基本DFS与BFS算法(C++实现)
样图:
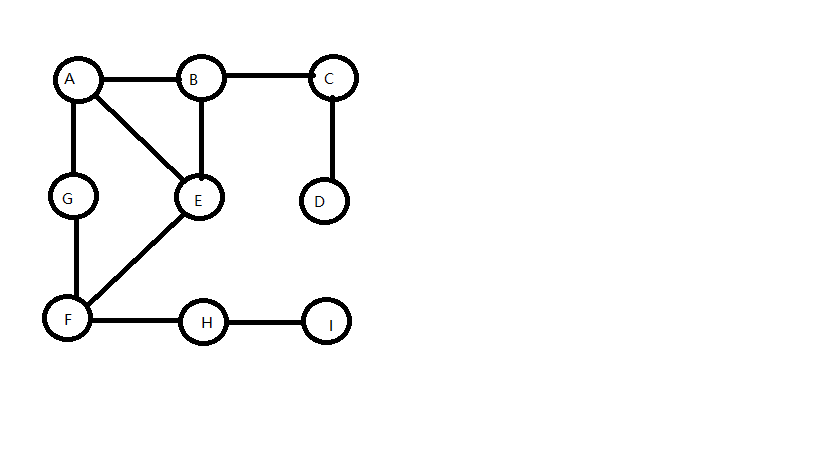
DFS:深度优先搜索,是一个不断探查和回溯的过程,每探查一步就将该步访问位置为true,接着在该点所有邻接节点中,找出尚未访问过的一个,将其作为下个探查的目标,接着对这个目标进行相同的操作,直到回到最初的节点,此时图中所有节点都访问过了。
BFS:广度优先搜索,是一个逐层遍历的过程,每探查一步就将该步访问位置为true,接着在该点所有邻接节点中,找出尚未访问过的一个,将其作为下个探查的目标,接着还是对该节点(而不是所选择的目标)剩下的未访问的点选择一个,作为下一个探查的目标,直到没有邻接点为止。这些探测过的点存放于一个队列中,当该节点没有邻接节点时,取出队首的点进行相同的操作,直到队列为空,此时图中所有节点都访问过了。
实现代码(邻接矩阵法和邻接表法):
邻接矩阵法:(时间复杂度n^2),n代表顶点
#include<iostream>
#include<queue>
#define maxValue 100
using namespace std;
template<class E>
class Graph{//图的邻接矩阵表示(无向图)
public:
Graph(int n){
numV=n;
vlist=new int[n];
visited=new bool[n];
edge=new E*[n];
for(int i=;i<n;i++){
vlist[i]=i;
edge[i]=new E[n];
visited[i]=false;
}
visited[]=true;
for(int i=;i<n;i++){
for(int j=;j<n;j++){
edge[i][j]=(i==j)?:maxValue;
}
}
}
~Graph(){
delete []vlist;
delete []edge;
delete []visited;
}
int getFirst(int v){//获取顶点V的第一个邻接点
for(int col=;col<numV;col++)
if(edge[v][col]>&&edge[v][col]<maxValue)
return col;
return -;
}
int getNext(int v,int w){//获取顶点V的某个邻接点w的下一个 邻接点
for(int col=w+;col<numV;col++)
if(edge[v][col]>&&edge[v][col]<maxValue)
return col;
return -;
}
bool removeV(int v){//删除一个定点上的所有关联边
for(int i=;i<numV;i++){
if(i!=v){
edge[v][i]=maxValue;
edge[i][v]=maxValue;
}
}
}
bool insertE(int v1,int v2,E cost){//插入边V1,V2
edge[v1][v2]=edge[v2][v1]=cost;
}
bool removeE(int v1,int v2){//删除边V1,V2
edge[v1][v2]=edge[v2][v1]=maxValue;
}
E getW(int v1,int v2){//返回边(v1,v2)上的权值
return edge[v1][v2];
}
void DFS(int v){//深度优先搜索
cout<<(char)(vlist[v]+)<<" ";//打印节点
visited[v]=true;//标记该节点被访问过
int w=getFirst(v);//w为节点v的第一个邻接节点
while(w!=-){//v仍有临接节点未访问完
if(visited[w]==false) DFS(w);//如果w未被访问,对w进行新一轮DFS
w=getNext(v,w);//w重新设置成v的下一个临接节点
}
}
void BFS(int v){//广度优先搜索
cout<<(char)(vlist[v]+)<<" ";//打印节点
visited[v]=true;//标记该节点被访问过
queue<int> q;//辅助队列q
q.push(v);//将节点v入队
while(!q.empty()){//队列不为空
int v=q.front();//v为队首元素
q.pop();//v出队
int w=getFirst(v);//w为节点v的第一个邻接节点
while(w!=-){//v仍有临接节点未访问完
if(visited[w]==false){//如果w未被访问,打印节点, 标记该节点被访问过 ,并将该节点入队
cout<<(char)(vlist[w]+)<<" ";
visited[w]=true;
q.push(w);
}
w=getNext(v,w);//w重新设置成v的下一个临接节点
}
}
}
void print(){//打印图
for(int i=;i<numV;i++){
for(int j=;j<numV;j++){
if(edge[i][j]==maxValue)
cout<<"#"<<" ";
else
cout<<edge[i][j]<<" ";
}
cout<<endl;
}
}
private:
int *vlist;
bool *visited;
E **edge;
int numV; };
//1-9分别对应A-I
int main(){
Graph<int> *g=new Graph<int>();
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
// g->DFS(1);//利用注释来回切换
g->BFS();
delete g;
return ;
}
邻接表法:(时间复杂度n+e),e代表边
#include<iostream>
#include<queue>
#define maxValue 100
using namespace std;
template<class E>
struct e{
int v;
e<E> *link;
E cost;
e(int _v,E w,e *l=NULL){
v=_v;
cost=w;
link=l;
}
};
template<class E>
struct V{
char data;
