Bisecting KMeans (二分K均值)算法讲解及实现
算法原理
由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选到一个类上,一定程度上克服了算法陷入局部最优状态。
二分KMeans(Bisecting KMeans)算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二。之后选择能最大限度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目k为止。以上隐含的一个原则就是:因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点越接近于他们的质心,聚类效果就越好。所以我们就需要对误差平方和最大的簇进行再一次划分,因为误差平方和越大,表示该簇聚类效果越不好,越有可能是多个簇被当成了一个簇,所以我们首先需要对这个簇进行划分。
代码实现
本文在实现过程中采用数据集4k2_far.txt,聚类算法实现过程中默认的类别数量为4。其中辅助函数存于myUtil.py文件和K均值核心函数存于kmeans.py文件,具体参考《KMeans (K均值)算法讲解及实现》。
二分K均值主函数逻辑思想如下代码所示:
# -*- encoding:utf-8 -*- from kmeans import *
import matplotlib.pyplot as plt dataMat = file2matrix("testData/4k2_far.txt", "\t") # 从文件构建的数据集
dataSet = dataMat[:, 1:] # 提取数据集中的特征列 k = 4 # 外部指定1,2,3...通过观察数据集有4个聚类中心
m = shape(dataSet)[0] # 返回矩阵的行数 # 初始化第一个聚类中心: 每一列的均值
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] # 把均值聚类中心加入中心表中
# 初始化聚类距离表,距离方差
# 列1:数据集对应的聚类中心,列2:数据集行向量到聚类中心距离的平方
ClustDist = mat(zeros((m, 2)))
for j in range(m):
ClustDist[j,1] = distEclud(centroid0,dataSet[j,:])**2
'''
color_cluster(ClustDist[:, 0:1], dataSet, plt)
drawScatter(plt, mat(centList), size=60, color='red', mrkr='D')
plt.show()
''' # 依次生成k个聚类中心
while (len(centList) < k):
lowestSSE = inf # 初始化最小误差平方和。核心参数,这个值越小就说明聚类的效果越好。
# 遍历cenList的每个向量
#----1. 使用ClustDist计算lowestSSE,以此确定:bestCentToSplit、bestNewCents、bestClustAss----#
for i in xrange(len(centList)):
# 从dataSet中提取类别号为i的数据构成一个新数据集
ptsInCurrCluster = dataSet[nonzero(ClustDist[:, 0].A == i)[0], :]
# 应用标准kMeans算法(k=2),将ptsInCurrCluster划分出两个聚类中心,以及对应的聚类距离表
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2)
# 计算splitClustAss的距离平方和
sseSplit = sum(multiply(splitClustAss[:, 1], splitClustAss[:, 1])) # 此处求欧式距离的平方和
# 计算ClustDist[ClustDist第1列!=i的距离平方和
sseNotSplit = sum(ClustDist[nonzero(ClustDist[:, 0].A != i)[0], 1])
if (sseSplit + sseNotSplit) < lowestSSE: # 算法公式: lowestSSE = sseSplit + sseNotSplit
bestCentToSplit = i # 确定聚类中心的最优分隔点
bestNewCents = centroidMat # 用新的聚类中心更新最优聚类中心
bestClustAss = splitClustAss.copy() # 深拷贝聚类距离表为最优聚类距离表
lowestSSE = sseSplit + sseNotSplit # 更新lowestSSE
# 回到外循环
# ----2. 计算新的ClustDist----#
# 计算bestClustAss 分了两部分:
# 第一部分为bestClustAss[bIndx0,0]赋值为聚类中心的索引
bestClustAss[nonzero(bestClustAss[:, 0].A == 1)[0], 0] = len(centList)
