hdu2586&&poj1330 求点间最短距&&最近公共祖先(在线&&离线处理):::可做模板
How far away ?
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 9097 Accepted Submission(s): 3171
are n houses in the village and some bidirectional roads connecting
them. Every day peole always like to ask like this "How far is it if I
want to go from house A to house B"? Usually it hard to answer. But
luckily int this village the answer is always unique, since the roads
are built in the way that there is a unique simple path("simple" means
you can't visit a place twice) between every two houses. Yout task is to
answer all these curious people.
For
each test case,in the first line there are two numbers
n(2<=n<=40000) and m (1<=m<=200),the number of houses and
the number of queries. The following n-1 lines each consisting three
numbers i,j,k, separated bu a single space, meaning that there is a road
connecting house i and house j,with length k(0<k<=40000).The
houses are labeled from 1 to n.
Next m lines each has distinct integers i and j, you areato answer the distance between house i and house j.
25
100
100
描述:
已知在一个村庄中有n个房子,一些双向的道路把这些房子连接了起来。但是每天都有人询问诸如“如果我想从A房子走到B房子需要走多远的距离?” 的问题。幸运的是,在这个村庄中这个答案总是唯一的,因为任意两个房子之间仅存在一条简单路径(路径上的地点只能访问一次)。你现在的任务是回答这些人的询问。
输入:
输入一个整数n表示房子总数,一个整数m表示询问的总数(n<=40000,m<=200),接下来的n-1行输入n-1条道路的状况,每行3个整数a,b,c表示a房子和b房子之间有一条长度为c的双向道路,接下来输入m行询问,每行两个整数a,b要求给出a房子和b房子的最小距离。
思路: 可以用LCA算法计算出任意两个房子u,v的最近公共祖先lca(u,v)
假设d[]数组为每个房子节点到根节点的距离,那么有
dis(u, v) = d[u] + d[v] – 2*d[lca(u, v)]
在线算法
/*
这个版本的在线算法比自创的好看简洁多了,可以当模板,效率不高在于算法其本身的原因;
据说离线算法要快不少。
*/
#include <cstdio>
#include <cstring>
#include <iostream>
#include <cmath>
#include <vector>
using namespace std; const int NN=; int n,rt;
vector<pair<int,int> > edge[NN]; int depth=;
int bn=,b[NN*]; //深度序列
int f[NN*]; //对应深度序列中的结点编号
int p[NN]; //结点在深度序列中的首位置
int dis[NN]; //结点到根的距离
void dfs(int u,int fa)
{
int tmp=++depth;
b[++bn]=tmp; f[tmp]=u; p[u]=bn;
for (int i=; i<edge[u].size(); i++)
{
int v=edge[u][i].first;
if (v==fa) continue;
dis[v]=dis[u]+edge[u][i].second;
dfs(v,u);
b[++bn]=tmp;
}
} int dp[NN*][];
void rmq_init(int n) //以深度序列做rmq
{
for (int i=; i<=n; i++) dp[i][]=b[i];
int m=floor(log(n*1.0)/log(2.0));
for (int j=; j<=m; j++)
for (int i=; i<=n-(<<j)+; i++)
dp[i][j]=min(dp[i][j-],dp[i+(<<(j-))][j-]);
}
int rmq(int l,int r)
{
int k=floor(log((r-l+)*1.0)/log(2.0));
return min(dp[l][k],dp[r-(<<k)+][k]);
} int lca(int a,int b)
{
if (p[a]>p[b]) swap(a,b);
int k=rmq(p[a],p[b]);
return f[k];
} int main()
{
int m,u,v,w;
int t;
scanf("%d",&t);
while(t--){
scanf("%d%d",&n,&m);
for (int i=; i<=n; i++) edge[i].clear();
for(int i=;i<n;i++)
{
scanf("%d%d%d",&u,&v,&w);
edge[u].push_back(make_pair(v,w));
edge[v].push_back(make_pair(u,w));
}
rt=; dis[rt]=;
dfs(,);
rmq_init(bn); while (m--)
{
scanf("%d%d",&u,&v);
printf("%d\n",dis[u]+dis[v]-*dis[lca(u,v)]);
} }
return ;
}
离线算法
#include <cstdio>
#include <cstring>
#include <iostream>
#include <vector>
using namespace std; const int NN=50010; int n,m;
vector<pair<int,int> > edge[NN],qe[NN];
vector<int> q1,q2; int p[NN];
int find(int x)
{
if (p[x]!=x) p[x]=find(p[x]);
return p[x];
} int sum=0,ans[NN],dis[NN];
bool vis[NN]={0};
void lca(int u,int fa)
{
p[u]=u;
for (int i=0; i<edge[u].size(); i++)
{
int v=edge[u][i].first;
if (v==fa) continue;
dis[v]=dis[u]+edge[u][i].second;
lca(v,u);
p[v]=u;
}
vis[u]=true;
if (sum==m) return;
for (int i=0; i<qe[u].size(); i++)
{
int v=qe[u][i].first;
if (vis[v])
ans[qe[u][i].second]=dis[u]+dis[v]-2*dis[find(v)];
}
} int main()
{
int u,v,w; int t;
scanf("%d",&t);
while(t--){
scanf("%d%d",&n,&m);
for (int i=1; i<=n; i++)
{
edge[i].clear();
}
for (int i=1; i<n; i++)
{
scanf("%d%d%d",&u,&v,&w);
edge[u].push_back(make_pair(v,w));
edge[v].push_back(make_pair(u,w));
} for (int i=0; i<m; i++)
{
scanf("%d%d",&u,&v);
