helm安装kafka集群并测试其高可用性
介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
一、KAFKA
体系结构图:

- Producer: 生产者,也就是发送消息的一方。生产者负责创建消息,通过zookeeper找到broker,然后将其投递到 Kafka 中。
- Consumer: 消费者,也就是接收消息的一方。通过zookeeper找对应的broker 进行消费,进而进行相应的业务逻辑处理。
- Broker: 服务代理节点。对于 Kafka 而言,Broker 可以简单地看作一个独立的 Kafka 服务节点或 Kafka 服务实例。大多数情况下也可以将 Broker 看作一台 Kafka 服务器,前提是这台服务器上只部署了一个 Kafka 实例。一个或多个 Broker 组成了一个 Kafka 集群。一般而言,我们更习惯使用首字母小写的 broker 来表示服务代理节点
Send消息流程图:
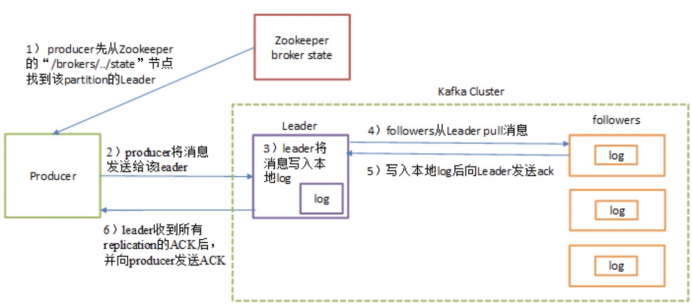
Kafka多副本(Replica)机制:
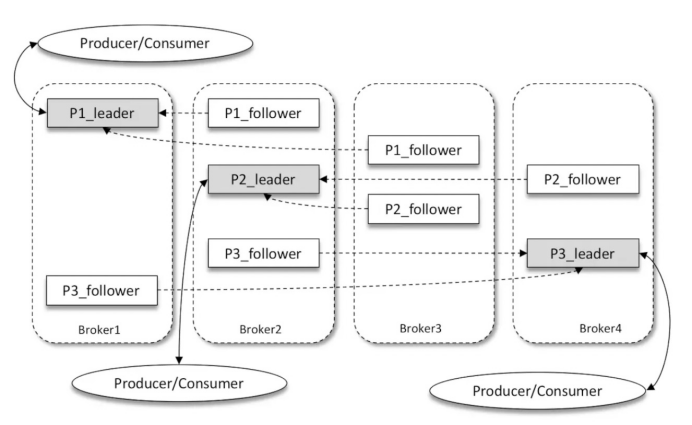
如上图所示,Kafka 集群中有4个 broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个 leader 副本和2个 follower 副本。生产者和消费者只与 leader 副本进行交互,而 follower 副本只负责消息的同步,很多时候 follower 副本中的消息相对 leader 副本而言会有一定的滞后。
二、Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
原理:
高可以用架构图:
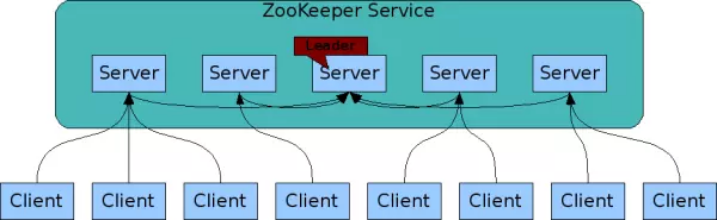
图中每一个Server代表一个安装Zookeeper服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据的一致性。
三、部署kafka&zookeeper集群
我们选择的是官方的chart地址:https://github.com/helm/charts/tree/master/incubator/kafka
1)编写自己的values.yaml文件(注意我的storageClass是已经做好了的nfs存储)
imageTag: "5.2.2"
resources:
limits:
cpu: 2
memory: 4Gi
requests:
cpu: 1
memory: 2Gi
kafkaHeapOptions: "-Xmx2G -Xms2G"
persistence:
enabled: true
storageClass: "managed-nfs-storage"
size: "40Gi"
zookeeper:
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 100m
memory: 536Mi
persistence:
enabled: true
storageClass: "managed-nfs-storage"
size: "10Gi"
2)安装kafka
添加chart仓库:
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
部署