e<E> *link;
V(char d,e<E> *l=NULL){
data=d;
link=l;
}
};
template<class E>
class Graph{
public:
Graph(int n){
numV=n;
vlist=new V<E>*[n];
visited=new bool[n];
for(int i=;i<n;i++){
vlist[i]=new V<E>(i+);
visited[i]=false;
}
visited[]=true;
}
~Graph(){
delete[] vlist;
}
int getFirst(int v){
e<E> *p=vlist[v]->link;
if(p!=NULL)
return p->v;
return -;
}
int getNext(int v,int w){
e<E> *p=vlist[v]->link;
while(p!=NULL&&p->v!=w){
p=p->link;
}
if(p!=NULL&&p->link!=NULL){
return p->link->v;
}
return -;
}
E getW(int v1,int v2){
e<E> *p=vlist[v1]->link;
while(p!=NULL&&p->v!=v2){
p=p->link;
}
if(p!=NULL){
return p->cost;
}
return ;
}
bool removeV(int v){
e<E> *p,*q;
int k;
while(vlist[v]->link!=NULL){
e<E> *m=NULL;
p=vlist[v]->link;
k=p->v;
q=vlist[k]->link;
while(q!=NULL&&q->v!=v){
m=q;q=q->link;
}
if(q!=NULL){
if(m==NULL) vlist[k]->link=q->link;
else m->link=q->link;
delete q;
}
vlist[v]->link=p->link;
delete p;
}
return true;
}
bool insertE(int v1,int v2,int w){
e<E> *p=vlist[v1]->link;
e<E> *q;
bool isIn=false;
while(p!=NULL){
if(p->v==v2){
p->cost=w;
isIn=true;
break;
}
p=p->link;
}
if(isIn){
q=vlist[v2]->link;
while(q!=NULL){
if(q->v==v1){
q->cost=w;
break;
}
q=q->link;
}
return true;
}else{
p=new e<E>(v2,w,vlist[v1]->link);
vlist[v1]->link=p;
q=new e<E>(v1,w,vlist[v2]->link);
vlist[v2]->link=q;
return true;
}
return false;
}
bool removeE(int v1,int v2){
e<E> *p=vlist[v1]->link;
e<E> *q=NULL;
while(p!=NULL){
if(p->v==v2)
break;
else{
q=p;
p=p->link;
}
}
if(p!=NULL){
if(p==vlist[v1]->link) vlist[v1]->link=p->link;
else{
q->link=p->link;
delete p;
}
}else{
return false;
}
p=vlist[v2]->link;
q=NULL;
while(p!=NULL){
if(p->v==v1)
break;
else{
q=p;
p=p->link;
}
}
if(p!=NULL){
if(p==vlist[v2]->link) vlist[v2]->link=p->link;
else{
q->link=p->link;
delete p;
}
}else{
return false;
}
}
void DFS(int v){
cout<<vlist[v]->data<<" ";
visited[v]=true;
int w=getFirst(v);
while(w!=-){
if(visited[w]==false) DFS(w);
w=getNext(v,w);
}
}
void BFS(int v){
cout<<vlist[v]->data<<" ";
visited[v]=true;
queue<int> q;
q.push(v);
while(!q.empty()){
int v=q.front();
q.pop();
int w=getFirst(v);
while(w!=-){
if(visited[w]==false){
cout<<vlist[w]->data<<" ";
visited[w]=true;
q.push(w);
}
w=getNext(v,w);
}
}
}
void print(){//打印邻接表
for(int i=;i<numV;i++){
cout<<vlist[i]->data<<"->";
e<E> *p=vlist[i]->link;
while(p!=NULL){
cout<<p->v<<" "<<p->cost<<"->";
p=p->link;
}
cout<<"^"<<endl;
}
}
private:
V<E> **vlist;
bool *visited;
int numV;
};
int main(){
Graph<int> *g=new Graph<int>();
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
g->insertE(,,);
// g->DFS(1);
g->BFS();
delete g;
return ;
}
基本DFS与BFS算法(C++实现)的更多相关文章
- dfs和bfs算法
1. 存储图的方式一般是有两种的:邻接表和邻接矩阵,一般存储链接矩阵的方式是比较简单的,也便于我们去实现这个临接矩阵,他也就是通俗的二维数组,我们平常用到的那种. 2. 这里我们主要记录和讲一下bfs ...
