预测python数据分析师的工资
前两篇博客分别对拉勾中关于 python 数据分析有关的信息进行获取(https://www.cnblogs.com/lyuzt/p/10636501.html)和对获取的数据进行可视化分析(https://www.cnblogs.com/lyuzt/p/10643941.html),这次我们就用 sklearn 对不同学历和工作经验的 python 数据分析师做一个简单的工资预测。由于在前面两篇博客中已经了解了数据集的大概,就直接进入正题。
一、对薪资进行转换
在这之前先导入模块并读入文件,不仅有训练数据文件,还有一组自拟的测试数据文件。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt train_file = "analyst.csv"
test_file = "test.csv"
# 读取文件获得数据
train_data = pd.read_csv(train_file, encoding="gbk")
train_data = train_data.drop('ID', axis=1) test_data = pd.read_csv(test_file, encoding="gbk")
train_data.shape, test_data.shape
为了更好地进行分析,我们要对薪资做一个预处理。由于其分布比较散乱,很多值的个数只有1。为了不造成过大的误差,根据其分布情况,可以将它分成【5k 以下、5k-10k、10k-20k、20k-30k、30k-40k、40k 以上】,为了更加方便我们分析,取每个薪资范围的中位数,并划分到我们指定的范围内。
salarys = train_data['薪资'].unique() # 获取到薪资的不同值
for salary in salarys:
# 根据'-'进行分割并去掉'k',分别将两端的值转换成整数
min_sa = int(salary.split('-')[0][:-1])
max_sa = int(salary.split('-')[1][:-1])
# 求中位数
median_sa = (min_sa + max_sa) / 2
# 判断其值并划分到指定范围
if median_sa < 5:
train_data.replace(salary, '5k以下', inplace=True)
elif median_sa >= 5 and median_sa < 10:
train_data.replace(salary, '5k-10k', inplace=True)
elif median_sa >= 10 and median_sa < 20:
train_data.replace(salary, '10k-20k', inplace=True)
elif median_sa >= 20 and median_sa < 30:
train_data.replace(salary, '20k-30k', inplace=True)
elif median_sa >= 30 and median_sa < 40:
train_data.replace(salary, '30k-40k', inplace=True)
else:
train_data.replace(salary, '40k以上', inplace=True)
处理完成后,我们可以将“薪资”单独提取出来当作训练集的 label。
y_train = train_data.pop('薪资').values
二、对变量进行转换
把category的变量转变成numerical表达式
由于变量都不是numerical变量,在训练的时候计算机没办法识别,因此要对它们进行转换。 当我们用numerical来表达categorical的时候,要注意,数字本身有大小的含义,所以乱用数字会给之后的模型学习带来麻烦。于是我们可以用One-Hot的方法来表达category。
pandas自带的get_dummies方法,可以一键做到One-Hot。 这里按我的理解解释一下One-Hot:比如说data['学历要求']有'大专', '本科', '硕士', '不限'。但data['学历要求']=='本科',则他可以用字典表示成这样{'大专': 0, '本科':1, '硕士':0, '不限':0},用向量表示为[0, 1, 0, 0] 。
在此之前,将测试集和训练集组合起来一起处理,稍微方便一点。
data = pd.concat((train_data, test_data), axis=0)
dummied_data = pd.get_dummies(data)
dummied_data.head()
为了更好地理解 One-Hot ,把处理后的结果展示出来,得到的结果是这样的:

当然,也可以用别的方法,比如用数字代替不同的值,这也是可以的。
上次可视化分析的时候就已经知道数据集中不存在缺失值了,为了走一下流程并确保正确性,再次看一下是否有缺失值。