$ helm install --name kafka -f values.yaml incubator/kafka
最后我们能看到:

四、测试kafka高可用性
1)根据提示创建一个测试客户端
apiVersion: v1
kind: Pod
metadata:
name: testclient
namespace: sscp-test
spec:
containers:
- name: kafka
image: solsson/kafka:0.11.0.0
command:
- sh
- -c
- "exec tail -f /dev/null"
Once you have the testclient pod above running, you can list all kafka
topics with:
kubectl -n sscp-test exec testclient -- kafka-topics --zookeeper kafka-test-zookeeper:2181 --list

To create a new topic:
kubectl -n sscp-test exec testclient -- kafka-topics --zookeeper kafka-test-zookeeper:2181 --topic test1 --create --partitions 1 --replication-factor 1

To listen for messages on a topic:
kubectl -n sscp-test exec -ti testclient -- for x in {1..1000}; do echo $x; sleep 2; done | kafka-console-producer --broker-list kafka-test-headless:9092 --topic test1
To stop the listener session above press: Ctrl+C
To start an interactive message producer session:
kubectl -n sscp-test exec -ti testclient -- kafka-console-producer --broker-list kafka-test-headless:9092 --topic test1
To create a message in the above session, simply type the message and press "enter"
To end the producer session try: Ctrl+C
查看topic连接状态
kafka-consumer-groups --bootstrap-server kafka-sit:9092 --describe --group device-group
泄洪命令
kafka-consumer-groups --bootstrap-server kafka-sit:9092 --group device-group --reset-offsets --to-latest --topic transport-device-req --execute
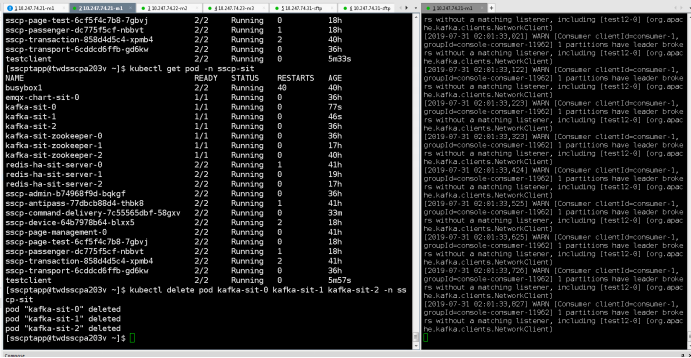
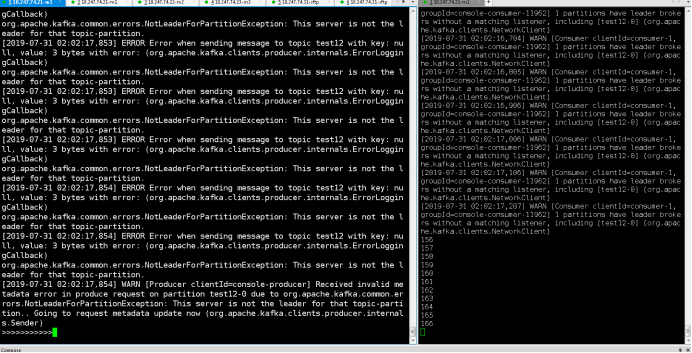
注意:有三个kafka节点,消息要发三个副本才能保持其高可用!!!
