Hadoop环境搭建|第三篇:spark环境搭建
一、环境搭建
1.1、上传spark安装包
创建文件夹用于存放spark安装文件
命令:mkdir spark
1.2、解压spark安装包
命令:tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C /home/bi/spark
1.3、修改环境变量
命令:vi /etc/profile
修改内容:
export SPARK_HOME=/home/bi/spark/spark-2.1.0-bin-hadoop2.7
export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${SPARK_HOME}/bin
命令:source /etc/profile
1.4、修改相应配置
进入目录conf下:
命令:cp spark-env.sh.template spark-env.sh
命令:vi spark-env.sh
修改内容:
export JAVA_HOME=/home/bi/java/jdk1.8.0_121
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/bi/hadoop/hadoop-2.7.3/etc/hadoop
命令:cp slaves.template slaves
命令:vi slaves
修改内容:(删除localhost)
slave1
slave2
1.5、将spark文件夹复制到slave节点下,并配置环境变量
命令:
scp -r spark bi@slave1:/home/bi/
scp -r spark bi@slave2:/home/bi/
1.6、启动spark
命令:sbin目录
sbin/start-all.sh
二、查看启动结果
命令:jps(master节点)
命令:jps(slave节点)
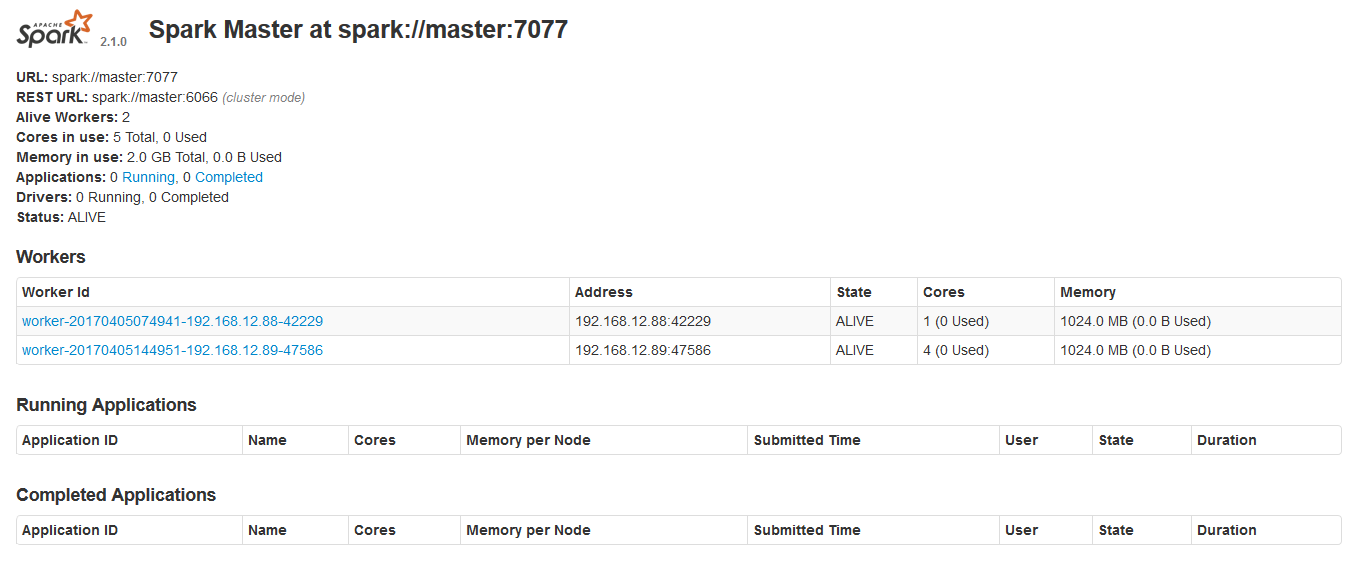
也可以打开界面:192.168.12.80:8080查看节点状态
Hadoop环境搭建|第三篇:spark环境搭建的更多相关文章
- windows下大数据开发环境搭建(4)——Spark环境搭建
一.所需环境 · Java 8 · Python 2.6+ · Scala · Hadoop 2.7+ 二.Spark下载与解压 http://spark.apache.org/downloads.h ...
- .NET持续集成与自动化部署之路第三篇——测试环境到生产环境的一键部署策略(Windows)
Jenkins测试环境到生产环境的一键部署策略(Windows) 一.前言 前面我们已经初步实现了开发集成环境.测试环境的持续集成(自动化构建.自动化测试.自动化部署).但生产环境自动化部署迟 ...