# 第二部分 用最优分隔点的指定聚类中心索引
bestClustAss[nonzero(bestClustAss[:, 0].A == 0)[0], 0] = bestCentToSplit
# 以上为计算bestClustAss # ----3. 用最优分隔点来重构聚类中心----#
# 覆盖: bestNewCents[0,:].tolist()[0]附加到原有聚类中心的bestCentToSplit位置
# 增加: 聚类中心增加一个新的bestNewCents[1,:].tolist()[0]向量
centList[bestCentToSplit] = bestNewCents[0, :].tolist()[0]
centList.append(bestNewCents[1, :].tolist()[0])
# 以上为计算centList
# 将bestCentToSplit所对应的类重新更新类别
ClustDist[nonzero(ClustDist[:, 0].A == bestCentToSplit)[0], :] = bestClustAss
'''
color_cluster(ClustDist[:, 0:1], dataSet, plt)
drawScatter(plt, mat(centList), size=60, color='red', mrkr='D')
plt.show()
''' # 输出生成的ClustDist:对应的聚类中心(列1),到聚类中心的距离(列2),行与dataSet一一对应
color_cluster(ClustDist[:, 0:1], dataSet, plt)
print "cenList:",mat(centList)
# 绘制聚类中心图形
drawScatter(plt, mat(centList), size=60, color='red', mrkr='D')
plt.show()
评估分类结果
上述代码的”’注释部分给出了每次迭代时,聚类中心的变化情况,如下所示:
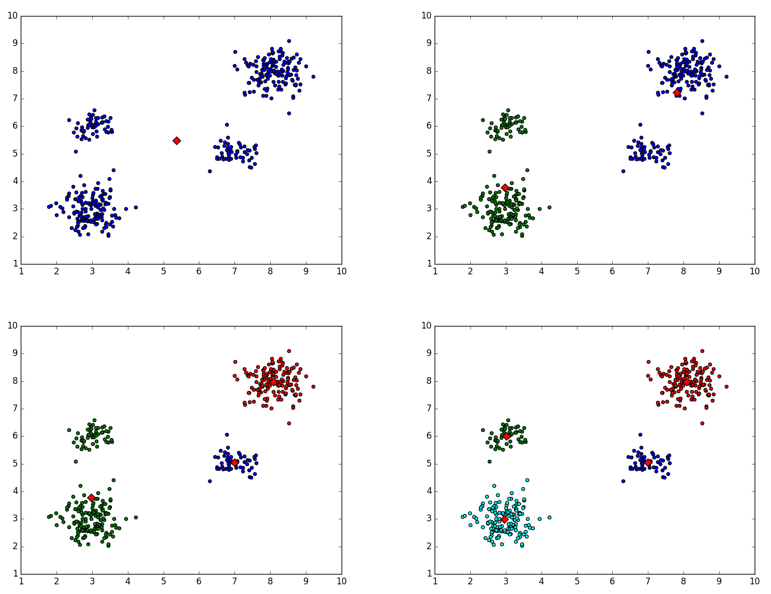
二分K均值聚类中心变化情况
相关
Bisecting KMeans (二分K均值)算法讲解及实现的更多相关文章
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 机器学习算法之Kmeans算法(K均值算法)
Kmeans算法(K均值算法) KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
随机推荐
- Visual Studio 2019 RC
Visual Studio 2019 RC入门 介绍 在本文中,让我们看看如何开始使用Visual Studio 2019 RC.Microsoft现已发布Visual Studio Release ...
- error: ld returned 1 exit status 解决
1.程序未结束运行 2.全局变量冲突,不是宏定义冲突
- Android系统备忘1
Android的4种模式 模式 功能 ADB调试system 正常使用 开发者模式开启usb调试recovery 备份,恢复模式 卡刷模式 twrp下开启ADB Sideloadfastboot 线刷 ...
- NIO 多人聊天室
一前言 在家休息没事,敲敲代码,用NIO写个简易的仿真聊天室.下面直接讲聊天室设计和编码.对NIO不了解的朋友,推荐一个博客,里面写的很棒: https://javadoop.com/ 里面有 ...
- What is the $ symbol used for in JavaScript
It doesn't mean anything special. But because $ is allowed in identifier names, many Javascript libr ...
- java构造代码块详解
一.简介 首先说一下,Java中有哪些代码块. 普通代码块 就是在方法后面使用"{}"括起来的代码片段,不能单独执行,必须调下其方法名才可以执行. 静态代码块 在类中使用stati ...
- 【BZOJ2120】数颜色
看代码学习好,好学好懂好ac 原题: 墨墨购买了一套N支彩色画笔(其中有些颜色可能相同),摆成一排,你需要回答墨墨的提问.墨墨会像你发布如下指令: 1. Q L R代表询问你从第L支画笔到第R支画笔中 ...
- <------------------字符流--------------------->
FileWriter 字符输出流: 方法: 写入:write 刷新:flush public static void main(String[] args) throws IOException { ...
- MySQL Binlog--binlog_format参数
===================================================================================== binlog_format参 ...
- tile38 roaming-geofences 试用
tile38 支持动态实时的移动对象的数据监控 环境准备 docker-compose 文件 version: "3" services: app: image: tile ...