Flume 多个agent串联
多个agent串联
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联
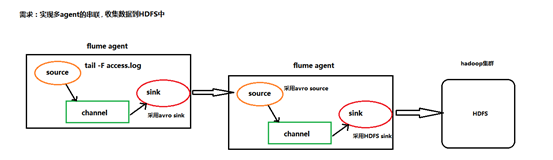
根据需求,首先定义以下3大要素
第一台flume agent
l 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
l 下沉目标,即sink——数据的发送者,实现序列化 : avro sink
l Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
第二台flume agent
l 采集源,即source——接受数据。并实现反序列化 : avro source
l 下沉目标,即sink——HDFS文件系统 : HDFS sink
l Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
配置文件编写:
Flume-agent1:tail-avro-avro-logger.conf
|
#tail-avro-avro-logger.conf # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /home/hadoop/bigdatasoftware/datas/access.log a1.sources.r1.channels = c1 # Describe the sink ##sink端的avro是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop-001 a1.sinks.k1.port = 41414 a1.sinks.k1.batch-size = 10 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
Flume-agent2: avro-hdfs.conf
|
a1.sources = r1 a1.sinks =s1 a1.channels = c1 ##source中的avro组件是一个接收者服务 a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 41414 a1.sinks.s1.type=hdfs a1.sinks.s1.hdfs.path=hdfs://hadoop-001:9000/logs/flume/ a1.sinks.s1.hdfs.filePrefix = access_log a1.sinks.s1.hdfs.batchSize= 100 a1.sinks.s1.hdfs.fileType = DataStream a1.sinks.s1.hdfs.writeFormat =Text a1.sinks.s1.hdfs.rollSize = 10240 a1.sinks.s1.hdfs.rollCount = 1000 a1.sinks.s1.hdfs.rollInterval = 10 a1.sinks.s1.hdfs.round = true a1.sinks.s1.hdfs.roundValue = 10 a1.sinks.s1.hdfs.roundUnit = minute a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.s1.channel = c1 |
输入执行flume指令:
第一个终端:
./bin/flume-ng agent -c conf -f /home/hadoop/bigdatasoftware/flume-1.5.0/conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
第二个终端:
./bin/flume-ng agent -c conf -f /home/hadoop/bigdatasoftware/flume-1.5.0/conf/tail-avro-avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
第三个终端
在/home/hadoop/bigdatasoftware/datas/access.log文件中添加数据
查看hdfs

cat一下

Flume 多个agent串联的更多相关文章
- 第1节 flume:9、flume的多个agent串联(级联)
3.两个agent级联 需求分析: 第一个agent负责收集文件当中的数据,通过网络发送到第二个agent当中去,第二个agent负责接收第一个agent发送的数据,并将数据保存到hdfs上面去 第一 ...
- flume中的agent配置和启动
首先创建一个文件example.conf(touch example.conf) 然后在文件中,进行agent文件的如下的配置(vi example.conf) agent文件的配置:(配置ag ...
- 大数据学习——实现多agent的串联,收集数据到HDFS中
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联 根据需求,首先定义以下3大要素 第一台flume agent l ...
- 大数据入门第十二天——flume入门
一.概述 1.什么是flume 官网的介绍:http://flume.apache.org/ Flume is a distributed, reliable, and available servi ...
- 日志收集框架flume的安装及简单使用
flume介绍 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS.hbase.h ...
- Flume+Morphlines实现数据的实时ETL
转载:http://mp.weixin.qq.com/s/xCSdkQo1XMQwU91lch29Uw Apache Flume介绍: Apache Flume是一个Apache的开源项目,是一个分布 ...
- Flume日志收集系统架构详解--转
2017-09-06 朱洁 大数据和云计算技术 任何一个生产系统在运行过程中都会产生大量的日志,日志往往隐藏了很多有价值的信息.在没有分析方法之前,这些日志存储一段时间后就会被清理.随着技术的发展和 ...
- Apache Flume的介绍安装及简单案例
概述 Flume 是 一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件.Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink).为了保证 ...
- Flume示例
建议参考官方文档:http://flume.apache.org/FlumeUserGuide.html 示例一:用tail命令获取数据,下沉到hdfs 类似场景: 创建目录: mkdir /home ...
随机推荐
- python django 创建虚拟环境
DRF---django-rest-framework: 1.通过一个案例简单回顾一下django, 一.前后端分离,不分离 不分离:前端页面的显示,都是由后端返回的,就是说后端处理了参数,数据库,之 ...
- Day6作业及默写
1.使⽤循环打印以下效果: 1: * ** *** **** ***** for num in range(1,6): print('*' * num) 2: ***** **** *** ** * ...
- python socket 编程之三:长连接、短连接以及心跳(转药师Aric的文章)
长连接:开启一个socket连接,收发完数据后,不立刻关闭连接,可以多次收发数据包. 短连接:开启一个socket连接,收发完数据后,立刻关闭连接. 心跳:长连接在没有数据通信时,定时发送数据包(心跳 ...
- Centos7 zip unzip 安装和使用
安装: yum install -y unzip zip: 解压 unzip filename.zip
- vim3
使用vim编辑多个文件 编辑多个文件有两种形式,一种是在进入vim前使用的参数就是多个文件.另一种是在进入vim后再编辑其他文件. 1. vim 1.txt 2.txt 在命令行模式下输入:n编辑2. ...
- python2和Python3的区别(长期更新)
1.在Python2中无需将打印的内容放在括号内,但是Python3中必须将打印的内容放在括号内,从技术上看Python3中的print是函数. 2.对于用户交互终点额输入input,在python2 ...
- 求割点 割边 Tarjan
附上一般讲得不错的博客 https://blog.csdn.net/lw277232240/article/details/73251092 https://www.cnblogs.com/colle ...
- acm 2072
////////////////////////////////////////////////////////////////////////////////#include<iostream ...
- 《DSP using MATLAB》Problem 5.24-5.25-5.26
代码: function y = circonvt(x1,x2,N) %% N-point Circular convolution between x1 and x2: (time domain) ...
- hdu4549 M斐波那契数列 矩阵快速幂+快速幂
M斐波那契数列F[n]是一种整数数列,它的定义如下: F[0] = aF[1] = bF[n] = F[n-1] * F[n-2] ( n > 1 ) 现在给出a, b, n,你能求出F[n]的 ...