第1节 flume:9、flume的多个agent串联(级联)
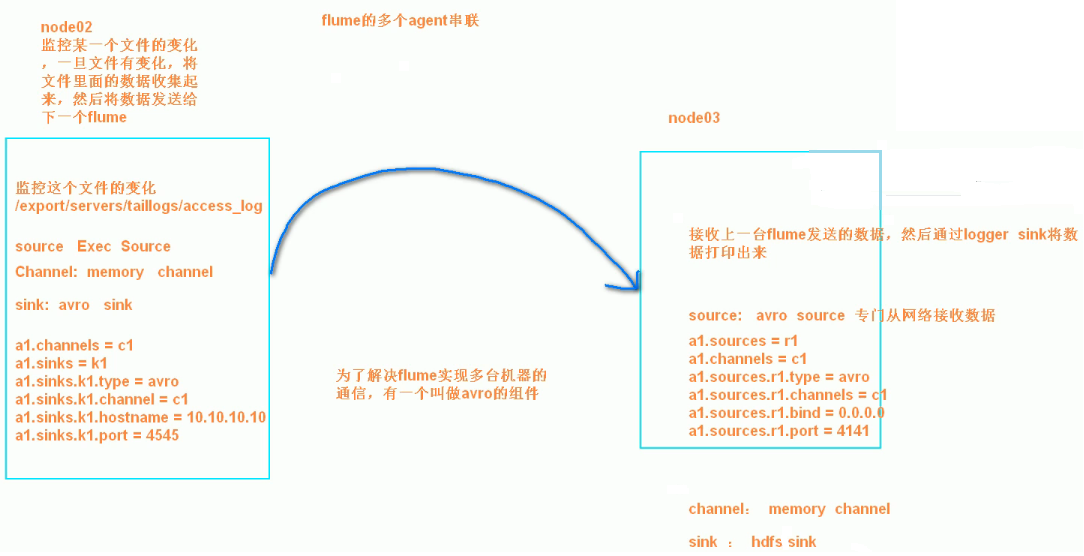
3、两个agent级联

需求分析:
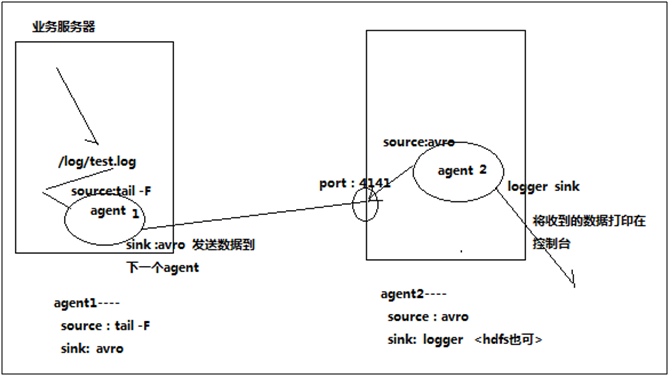
第一个agent负责收集文件当中的数据,通过网络发送到第二个agent当中去,第二个agent负责接收第一个agent发送的数据,并将数据保存到hdfs上面去
第一步:node02安装flume
将node03机器上面解压后的flume文件夹拷贝到node02机器上面去
cd /export/servers
scp -r apache-flume-1.6.0-cdh5.14.0-bin/ node02:$PWD

第二步:node02配置flume配置文件
在node02机器配置我们的flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim tail-avro-avro-logger.conf
##################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access_log
a1.sources.r1.channels = c1
# Describe the sink
##sink端的avro是一个数据发送者
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 192.168.52.120
a1.sinks.k1.port = 4141
a1.sinks.k1.batch-size = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第三步:node02开发脚本文件,往文件写入数据
直接将node03下面的脚本和数据拷贝到node02即可,node03机器上执行以下命令
cd /export/servers
scp -r shells/ taillogs/ node02:$PWD
第五步:node03开发flume配置文件
在node03机器上开发flume的配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim avro-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##source中的avro组件是一个接收者服务
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 192.168.52.120
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:8020/avro/hdfs/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第六步:顺序启动
node03机器启动flume进程
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -c conf -f conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
node02机器启动flume进程
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/
bin/flume-ng agent -c conf -f conf/tail-avro-avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
node02机器启shell脚本生成文件
cd /export/servers/shells
sh tail-file.sh
第1节 flume:9、flume的多个agent串联(级联)的更多相关文章
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Flume篇---Flume安装配置与相关使用
一.前述 Copy过来一段介绍Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制.flume具有高可用, ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- [Flume]使用 Flume 来传递web log 到 hdfs 的例子
[Flume]使用 Flume 来传递web log 到 hdfs 的例子: 在 hdfs 上创建存储 log 的目录: $ hdfs dfs -mkdir -p /test001/weblogsfl ...
