1111,那么hash的低四位肯定就知道了,也是1111,但是第五位就不知道了有可能是1有可能
是0,也就是11111或者01111.那么在新的数组中求索引的时候,根据路由算法,此时新的数组长度为32,那么32-1=31,也就是11111那么旧数组中的数如果是11111,那么算出来就是11111,就是在新数组
31的位置上,如果是01111,那么与之后就是01111。就还是15。别的位置也是这样,如果是原索引为1的地方,那么有可能到新数组的17的位置,就是1+16=17;不是都是加16;而是加这个旧数组的长度。
接下来是get()方法;
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;//这里hash(key)的原因是因为存的时候,hash了一下,那么取的时候,肯定的要取他的hash值一样的。
}
所以主要是getNode方法:
final Node<K,V> getNode(int hash, Object key) {
////tab:引用当前hashMap的散列表
//first:桶位中的头元素
//e:临时node元素
//n:table数组长度
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 && //(tab = table) != null&& (n = tab.length) > 0表示散列表不为空,这样才能取到值,要不然没有水的水池不可能取到水。
(first = tab[(n - 1) & hash]) != null) {//这个代表在这个索引的位置的头节点不为null。也就是这个地方有数据。
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;//如果头元素就是正好要找的数据,那么直接返回头元素
if ((e = first.next) != null) {//如果这个桶的索引处不是单个数据,那么就进一步查找,如果是单个元素,那么下面不执行,直接返回null,因为没有找到
if (first instanceof TreeNode)//如果是树,那么就去找
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {//桶位这里所在的节点是链表
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;//如果找到一样的e,那么就返回,否则就一直循环,到结尾的话,就还没找到,那么就返回null
} while ((e = e.next) != null);
}
}
return null;//如果上述条件不满足,也就是桶为null或者在指定位置没有数据,那么就返回null
}
接下来是remove(Object key)方法。
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
其实就是removeNode方法
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
//matchValue是用来判断的,因为remove还有一个方法,是两个参数的,remove(Object key, Object value).这个方法也是套娃了removeNode方法,意思是不仅key得一致,value也得一致才能删除。否则删不了。matchValue就是用来做这个判断得
* //tab:引用当前hashMap中的散列表
* //p:当前node元素
* //n:表示散列表数组长度
* //index:表示寻址结果,索引位置。
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&//这里还是一样,先判断有没有水,不然不需要取水了。
(p = tab[index = (n - 1) & hash]) != null) {//找到对应的桶位是有数据的,要不然为null还删啥
Node<K,V> node = null, e; K k; V v; //node为查找到的结果, e表示当前node的下一个元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//当前定位的桶位的索引处的头节点就是要找的结果
node = p;//那么把p赋值给node
else if ((e = p.next) != null) {说明当前桶位的头节点有下一个节点,要么是红黑树,要么是链表
if (p instanceof TreeNode)//如果是红黑树
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;//这里条件是说明如果是链表中的某一个,那么就找到了这个节点,并把则会个结果赋值给node。用于返回。并退出循环
break;
}
p = e;//这里是还没找到继续挨个迭代
} while ((e = e.next) != null);
}
}//上述是查找过程。下面是删除过程
if (node != null && (!matchValue || (v = node.value) == value ||//!matchValue || (v = node.value) == value就是用来判断值是否需要判断一样再删除,就是两个参数的remove方法的条件。如果不是,那么!matchValue就是对的,后面值得判断就不用判断了
(value != null && value.equals(v)))) {//这里就是判断是否是要删除这个节点。
if (node instanceof TreeNode)//这种情况代表结果是树的节点。就走树的删除逻辑
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)//当当前桶位的元素就是要删除的元素,那么node才会等于p,那么就把node之后的头节点放到这个桶位就行
tab[index] = node.next;
else
p.next = node.next;//链表的情况的时候,node一定是在后面。因为上述查找过程中e一直都是p.next,e又赋值给node。所以node就在p后面。这里删除node节点就行。
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
replace方法主要是调用getnode。上文已经讲述过了。这里不赘述。
注意:链表转化为红黑树的条件是当前桶位中的节点数到达8并且散列表的长度大于等于64。
还有table扩容的时候,并不是只是桶位的第一个元素才算。根据添加函数中的size++;size是只要加入一个元素,就加1.也就是加入的元素不是桶位第一个元素,而是加到红黑树或者链表中了。也算。这样只要达到了阈值0.75*长度。散列表table就会扩容。
HashMap源码个人解读的更多相关文章
- 最通俗易懂的 HashMap 源码分析解读
HashMap 作为最常用的集合类之一,有必要深入浅出的了解一下.这篇文章会深入到 HashMap 源码,刨析它的存储结构以及工作机制. 1. HashMap 的存储结构 HashMap 的数据存储结 ...