dummied_data.isnull().sum().sort_values(ascending=False).head(10)

OK,很好,没有缺失值。这些值比较简单,不需要做那么多工作,但还是要先把训练集和测试集分开。
X_train = dummied_data[:train_data.shape[0]].values
X_test = dummied_data[-test_data.shape[0]:].values
三、选择参数
1、DecisionTree(决策树)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
features_scores = []
max_features = [.1, .2, .3, .4, .5, .6, .7, .8, .9]
for max_feature in max_features:
clf = DecisionTreeClassifier(max_features=max_feature)
features_score = cross_val_score(clf, X_train, y_train, cv=5)
features_scores.append(np.mean(features_score))
plt.plot(max_features, features_scores)
这个过程主要是通过交叉验证获得使模型更好时的参数,交叉验证大概可以理解为,把训练集分成几部分,然后分别把他们设置为训练集和测试集,重复循环训练得到的结果取平均值。Emmm... 感觉这样讲还是有点笼统,还是上网查来得详细吧哈哈。
然后我们得到的参数和值得关系如图所示:
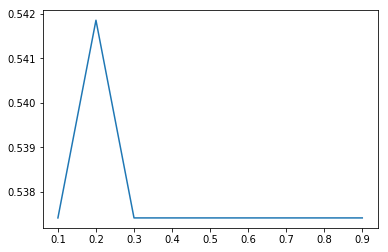
可见当 max_features = 0.2 时达到最大,大概有0.5418。
2、ensemble(集成算法)
集成学习简单理解就是指采用多个分类器对数据集进行预测,从而提高整体分类器的泛化能力。这里将采用sklearn 的 AdaBoostClassifier(adaptive boosting) 通过改变训练样本的权值,学习多个分类器,并将这些分类器进行线性组合,提高泛化性能。
from sklearn.ensemble import AdaBoostClassifier
n_scores = []
estimator_nums = [5, 10, 15, 20, 25, 30, 35, 40]
for estimator_num in estimator_nums:
clf = AdaBoostClassifier(n_estimators=estimator_num, base_estimator=dtc)
n_score = cross_val_score(clf, X_train, y_train, cv=5)
n_scores.append(np.mean(n_score))
plt.plot(estimator_nums, n_scores)
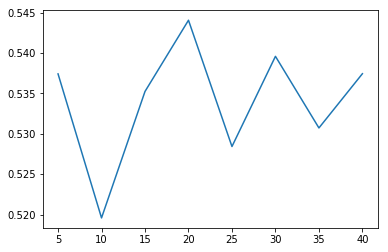
当 estimators=20 的时候,score最高,大概有0.544,虽然跟单个决策树的 score 的值相差不大,但总体还是有所提升。
四、建立模型
参数选择完毕,就可以建立模型了。
dtc = DecisionTreeClassifier(max_features=0.2)
abc = AdaBoostClassifier(n_estimators=20)
# 训练
abc.fit(X_train, y_train)
dtc.fit(X_train, y_train)
# 预测
y_dtc = dtc.predict(X_test)
y_abc = abc.predict(X_test) test_data['薪资(单个决策树)'] = y_dtc
test_data['薪资(boosting)'] = y_abc
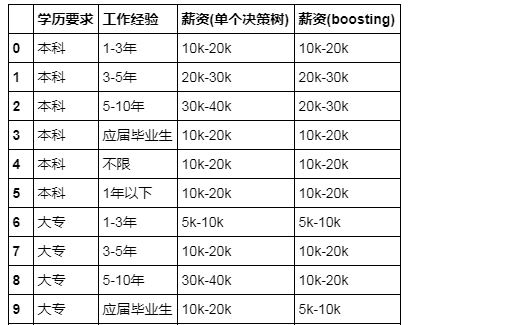
至于结果,总不可能预测得很完美,而且不同模型的结果也会有所不同,更何况它预测出来的结果是否符合常理还有待商榷,所以就把它当作一个小项目就好了,具体代码在这里:https://github.com/MaxLyu/Lagou_Analyze
预测python数据分析师的工资的更多相关文章
- python 数据分析师
简介 越来越多的政府机关.企事业单位将选择拥有数据分析师资质的专业人士为他们的项目做出科学.合理的分析.以便正确决策:越来越多的风险投资机构把数据分析师所出具的数据分析报告作为其判断项目是否可行及是否 ...
- python数据分析师面试题选
以下题目均非原创,只是汇总 python数据分析部分 1. 如何利用SciKit包训练一个简单的线性回归模型 利用linear_model.LinearRegression()函数 # Create ...