- Flume 多个agent串联
多个agent串联 采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联 根据需求,首先定义以下3大要素 第一台flum ...
- 【Flume】Flume基础之安装与使用
1.Flume简介 (1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. (2) Flume基于流式架构,容错性强, ...
- flume到flume消息传递
环境:两台虚拟机( 每台都有flume) 第一台slave作为消息的产生者 第二台master作为消息的接收者 IP(192.168.83.133) 原理:通过监听slave中文件的变化,获取变 ...
- Flume学习——Flume中事务的定义
首先要搞清楚的问题是:Flume中的事务用来干嘛? Flume中的事务用来保证消息的可靠传递. 当使用继承自BasicChannelSemantics的Channel时,Flume强制在操作Chann ...
随机推荐
- 3、HTML的body内标签1
一.特殊符号的表示 #代指空格 < #代指,< > #代指,> ...... #这玩意有很多,记也记不完,用的时候查一下即可: 二.p和br标签 <p>< ...
- Gradle系列之一 Groovy语法精讲
Gradle技术之一 Groovy语法精讲 gradle脚本是基于groovy语言开发的,想要学好gradle必须先要对groovy有一个基本的认识 1. Groovy特点 groovy是一种DSL语 ...
- J20170509-hm
インスペクタ 巡查员 スライス 切片
- hdoj5317【素数预处理】
//这个很好了...虽然是一般.. int isp[1000100]; int p[1000100]; void init() { int sum=0; int i,j; fill(isp,isp+1 ...
- 关于国债的一些计算: 理论TF价格1(缴款日前无付息)
计算 ExpectedTFPrice 是一个比较复杂的计算,我们这里讨论简单的一种情况. 给定一只可交割国债bond(一般为CTD),一个国债期货tf,一个日期t(表示tf的一个交易日期,我们通过t日 ...
- bzoj 1478: Sgu282 Isomorphism && 1815: [Shoi2006]color 有色图【dfs+polya定理】
参考 https://wenku.baidu.com/view/fee9e9b9bceb19e8b8f6ba7a.html?from=search### 的最后一道例题 首先无向完全图是个若干点的置换 ...
- P5166 xtq的口令
传送门 这题要是搞懂在干什么其实不难(虽然某个花了几个小时才搞明白的家伙似乎没资格这么说--) 假设所有人都没有听到老师的命令,我们从左到右考虑,对于当前的人,如果它没有观察者,那么肯定要让它听到老师 ...
- UltraEdit - 怎么显示文件标签栏和侧边栏
显示文件标签栏 view -> views/lists -> open Files Tabs 显示侧边栏 view -> views/lists -> File Tree Vi ...
- Appium问题记录
1.Appium 提示覆盖安装Appium Android Input Manager for Unicode 问题 安卓手机在新版本中Appium 总是提示覆盖安装Appium Android In ...
- 洛谷 P3312 [SDOI2014]数表
式子化出来是$\sum_{T=1}^m{\lfloor}\frac{n}{T}{\rfloor}{\lfloor}\frac{m}{T}{\rfloor}\sum_{k|T}\mu(\frac{T}{ ...