五、测试Zookeeper高可用性
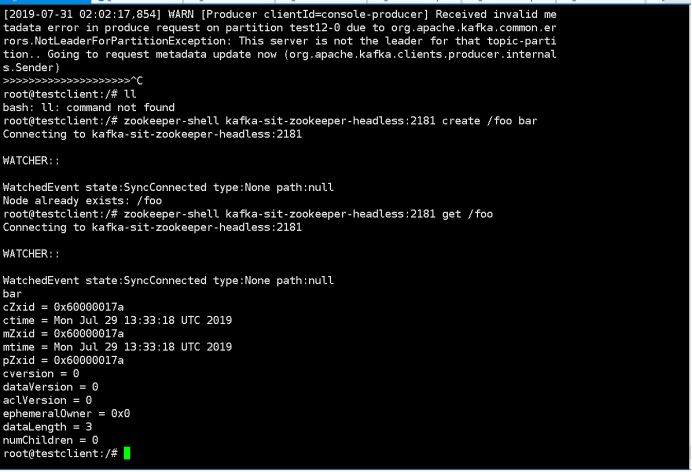
1.Create a node by command below: “kubectl exec -it testclient bash -n sscp-test” “zookeeper-shell kafka-test-zookeeper-headless:2181 create /foo bar” 2. Check zookeeper status Watch existing members:
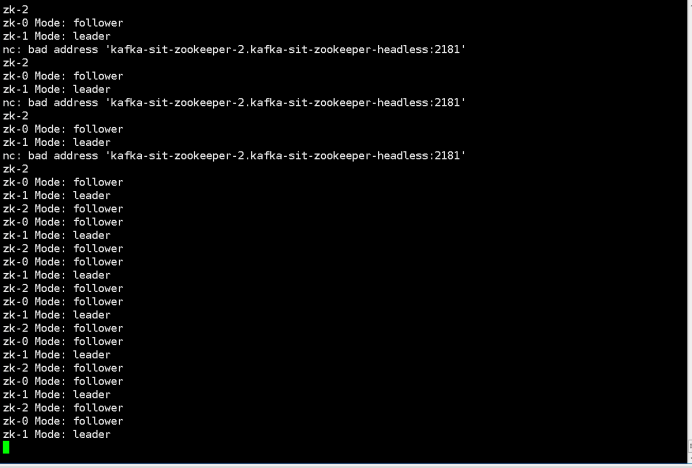
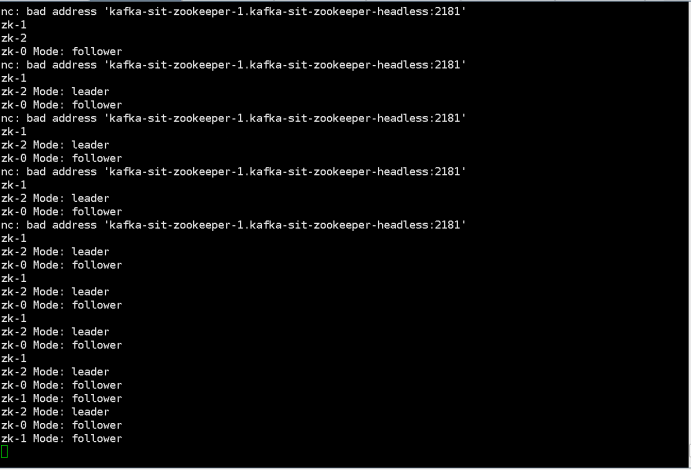
$ kubectl run --attach bbox --image=busybox --restart=Never -- sh -c 'while true; do for i in 0 1 2; do echo zk-${i} $(echo stats | nc kafka-zookeeper-${i}.kafka-zookeeper-headless:2181 | grep Mode); sleep 1; done; done'
zk-2 Mode: follower
zk-0 Mode: follower
zk-1 Mode: leader
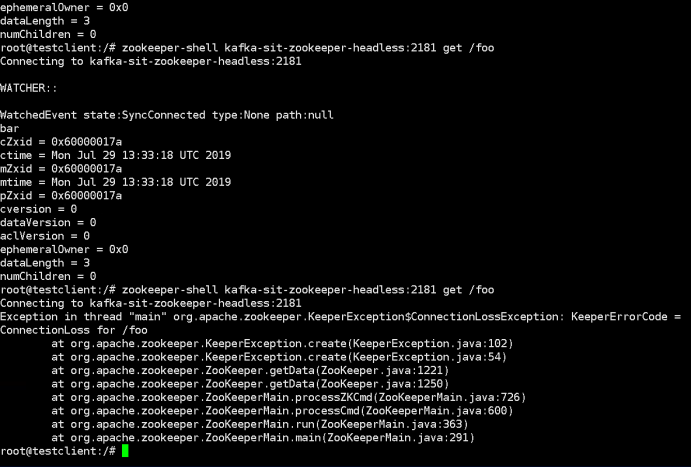
zk-2 Mode: follower 3.kill the leader by command below: “Kubectl delete pod kafka-test-zookeeper-1” 4.Check the previously inserted key by command below: ““kubectl exec -it testclient bash -n sscp-test” “zookeeper-shell kafka-test-zookeeper-headless:2181 get /foo”
helm安装kafka集群并测试其高可用性的更多相关文章
- RedHat6.5安装kafka集群
版本号: Redhat6.5 JDK1.8 zookeeper-3.4.6 kafka_2.11-0.8.2.1 1.软件环境 1.3台RedHat机器,master.slave1. ...
