Python 爬虫: 抓取花瓣网图片
接触Python也好长时间了,一直没什么机会使用,没有机会那就自己创造机会!呐,就先从爬虫开始吧,抓点美女图片下来。
废话不多说了,讲讲我是怎么做的。
1. 分析网站
想要下载图片,只要知道图片的地址就可以了,So,现在的问题是如何找到这些图片的地址。
首先,直接访问http://huaban.com/favorite/beauty/会看到页面有20张所要抓取的图片还有一些其他干扰的图片信息(用户的头像、页面的一些图标之类的)。当点击一张美女图片时,页面会跳转到一个新的页面,在这个页面里,是之前那张图片更清晰版本,我们要下当然就要最好的了,就是点击完图片后新页面中那张图片啦。
下一步就是借助一些工具,如firefox的Firebug或者chrome的F12,分析网站。具体步骤有些繁琐,我就不细说了。分析结果是,首先,发送一个get请求,请求url为http://huaban.com/favorite/beauty/,得到一个html页面,在这个页面中<script>标签下有一行以 app.page["pins"] 开头的,就是我们要找的部分,等号后面是一个json字符串,格式化后如下:
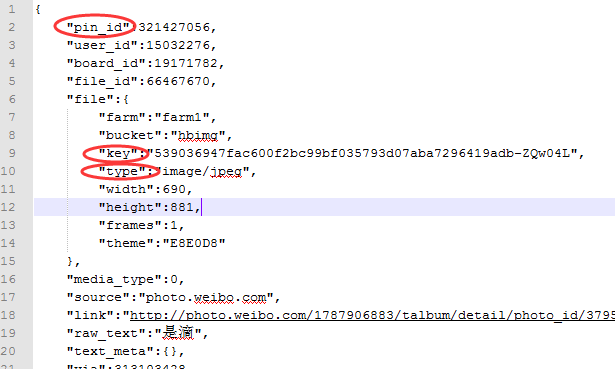
每张要找的图片对应一个字典,图片的url地址与"file"下的"key"有关,图片类型与"file"下的"type"有关,只要得到这两个值就可以下载到图片了。
在每次下拉刷新时,也是发送了一个get请求,在这个请求中有一个关键参数max,这个就是当前页面中最后一个图片的"pin_id",所以,需要抓取三个内容,分别是"pin_id","file"."key"和"file"."type"。
2. 编写爬虫
2.1 requests
使用Python自带的urllib和urllib2库几乎可以完成任何想要的http请求,但是就像requests所说的,Python’s standard urllib2 module provides most of the HTTP capabilities you need, but the API is thoroughly broken. 所以,我这里推荐使用的是requests库,中文文档在这里。
2.2 抓取主页面
直接发送get请求,得到html页面
req = requests.get(url = "http://huaban.com/favorite/beauty/")
htmlPage = req.content
2.3 处理html页面
分析html页面,得到图片的pin_id、url和图片类型。首先,用正则处理页面,得到页面中<script>标签中 app.page["pins"] 开头的一行
prog = re.compile(r'app\.page\["pins"\].*')
appPins = prog.findall(htmlPage)
再将这一行中的数据提取出来,直接生成一个Python字典
null = None
result = eval(appPins[0][19:-1])
注:由于javascript中null在Python中为None,所以要让null=None,appPins中还有一个干扰用切片去掉。
之后就可以得到图片的信息,将这些信息以字典形式存入一个列表中
images = []
for i in result:
info = {}
info['id'] = str(i['pin_id'])
info['url'] = "http://img.hb.aicdn.com/" + i["file"]["key"] + "_fw658"
info['type'] = i["file"]["type"][6:]
images.append(info)
到此,图片的信息都已经得到了。
2.4 下载图片
知道了图片的url,下载图片就变的非常简单了,直接一个get请求,然后再将得到的图片保存到硬盘。
for image in images:
req = requests.get(image["url"])
imageName = image["id"] + "." + image["type"]
with open(imageName, 'wb') as fp:
fp.write(req.content)
2.5 处理下拉刷新
其实处理下拉刷新与之前讲到的处理主页面几乎是一样的,唯一不一样的是每次下拉刷新是get请求的url中max的值不一样,这个值就是我们得到的最后一张图片信息的pin_id。
def make_ajax_url(No):
""" 返回ajax请求的url """
return "http://huaban.com/favorite/beauty/?i5p998kw&max=" + No + "&limit=20&wfl=1" htmlPage = requests.get(url = make_ajax_url(images[-1]['id'])).content
最终程序
最终程序见 Github
附注:花瓣网不需要登录、没有验证码,甚至网站都没有做最基本的反爬虫检测,可以直接得到想要的内容,相对来说还是比较容易处理,很适合刚开始接触爬虫的同学学习。唯一复杂点的是页面下拉刷新是用的ajax,这个也不难,找到每次get请求的参数是怎么获得的,就没问题了。
Python 爬虫: 抓取花瓣网图片的更多相关文章
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Python爬虫抓取糗百的图片,并存储在本地文件夹
思路: 1.观察网页,找到img标签 2.通过requests和BS库来提取网页中的img标签 3.抓取img标签后,再把里面的src给提取出来,接下来就可以下载图片了 4.通过urllib的urll ...
