第1节 flume:9、flume的多个agent串联(级联)
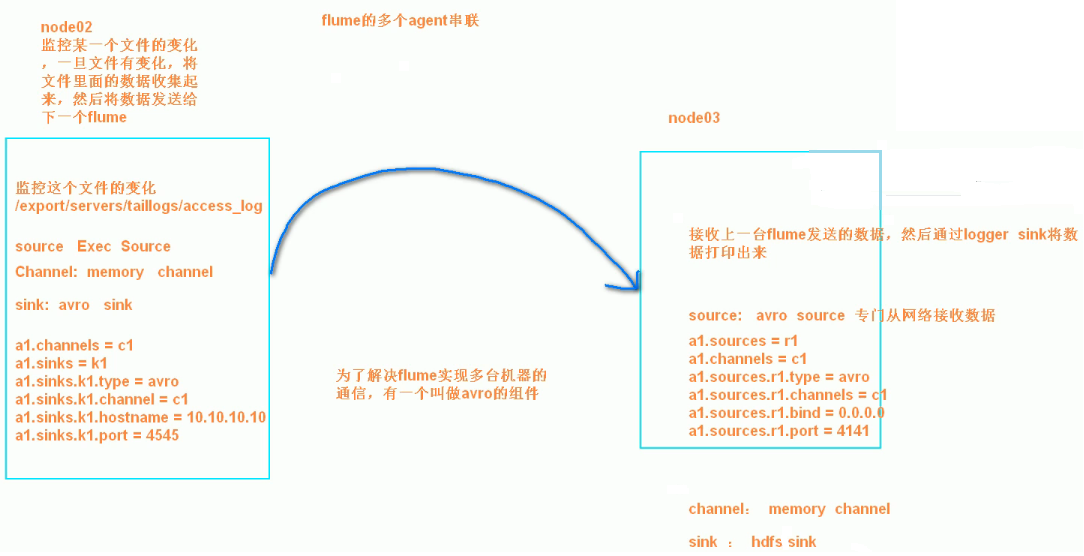
3、两个agent级联
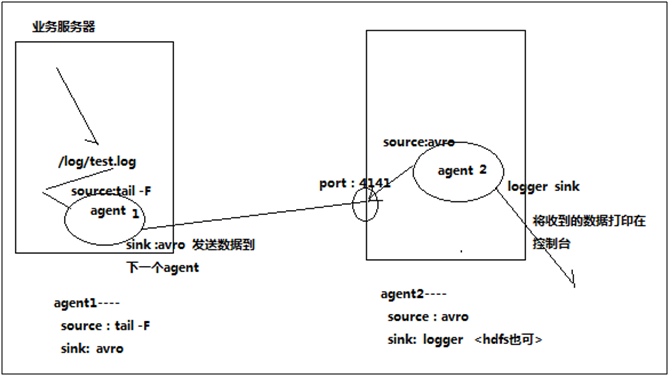

需求分析:
第一个agent负责收集文件当中的数据,通过网络发送到第二个agent当中去,第二个agent负责接收第一个agent发送的数据,并将数据保存到hdfs上面去
第一步:node02安装flume
将node03机器上面解压后的flume文件夹拷贝到node02机器上面去
cd /export/servers
scp -r apache-flume-1.6.0-cdh5.14.0-bin/ node02:$PWD

第二步:node02配置flume配置文件
在node02机器配置我们的flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim tail-avro-avro-logger.conf
##################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access_log
a1.sources.r1.channels = c1
# Describe the sink
##sink端的avro是一个数据发送者
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 192.168.52.120
a1.sinks.k1.port = 4141
a1.sinks.k1.batch-size = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第三步:node02开发脚本文件,往文件写入数据
直接将node03下面的脚本和数据拷贝到node02即可,node03机器上执行以下命令
cd /export/servers
scp -r shells/ taillogs/ node02:$PWD
第五步:node03开发flume配置文件
在node03机器上开发flume的配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim avro-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##source中的avro组件是一个接收者服务
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 192.168.52.120
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:8020/avro/hdfs/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第六步:顺序启动
node03机器启动flume进程
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -c conf -f conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
node02机器启动flume进程
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/
bin/flume-ng agent -c conf -f conf/tail-avro-avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
node02机器启shell脚本生成文件
cd /export/servers/shells
sh tail-file.sh
第1节 flume:9、flume的多个agent串联(级联)的更多相关文章
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Flume篇---Flume安装配置与相关使用
一.前述 Copy过来一段介绍Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制.flume具有高可用, ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- [Flume]使用 Flume 来传递web log 到 hdfs 的例子
[Flume]使用 Flume 来传递web log 到 hdfs 的例子: 在 hdfs 上创建存储 log 的目录: $ hdfs dfs -mkdir -p /test001/weblogsfl ...
- Flume 多个agent串联
多个agent串联 采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联 根据需求,首先定义以下3大要素 第一台flum ...
- 【Flume】Flume基础之安装与使用
1.Flume简介 (1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. (2) Flume基于流式架构,容错性强, ...
- flume到flume消息传递
环境:两台虚拟机( 每台都有flume) 第一台slave作为消息的产生者 第二台master作为消息的接收者 IP(192.168.83.133) 原理:通过监听slave中文件的变化,获取变 ...
- Flume学习——Flume中事务的定义
首先要搞清楚的问题是:Flume中的事务用来干嘛? Flume中的事务用来保证消息的可靠传递. 当使用继承自BasicChannelSemantics的Channel时,Flume强制在操作Chann ...
随机推荐
- Spherical Harmonics Lighting
[转自:http://www.cnblogs.com/daniagger/archive/2012/05/29/2524133.html] 1.背景知识 1.1 光照表示 之前我们都只考虑光源点和物体 ...
- 51nod1163【贪心】
思路: 我们可以说: ①:价值大的不管时间早晚,都可以取,时间较晚的,本身就可以取,那么肯定是大的在前面取,但是在最前面那也是不对的,那么条件就是在规定的时间内,大的就是取了,因为他大,OK. ②:只 ...
- POJ1458【最长公共子序列】
基础DP. #include <iostream> #include <stdio.h> #include <string.h> #include <stac ...
- python __builtins__ int类 (36)
36.'int', 用于将一个字符串或数字转换为整型 class int(object) | int(x=0) -> integer | int(x, base=10) -> intege ...
- Swift @objcMembers
使用@objcMembers关键字,将类中的所有方法暴露给Objc (效果等同于为所有方法加上@objc). 示例代码: @objcMembers class MyController: UIView ...
- Selenium | 基础入门
在maven项目搭建环境: <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifact ...
- WOW.js 动画使用
有的页面在向下滚动的时候,有些元素会产生细小的动画效果.虽然动画比较小,但却能吸引你的注意.比如刚刚发布的 iPhone 6 的页面(查看).如果你希望你的页面也更加有趣,那么你可以试试 WOW.js ...
- 开发原生安卓cordova插件(有原生界面)
上文开发的插件没有调用原生界面,本文介绍开发带有activity的插件 本文很多操作与上文重复,重复部分会省略 首先打开plug1,先开发插件的原生代码 在以下命名空间创建一个activity 名称为 ...
- Qt和Cocoa混合编程
https://el-tramo.be/blog/mixing-cocoa-and-qt/
- 应用-如何使不同的企业使用独自的数据源。使用ejb3.0+jboss6.2EAP+JPA
摘要: 如何使不同的企业使用独自的数据源.使用ejb3.0+jboss6.2EAP+JPA10C应用系统被多个企业同时使用,为了提供个性化服务,如何使不同的企业使用独自的 ...