大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发。面试官问了他10个问题,主要集中在Hbase、Spark、Hive和MapReduce上,基础概念、特点、应用场景等问得多。看来,还是非常注重基础的牢固。整个大数据开发技术,这几个技术知识点占了很大一部分。那本篇文章就着重介绍一下这几个技术知识点。
一、Hbase
1.1、Hbase是什么?
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。
尽管已经有许多数据存储和访问的策略和实现方法,但事实上大多数解决方案,特别是一些关系类型的,在构建时并没有考虑超大规模和分布式的特点。许多商家通过复制和分区的方法来扩充数据库使其突破单个节点的界限,但这些功能通常都是事后增加的,安装和维护都和复杂。同时,也会影响RDBMS的特定功能,例如联接、复杂的查询、触发器、视图和外键约束这些操作在大型的RDBMS上的代价相当高,甚至根本无法实现。
HBase从另一个角度处理伸缩性问题。它通过线性方式从下到上增加节点来进行扩展。HBase不是关系型数据库,也不支持SQL,但是它有自己的特长,这是RDBMS不能处理的,HBase巧妙地将大而稀疏的表放在商用的服务器集群上。
HBase 是Google Bigtable 的开源实现,与Google Bigtable 利用GFS作为其文件存储系统类似, HBase 利用Hadoop HDFS 作为其文件存储系统;Google 运行MapReduce 来处理Bigtable中的海量数据, HBase 同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable 利用Chubby作为协同服务, HBase 利用Zookeeper作为对应。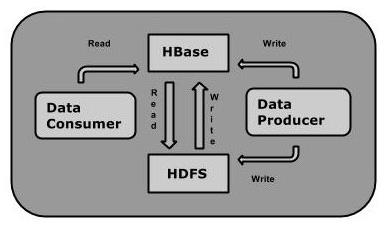
1.2、HBase的特点
◆大:一个表可以有上亿行,上百万列。
◆面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
◆稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
◆无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
◆数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
◆数据类型单一:HBase中的数据都是字符串,没有类型。
更多信息阅读:《Hbase简介》、《Hbase体系架构和集群安装》、《HBase数据模型》
二、Spark
Spark是Apache的一个顶级项目,是一个快速、通用的大规模数据处理引擎。Apache Spark是一种快速、通用的集群计算系统。它提供了Java、Scala、Python和R的高级API,以及一个支持通用执行图的优化引擎。它还支持丰富的高级工具集,包括用于SQL和结构化数据处理的Spark SQL、用于机器学习的MLlib、图形处理的GraphX和Spark流。
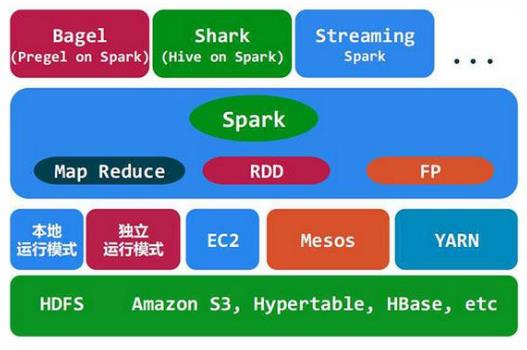
Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的Mapreduce的算法。
Spark的中间数据放到内存中,对于迭代运算效率更高。Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。Spark比Hadoop更通用。
Spark可以用来训练推荐引擎(Recommendation Engine)、分类模型(Classification Model)、回归模型(Regression Model)、聚类模型(Clustering Model)。
更多关于Spark的文章阅读:《【上海大数据培训】Spark集群运行、读取、写入Hbase数据》、《【上海大数据培训】Spark集群的运行过程》
三、Hive
3.1、Hive是什么
◆由Facebook开源,最初用于解决海量结构化的日志数据统计问题;
◆构建在Hadoop之上的数据仓库;
◆Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同);
◆通常用于进行离线数据处理(采用MapReduce);
◆底层支持多种不同的执行引擎(Hive on MapReduce、Hive on Tez、Hive on Spark);
◆支持多种不同的压缩格式、存储格式以及自定义函数(压缩:GZIP、LZO、Snappy、BZIP2.. ;
◆存储:TextFile、SequenceFile、RCFile、ORC、Parquet ; UDF:自定义函数)。
3.2、为什么要使用Hive
◆简单、容易上手(提供了类似SQL查询语言HQL);
◆为超大数据集设计的计算/存储扩展能力(MR计算,HDFS存储);
◆统一的元数据管理(可与Presto/Impala/SparkSQL等共享数据)。
3.3 Hive架构

上图中,可以通过CLI(命令行接口),JDBC/ODBC,Web GUI 访问hive。于此同时hive的元数据(hive中表结构的定义如表有多少个字段,每个字段的类型是什么)都存储在关系型数据库中。三种链接hive的方式最后统一通多一个Diveer 的程序将sql 转化成mapreduce的job任务去执行。
更多Hive信息阅读:《Hive是什么?Hive特点、工作原理,Hive架构,Hive与HBase联系和区别》、《Hive常用字符串函数汇总》、《Hive数据仓库之快速入门》
四、Mapreduce
4.1、MapReduce是什么?