- HashMap源码解读(转)
http://www.360doc.com/content/10/1214/22/573136_78188909.shtml 最近朋友推荐的一个很好的工作,又是面了2轮没通过,已经是好几次朋友内推没过 ...
- HashMap源码解读(JDK1.7)
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- 逐行解读HashMap源码
[本文版权归微信公众号"代码艺术"(ID:onblog)所有,若是转载请务必保留本段原创声明,违者必究.若是文章有不足之处,欢迎关注微信公众号私信与我进行交流!] 一.写在前面 相 ...
- HashMap源码解析和设计解读
HashMap源码解析 想要理解HashMap底层数据的存储形式,底层原理,最好的形式就是读它的源码,但是说实话,源码的注释说明全是英文,英文不是非常好的朋友读起来真的非常吃力,我基本上看了差不多 ...
- 【Java深入研究】9、HashMap源码解析(jdk 1.8)
一.HashMap概述 HashMap是常用的Java集合之一,是基于哈希表的Map接口的实现.与HashTable主要区别为不支持同步和允许null作为key和value.由于HashMap不是线程 ...
- HashMap源码分析-jdk1.7
注:转载请注明出处!!!!!!!这里咱们看的是JDK1.7版本的HashMap 学习HashMap前先知道熟悉运算符合 *左移 << :就是该数对应二进制码整体左移,左边超出的部分舍弃,右 ...
- 探索HashMap源码 一行一行解析 jdk1.7版本
今天我们来说一说,HashMap的源码到底是个什么? 面试大厂这方面一定会经常问到,很重要的.以jdk1.7 为标准 先带着大家过一遍 是由数组.链表组成 , 数组的优点是:每个元素有对应下标, ...
- java集合专题 (ArrayList、HashSet等集合底层结构及扩容机制、HashMap源码)
一.数组与集合比较 数组: 1)长度开始时必须指定,而且一旦指定,不能更改 2)保存的必须为同一类型的元素 3)使用数组进行增加/删除元素-比较麻烦 集合: 1)可以动态保存任意多个对象,使用比较方便 ...
随机推荐
- how to open a terminal in finder folder of macOS
how to open a terminal in finder folder of macOS shit service demo refs https://lifehacker.com/launc ...
- input number css hidden arrow
input number css hidden arrow show arrow OK input[type="number"]::-webkit-inner-spin-butto ...
- js字典
传送门https://www.2cto.com/kf/201709/680989.html 点击
- [C#] 尝鲜.net6.0的C#代码热重载
看到.NET 6 Preview 1 发布,里面"除了 XAML 热重载之外,还将支持 C# 代码的热重载"一句,觉得有必要试试看,因为XAML热重载功能用起来确实很爽. 首先要下 ...
- ElasticSearch DSL 查询
公号:码农充电站pro 主页:https://codeshellme.github.io DSL(Domain Specific Language)查询也叫做 Request Body 查询,它比 U ...
- 在 TKE 中使用 Velero 迁移复制集群资源
概述 Velero(以前称为Heptio Ark)是一个开源工具,可以安全地备份和还原,执行灾难恢复以及迁移 Kubernetes 群集资源和持久卷,可以在 TKE 集群或自建 Kubernetes ...
- 2.go语言入门----变量类型、声明变量、数组、切片
基本变量类型 介绍几种基本的变量类型:字符串.int.float.bool package main import ( "fmt" ) // 列举几种非常基本的数据类型 func ...
- Vue使用 空白占位符
当有时候需要在页面显示时显示空格时,可以使用 ,但是使用这个占位符时,无论写多少个,就只能显示一个空格.要想显示多个空格进行占位,这种方式显然是可行的,解决方法是使用转义字符. 先看代码: <t ...
- python中lambda、yield、map、filter、reduce的使用
1. 匿名函数lambda python中允许使用lambda关键字定义一个匿名函数.所谓的匿名函数就是说使用一次或者几次之后就不再需要的函数,属于"一次性"函数. #例1:求两数 ...
- 将MacOS Catalina 降级为 Mojave
1.下载Mojave https://apps.apple.com/cn/app/macos-mojave/id1398502828?ls=1&mt=12 2.更改U盘格式和名称 3.制作U盘 ...