- 邻接表实现Dijkstra算法以及DFS与BFS算法
//============================================================================ // Name : ListDijkstr ...
- 图的DFS与BFS遍历
一.图的基本概念 1.邻接点:对于无向图无v1 与v2之间有一条弧,则称v1与v2互为邻接点:对于有向图而言<v1,v2>代表有一条从v1到v2的弧,则称v2为v1的邻接点. 2.度:就是 ...
- 图的遍历算法:DFS、BFS
在图的基本算法中,最初需要接触的就是图的遍历算法,根据访问节点的顺序,可分为深度优先搜索(DFS)和广度优先搜索(BFS). DFS(深度优先搜索)算法 Depth-First-Search 深度优先 ...
- BFS与DFS常考算法整理
BFS与DFS常考算法整理 Preface BFS(Breath-First Search,广度优先搜索)与DFS(Depth-First Search,深度优先搜索)是两种针对树与图数据结构的遍历或 ...
- 【数据结构与算法笔记04】对图搜索策略的一些思考(包括DFS和BFS)
图搜索策略 这里的"图搜索策略"应该怎么理解呢? 首先,是"图搜索",所谓图无非就是由节点和边组成的,那么图搜索也就是将这个图中所有的节点和边都访问一遍. 其次 ...
- 图论中DFS与BFS的区别、用法、详解…
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 图论中DFS与BFS的区别、用法、详解?
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- BFS算法(——模板习题与总结)
首先需要说明的是BFS算法(广度优先算法)本质上也是枚举思想的一种体现,本身效率不是很高,当数据规模很小的时候还是可以一试的.其次很多人可能有这样的疑问,使用搜索算法的时候,到底选用DFS还是BFS, ...
随机推荐
- koa-ueditor上传图片到七牛
问题描述:服务器系统架构采用的是koa(并非koa2),客户端富文本编辑器采用的是百度的ueditor控件.现在需要ueditor支持将图片直接上传到七牛云. 前提:百度的ueditor需要在本地配置 ...
- 牛津初阶字典单词F-联想故事
从前有一个fable寓言,讲的是奥巴马穿着棉fabrics织物,走在去往学校的路上,他的心情fabulous极好的,绝妙的.因为他学校的facilities 设施fabulous非常棒,但有些人不喜欢 ...
- vue源码分析—Vue.js 源码构建
Vue.js 源码是基于 Rollup 构建的,它的构建相关配置都在 scripts 目录下.(Rollup 中文网和英文网) 构建脚本 通常一个基于 NPM 托管的项目都会有一个 package.j ...
- 1、roboguide新建工程文件
打开roboguide,软件界面如下,接下来讲解一下“打开和新建工程文件” 首先介绍一下新建工程文件,在工具栏中点击新建按钮或者在文件(file)的下拉菜单中点击新建工程文件(new cell),弹出 ...
- css基本介绍
目录 CSS初识 构造规则 注意 样式表的定义和使用 行内式(内联样式) 内部样式表 外部样式表(外链式) 选择器 标签选择器(元素选择器) 类选择器 id选择器 通配符选择器 伪类选择器 链接伪类选 ...
- Django(七)缓存、信号、Form
大纲 一.缓存 1.1.五种缓存配置 1.2配置 2.1.三种应用(全局.视图函数.模板) 2.2 应用多个缓存时生效的优先级 二.信号 1.Django内置信号 2.自定义信号 三.Form 1.初 ...
- 队列(FIFO)—循环队列、队列的链式存储
1 队列的定义 队列是只允许在一端(队尾)进行插入操作,而在另一端(队头)进行删除操作的线性表. 2 队列的特点 1)先进先出是队列最大的特点,是应用中非常常见的模型,例如排队: 2)队列也属于线性表 ...
- Java中newInstance()和new()区别
前言: 最近在看springIOC和AOP是看见代码中很实用newInstance来实例化一个对象,之前对newInstance和new实例化对象的区别很模糊,特意在这里记录一下 一.newInsta ...
- Linux查看文件大小
//查看系统中文件的使用情况 df -h //查看当前目录下各个文件及目录占用空间大小 du -sh * //查看welcome.txt文件占用空间大小 du -sh welcome.txt //方法 ...
- 搭建一个MP-demo(mybatis_plus)
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发.提高效率而生. 搭建一个简单的MP-demo 1.配置pom.xml ...