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析 应用”的核心框架。MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
4.2、为什么需要 MapReduce?
◆ 海量数据在单机上处理因为硬件资源限制,无法胜任。
◆ 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度。
◆引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理。
4.3、MapReduce核心机制
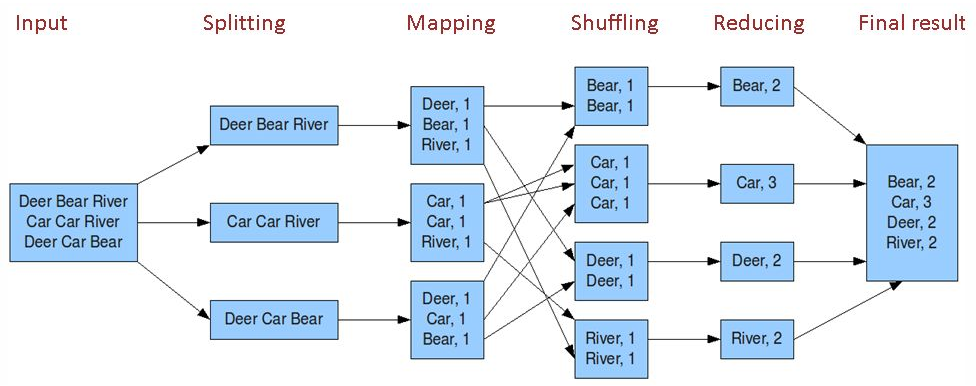
MapReduce核心就是map+shuffle+reducer,首先通过读取文件,进行分片,通过map获取文件的key-value映射关系,用作reducer的输入,在作为reducer输入之前,要先对map的key进行一个shuffle,也就是排个序,然后将排完序的key-value作为reducer的输入进行reduce操作,当然一个MapReduce任务可以不要有reduce,只用一个map。
更多MapReduce的文章阅读:《MapReduce设计及工作原理分析》
以上就是总结的Hbase、Spark、Hive、MapReduce的概念理解和特点,以及一些应用场景和核心机制。欢迎大家评论留言,需要相关学习资料也可以留言联系。
大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制的更多相关文章
- 大数据的存储——HBase、HIVE、MYSQL数据库学习笔记
HBase 1.hbase为查询而生,它通过组织机器的内存,提供一个超大的内存hash表,它需要组织自己的数据结构,表在hbase中是物理表,而不是逻辑表,搜索引擎用它来存储索引,以满足实时查询的需求 ...
- 了解大数据的技术生态系统 Hadoop,hive,spark(转载)
首先给出原文链接: 原文链接 大数据本身是一个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你能够把它比作一个厨房所以须要的各种工具. 锅碗瓢盆,各 ...
- 一文教你看懂大数据的技术生态圈:Hadoop,hive,spark
转自:https://www.cnblogs.com/reed/p/7730360.html 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞 ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 大数据入门第二十二天——spark(一)入门与安装
一.概述 1.什么是spark 从官网http://spark.apache.org/可以得知: Apache Spark™ is a fast and general engine for larg ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
随机推荐
- c博客作业--函数
1.1 思维导图 1.2 本章学习体会及代码量学习体会 1.2.1 学习体会 刚刚开始学习函数的时候,由于之前对函数有过一定的了解,所以还算比较顺利,不过还是经常出现函数定义和调用的错误,这应该是对函 ...
- 总zabbix配置-搭建-邮件报警-微信报警-监控mysql
Centos7安装Zabbix4.0步骤 官方搭建zabbix4.0的环境要求: 1. 环境搭建LAMP 前提Centos系统安装完成: 确认一下: 1 2 cat /etc/redhat-rele ...
- elasticsearch 学习
docker run -p : -d elasticsearch #直接拉取运行 #指定条件搜索curl --request GET \ --url 'http://localhost:9200/im ...
- C#连接MySQL
由于工作需要,从本地Sqlite数据库转为MySql数据库.遇到了一些坑,随后又埋了.记录下过程: 一.安装MySql 首先上官网下载windows版的MySql.解压.详情是参考了几位同鞋的文章: ...
- youtube去广告
https://www.digitbin.com/youtube-ads-block/ 1. OGYouTube | Mod AdBlocker YouTube OGYouTube App is a ...
- Django----博客文章数据返回
步骤1:新建视图函数 from django.shortcuts import render from django.http import HttpResponse; from blog.model ...
- python将多个pdf合成一个
'''# -*- coding:utf-8*-''' import sys import importlib importlib.reload(sys) import os import os.pat ...
- 解释器、环境变量、如何运行python程序、变量先定义后引用
python解释器的介绍.解释器的安装.环境变量的添加为什么加环境变量.如何调取不同的解释器版本实现多版本共存.python程序如何运行的.python的变量定义 一.python解释器: 用来翻译语 ...
- vmware虚机 修改bios方法
.vmx文件添加以下行,会在下次启动时自动出现bios,并会将"TRUE"改为“false” bios.forceSetupOnce = "TRUE"
- 使用mongodb的一些笔记
show dbs # 从结果中发现有cmb_demo_23_hackeruse cmb_demo_23_hacker db.all_in_one.find({"_id":15480 ...