- 第三篇 基于.net搭建热插拔式web框架(重造Controller)
由于.net MVC 的controller 依赖于HttpContext,而我们在上一篇中的沙箱模式已经把一次http请求转换为反射调用,并且http上下文不支持跨域,所以我们要重造一个contro ...
- Spark环境搭建(三)-----------yarn环境搭建及测试作业提交
配置好HDFS之后,接下来配置单节点的yarn环境 1,修改配置文件 文件 : /root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/yarn-site-xml 插入 ...
- [原]项目进阶 之 持续构建环境搭建(三)Maven环境搭建
上次的博文项目进阶 之 持续构建环境搭建(二)Nexus私服器中,我们搭建了一个Nexus的maven私服,这次我们来重点讲解一下Maven的安装和配置.这里说明一下这次的环境搭建,比较基础,但却非常 ...
- 【原】Spring整合Redis(第三篇)—盘点SDR搭建中易出现的错误
易错点01:Spring版本过低导致的错误[环境参数]Redis版本:redis-2.4.5-win32-win64Spring原来的版本:4.1.7.RELEASESpring修改后的版本:4.2. ...
- Redis高可用集群-哨兵模式(Redis-Sentinel)搭建配置教程【Windows环境】
No cross,no crown . 不经历风雨,怎么见彩虹. Redis哨兵模式,用现在流行的话可以说就是一个"哨兵机器人",给"哨兵机器人"进行相应的配置 ...
- Redis集群主从复制(一主两从)搭建配置教程【Windows环境】
如何学会在合适的场景使用合适的技术方案,这值得思考. 由于本地环境的使用,所以搭建一个本地的Redis集群,本篇讲解Redis主从复制集群的搭建,使用的平台是Windows,搭建的思路和Linux上基 ...
- Python pycharm(windows版本)部署spark环境
一 部署本地spark环境 1.1 安装好JDK 下载并安装好jdk1.7,配置完环境变量. 1.2 Spark环境变量配置 去http://spark.apache.o ...
随机推荐
- Opencl 学习笔记
1. HelloWorld
- DRF 01
目录 DRF 接口 概念 YApi接口文档 Postman接口测试 RESTful接口规范 URL设计 响应结果 响应状态码 数据状态码 数据状态信息 数据本身 五大请求方式 简单实现 DRF drf ...
- springboot mvc自动配置(一)自动配置DispatcherServlet和DispatcherServletRegistry
所有文章 https://www.cnblogs.com/lay2017/p/11775787.html 正文 springboot的自动配置基于SPI机制,实现自动配置的核心要点就是添加一个自动配置 ...
- javascript经常用到的函数
trim函数: trim() lTrim() rTrim()校验字符串是否为空: checkIsNotEmpty(str ...
- Linux的关机和重启命令
Linux有如下的关机和重启命令:shutdown, reboot, halt, poweroff,那么它们有什么区别呢? shutdown - 建议使用的命令 shutdown是最常用也是最安全的关 ...
- python matplotlib动态绘图
matplotlib animation的官方文档: http://matplotlib.org/api/animation_api.html 接下来完成一个实时获取cpu数值,并绘图的功能. 1.动 ...
- linux内存管理初学
虚拟内存模型 Linux 内核本身并不运行在虚拟空间中,其使用的是物理寻址模式. 物理内存被分割为界面,一个内存页面的大小由PAGE_SIZE宏决定. 虚拟地址空间的方式使程序员可以将巨大的结构用于连 ...
- tr 命令详细介绍
tr用来从标准输入中对字符进行操作,主要用于删除文件中指定字符.字符转换.压缩文件字符. 我们可以用:tr --help查看一下系统详细介绍 [root@bqh-118 scripts]# tr -- ...
- myeclipse 添加反编译插件
文件下载地址: 链接: https://pan.baidu.com/s/1th2goaA2aS45kO84dX1Bdg 密码: g1fu 先关闭myeclipse1.下载jad1.5.8g 下载后解压 ...
- Xen 虚拟化技术
Xen 是一种开源的.属于类型1(裸金属虚拟化,Baremetal Hypervisor)的虚拟化技术,它使多个同样操作系统或不同操作系统的虚拟机运行在同一个物理主机节点上成为可能并实现. Xen 是 ...