- async 异步抓取 花瓣网高清大图 30s爬取500张
废话 不多说,直接上代码,不懂得看注释 先安装 pip install aiohttp "异步抓取花瓣网图片" # pip install aiohttp import requ ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python学习-抓取知乎图片
#!/bin/usr/env python3 __author__ = 'nxz' """ 抓取知乎图片webdriver Chromedriver驱动需要安装,并指定d ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
随机推荐
- 使用Java+Kotlin双语言的LeetCode刷题之路(二)
BasedLeetCode LeetCode learning records based on Java,Kotlin,Python...Github 地址 序号对应 LeetCode 中题目序号 ...
- 使用composer遇到的问题及解决方法
可以尝试利用composer下载Yii框架,编辑composer.json文件: { "require":{ "yiisoft/yii2":"~2.0 ...
- Selenium Grid的Java调用方法
java -jar selenium-server-standalone-.jar -role hub explorer http://192.168.1.173:4444/grid/console ...
- eclipse集成tomcat日志文件输出配置
eclipse集成tomcat日志文件输入配置 2015-07-21 00:13 1072人阅读 评论(0) 收藏 举报 分类: tomcat(1) eclipse Where can I vie ...
- U 盘安装 CentOS的方法
1. 刻录U盘 我使用的工具是 UltralISO 2. 打开ISO 3. 使用<启动>-<写入磁盘映像> 根据U盘的性能 可能好事 5min-15min左右 4.找到想要安装 ...
- spring cloud实战与思考(五) JWT之携带敏感信息
需求: 需要将一些敏感信息保存在JWT中,以便提高业务处理效率. 众所周知JWT协议RFC7519使用Base64Url对Header和Payload的Json字符串进行编解码.A JWT is re ...
- TortoiseGit连接gitlab,一直要求输入密码
问题背景: 公司使用gitlab作为代码管理平台,安装了TortoiseGit之后,使用正常.但是重启电脑之后,再次使用TortoiseGit操作时总是提醒输入gitlab的账号.如下图: 问题原因: ...
- LOJ117 有源汇有上下界最小流(上下界网络流)
跑出可行流后从原来的汇点向原来的源点跑最大流,原图最小流=inf-maxflow.显然超源超汇的相关边对其也没有影响.原图最小流=可行流-原图新增流量,因为t向s流量增加相当于s向t流量减少.但为什么 ...
- POJ3122-Pie-二分答案
有N个派,F+1个人,每个人分到的体积要相等,而且每个人只能有一块派. 二分答案,对于一个mid,对每个派进行检测,尽量的多分,然后如果份数比F+1大,说明mid可以更大,就把mid给low.注意份数 ...
- 洛谷P4035 [JSOI2008]球形空间产生器(高斯消元)
洛谷题目传送门 球啊球 @xzz_233 qaq 高斯消元模板题,关键在于将已知条件转化为方程组. 可以发现题目要求的未知量有\(n\)个,题目却给了我们\(n+1\)个点的坐标,这其中必有玄机. 由 ...