qe[u].push_back(make_pair(v,i));
qe[v].push_back(make_pair(u,i));
ans[i]=0;
}
dis[1]=0;
lca(1,0);
for (int i=0; i<m; i++) printf("%d\n",ans[i]);
}
return 0;
}
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 22116 | Accepted: 11566 |
Description
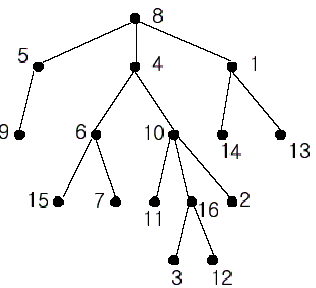
In the figure, each node is labeled with an integer from {1,
2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node
y if node x is in the path between the root and node y. For example,
node 4 is an ancestor of node 16. Node 10 is also an ancestor of node
16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of
node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6,
and 7 are the ancestors of node 7. A node x is called a common ancestor
of two different nodes y and z if node x is an ancestor of node y and an
ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of
nodes 16 and 7. A node x is called the nearest common ancestor of nodes y
and z if x is a common ancestor of y and z and nearest to y and z among
their common ancestors. Hence, the nearest common ancestor of nodes 16
and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is
node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and
the nearest common ancestor of nodes 4 and 12 is node 4. In the last
example, if y is an ancestor of z, then the nearest common ancestor of y
and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
input consists of T test cases. The number of test cases (T) is given in
the first line of the input file. Each test case starts with a line
containing an integer N , the number of nodes in a tree,
2<=N<=10,000. The nodes are labeled with integers 1, 2,..., N.
Each of the next N -1 lines contains a pair of integers that represent
an edge --the first integer is the parent node of the second integer.
Note that a tree with N nodes has exactly N - 1 edges. The last line of
each test case contains two distinct integers whose nearest common
ancestor is to be computed.
Output
Sample Input
2
16
1 14
8 5
10 16
5 9
4 6
8 4
4 10
1 13
6 15
10 11
6 7
10 2
16 3
8 1
16 12
16 7
5
2 3
3 4
3 1
1 5
3 5
Sample Output
4
3
Source
//这个tarjan算法使用了并查集+dfs的操作。中间的那个并查集操作的作用,只是将已经查找过的节点捆成一个集合然后再指向一个公共的祖先。另外,如果要查询LCA(a,b),必须把(a,b)和(b,a)都加入邻接表。
//
//O(n+Q) #include <iostream>
#include <cstdio>
#include <cstring>
#include <vector> using namespace std; #define MAXN 10001 int n,fa[MAXN];
int rank[MAXN];
int indegree[MAXN];
int vis[MAXN];
vector<int> hash[MAXN],Qes[MAXN];
int ances[MAXN];//祖先 void init(int n)
{
for(int i=;i<=n;i++)
{
fa[i]=i;
rank[i]=;
indegree[i]=;
vis[i]=;
ances[i]=;
hash[i].clear();
Qes[i].clear();
}
} int find(int x)
{
if(x != fa[x])
fa[x]=find(fa[x]);
return fa[x];
} void unio(int x,int y)
{
int fx=find(x),fy=find(y);
if(fx==fy) return ;
if(rank[fy]<rank[fx])
fa[fy]=fx;
else
{
fa[fx]=fy;
if(rank[fx]==rank[fy])
rank[fy]++;
}
} void Tarjan(int u)
{
ances[u]=u;
int i,size = hash[u].size();
for(i=;i<size;i++)
{
Tarjan(hash[u][i]);//递归处理儿子
unio(u,hash[u][i]);//将儿子父亲合并,合并时会将儿子的父亲改为u
ances[find(u)]=u;//此时find(u)仍为u,即
}
vis[u]=; //查询
size = Qes[u].size();
for(i=;i<size;i++)
{
if(vis[Qes[u][i]]==)//即查询的另一个结点开始已经访问过,当前的u在此回合访问。
{
printf("%d\n",ances[find(Qes[u][i])]);//由于递归,此时还是在u
return;
}
}
} int main()
{
int t;
int i,j;
scanf("%d",&t);
while(t--)
{
scanf("%d",&n);
init(n);
int s,d;
for(i=;i<=n-;i++)
{
scanf("%d%d",&s,&d);
hash[s].push_back(d);
indegree[d]++;
}
scanf("%d%d",&s,&d);
// if(s==d)//如果需要计数的时候注意
// ans[d]++;
// else
// {
Qes[s].push_back(d);
Qes[d].push_back(s);
// }
for(j=;j<=n;j++)
{
if(indegree[j]==)
{
Tarjan(j);
break;
}
}
}
return ;
}
hdu2586&&poj1330 求点间最短距&&最近公共祖先(在线&&离线处理):::可做模板的更多相关文章
- 求LCA最近公共祖先的离线Tarjan算法_C++
这个Tarjan算法是求LCA的算法,不是那个强连通图的 它是 离线 算法,时间复杂度是 O(m+n),m 是询问数,n 是节点数 它的优点是比在线算法好写很多 不过有些题目是强制在线的,此类离线算法 ...