- 曾经我是一个只会excel的数据分析师,直到我遇到了……
我是一个数据分析师. 准确来说我是一个当年只会excel数据透视表,就天不怕地不怕地来当数据分析师的人.当年的某一天,我的老板Q我: 小刘啊,我小姨子给了我一个全国市委书记的名单,你帮我看看,有什么规 ...
- Python数据分析在互联网寒冬下,数据分析师还吃香吗?
伴随着移动互联网的飞速发展,越来越多用户被互联网连接在一起,用户所积累下来的数据越来越多,市场对数据方面人才的需求也越来越大,由此也带火了如数据分析.数据挖掘.算法等职业,而作为其中入门门槛相对较低. ...
- Python拉勾爬虫——以深圳地区数据分析师为例
拉勾因其结构化的数据比较多因此过去常常被爬,所以在其多次改版之下变得难爬.不过只要清楚它的原理,依然比较好爬.其机制主要就是AJAX异步加载JSON数据,所以至少在搜索页面里翻页url不会变化,而且数 ...
- python、数据分析师、算法工程师的学习计划
1.前言 最近(2018.4.1)在百忙之中开通了博客,希望能够把自己所学所想沉淀下来,这篇是我开始系统学习python,成为数据分析师和算法工程师之路的计划,望有志于为同样目标奋斗的数据猿一起交流和 ...
- 数据分析师入门|Python安装MAC版
最近在学数据分析师入门课,看了大纲,感觉终于不再慌乱踩坑了,开始存档最粗暴版学习笔记,遇到停止的地方按照下文红字直接输入就OK,方便和我一样的小伙伴参考呀,老师讲的很适合我这种初学者,PUSH了很多资 ...
- 数据分析师面经一(bk)
2019年第一个数据分析面试: 先说一下心理感受,在BOSS多次看到这个岗位了,但是 呢一直没勇气去投这个岗位.首先毕竟是一个知名企业一万+人的公司,心里多少底气不足(小公司待习惯了吧),而且看岗位要 ...
- 数据分析师的福音——VS 2017带来一体化的数据分析开发环境
(此文章同时发表在本人微信公众号“dotNET开发经验谈”,欢迎右边二维码来关注.) 题记:在上个月的Connect() 2016大会上,微软宣布了VS 2017 RC的发布,其中为数据分析师带来了一 ...
随机推荐
- [CF703D]Mishka and Interesting sum/[BZOJ5476]位运算
[CF703D]Mishka and Interesting sum/[BZOJ5476]位运算 题目大意: 一个长度为\(n(n\le10^6)\)的序列\(A\).\(m(m\le10^6)\)次 ...
- 详解Session和cookie
1.cookie 1.1. 为什么会有cookie? 由于HTTP是无状态的,服务端并不记得你之前的状态.这种设计是为了HTTP协议的方便,但是也存在一些问题.比如我们登录一个购物网站,我们需要用户登 ...
- 微信小程序之canvas绘制海报分享到朋友圈
绘制canvas内容 首先,需要写一个canvas标签,给canvas-id命名为shareBox <canvas canvas-id="shareBox"></ ...
- Spring + SpringMVC + Mybatis项目中redis的配置及使用
maven文件 <!-- redis --> <dependency> <groupId>redis.clients</groupId> <art ...
- hive的join
第一:在map端产生join mapJoin的主要意思就是,当链接的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小的table直接放到内存中去,然后再对比较大的表格进行m ...
- vue三级联动
<select @change="getArea(province_id,1)" v-model="province_id"> <option ...
- 关于postgresql group by 报错
举个例子: table name:makerar cname | wmname | avg --------+-------------+------ ...
- java + maven 实现发送短信验证码功能
如何使用java + maven的项目环境发送短信验证码,本文使用的是榛子云短信 的接口. 1. 安装sdk 下载地址: http://smsow.zhenzikj.com/doc/sdk.html ...
- Go接口interface
目录 接口是什么? interface类型 空接口(interface{}) interface函数参数 interface变量存储的类型 类型断言 嵌入interface 接口是什么? Go 语言不 ...
- [Swift]LeetCode137. 只出现一次的数字 II | Single Number II
Given a non-empty array of integers, every element appears three times except for one, which appears ...