- HDU 1330 Nearest Common Ancestors(求两个点的近期公共祖先)
题目链接:id=1330">传送门 在线算法: #include <iostream> #include <cstdio> #include <cstri ...
- HDU2586.How far away ?——近期公共祖先(离线Tarjan)
http://acm.hdu.edu.cn/showproblem.php?pid=2586 给定一棵带权有根树,对于m个查询(u,v),求得u到v之间的最短距离 那么仅仅要求得LCA(u,v),di ...
- POJ 1330 Nearest Common Ancestors(求最近的公共祖先)
题意:给出一棵树,再给出两个节点a.b,求离它们最近的公共祖先.方法一: 先用vector存储某节点的子节点,fa数组存储某节点的父节点,最后找出fa[root]=0的根节点root. 之后 ...
- LCA 在线倍增法 求最近公共祖先
第一步:建树 这个就不说了 第二部:分为两步 分别是深度预处理和祖先DP预处理 DP预处理: int i,j; ;(<<j)<n;j++) ;i<n;++i) ) fa[i ...
- 倍增法求lca(最近公共祖先)
倍增法求lca(最近公共祖先) 基本上每篇博客都会有参考文章,一是弥补不足,二是这本身也是我学习过程中找到的觉得好的资料 思路: 大致上算法的思路是这样发展来的. 想到求两个结点的最小公共祖先,我们可 ...
- POJ 1986 Distance Queries (Tarjan算法求最近公共祖先)
题目链接 Description Farmer John's cows refused to run in his marathon since he chose a path much too lo ...
- 连通分量模板:tarjan: 求割点 && 桥 && 缩点 && 强连通分量 && 双连通分量 && LCA(近期公共祖先)
PS:摘自一不知名的来自大神. 1.割点:若删掉某点后.原连通图分裂为多个子图.则称该点为割点. 2.割点集合:在一个无向连通图中,假设有一个顶点集合,删除这个顶点集合,以及这个集合中全部顶点相关联的 ...
- 求最近公共祖先(LCA)的各种算法
水一发题解. 我只是想存一下树剖LCA的代码...... 以洛谷上的这个模板为例:P3379 [模板]最近公共祖先(LCA) 1.朴素LCA 就像做模拟题一样,先dfs找到基本信息:每个节点的父亲.深 ...
随机推荐
- 20.JSON
JSON是javascript的一个子集,利用js中的一些儿模式来表示结构化数据.不是只有javascript才使用JSON,JSON是一种数据格式,很多编程语言都有针对JSON的解析器和序列化器. ...
- python_42_文件补充
m=['红烧肉\n','熘肝尖','西红柿炒鸡蛋','腊八粥','油焖大虾'] fname=input("请输入文件名:")#输入xxx f=open(fname,'w',enco ...
- java程序换图标
ImageIcon img = new ImageIcon("D:\\mahou-in-action\\ShiJuanFenXi\\src\\zoom-in.png"); inst ...
- Linux网络编程之"获取网络天气信息"
需求分析: 1.需要Linux c 网络编程基础, 2.需要了解 http 协议 3.需要天气信息相关api(可以从阿里云上购买,很便宜的!) 4.需要cJSON解析库(因为获取到的天气信息一般是用c ...
- NOIP2018 全国热身赛 第二场 (不开放)
NOIP2018 全国热身赛 第二场 (不开放) 题目链接:http://noi.ac/contest/26/problem/60 一道蛮有趣的题目. 然后比赛傻逼了. 即将做出来的时候去做别的题了. ...
- 52shaidan.net
52shaidan.net 52gendan.net 朋友的域名
- 快速搭建lvs + keepalived + nginx
环境: VIP 192.168.2.224 LVS 192.168.2.217 centos7 nginx1 192.168.2.231 c ...
- python 使用requests 请求 https 接口 ,取消警告waring
response = requests.request("POST", url, timeout=20, data=payload, headers=headers, proxie ...
- js中的日期
创建日期对象: var date1 = new Date(2018, 11,10) 第二个参数传入的是月份,月份是0-11,实际上要加1 获得现在的时间:var date2 = Date.now() ...
- 六、Shell echo命令
Shell echo命令 Shell 的 echo 指令与 PHP 的 echo 指令类似,都是用于字符串的输出.命令格式: echo string 您可以使用echo实现更复杂的输出格式控制. 1. ...