- Centos7.5安装kafka集群
Tags: kafka Centos7.5安装kafka集群 Centos7.5安装kafka集群 主机环境 软件环境 主机规划 主机安装前准备 安装jdk1.8 安装zookeeper 安装kafk ...
- CentOS7 安装kafka集群
1. 环境准备 JDK1.8 ZooKeeper集群(参见本人博文) Scala2.12(如果需要做scala开发的话,安装方法参见本人博文) 本次安装的kafka和zookeeper集群在同一套物理 ...
- 快速安装 kafka 集群
前言 最近因为工作原因,需要安装一个 kafka 集群,目前网络上有很多相关的教程,按着步骤来也能完成安装,只是这些教程都显得略微繁琐.因此,我写了这篇文章帮助大家快速完成 kafka 集群安装. ...
- Centos安装Kafka集群
kafka是LinkedIn开发并开源的一个分布式MQ系统,现在是Apache的一个孵化项目.在它的主页描述kafka为一个高吞吐量的分布式(能 将消息分散到不同的节点上)MQ.在这片博文中,作者简单 ...
- 安装kafka 集群 步骤
1.下载 http://mirror.bit.edu.cn/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz 2.解压 tar -zxvf kafka_2.11-2.1 ...
- 安装kafka集群
1解压tar包 tar -zxvf kafka_2.-.tgz 2.进入config目录 3.配置server.properties文件 # Licensed to the Apache Softwa ...
- CentOS6.5 安装Kafka集群
1.安装zookeeper 参考文档:http://www.cnblogs.com/hunttown/p/5452138.html 2.下载:https://www.apache.org/dyn/cl ...
- kafka集群压力测试--基础。
1.生产者测试 kafka-producer-perf-test.bat --num-records 1000000 --topic test --record-size 200 --throughp ...
随机推荐
- 开源一个好用的nodejs访问mysql类库
一.背景问题 自nodejs诞生以来出现了一大批的web框架如express koa2 egg等等,前端可以不再依赖后端可以自己控制服务端的逻辑.原来的后端开发同学的阵地前端如今同样也写的风生水起,撸 ...
- 阿里百川HotFix2.0热修复初体验
博客原地址:http://blog.csdn.net/allan_bst/article/details/72904721 一.什么是热修复 热修复说白了就是"打补丁",比如你们公 ...
- C#4.0新增功能03 泛型中的协变和逆变
连载目录 [已更新最新开发文章,点击查看详细] 协变和逆变都是术语,前者指能够使用比原始指定的派生类型的派生程度更大(更具体的)的类型,后者指能够使用比原始指定的派生类型的派生程度更小(不太具体 ...
- [leetcode] 19. Remove Nth Node From End of List (Medium)
原题链接 删除单向链表的倒数第n个结点. 思路: 用两个索引一前一后,同时遍历,当后一个索引值为null时,此时前一个索引表示的节点即为要删除的节点. Runtime: 13 ms, faster t ...
- django中ORM的model对象和querryset 简单解析
欢迎大家查看我的博客,我会不定时的用大白话发一些看了就能懂的文章,大家多多支持!如您对此文章内容有独特见解,欢迎与笔者练习一起探讨学习!原创文创!转载请注明出处! ORM是干嘛的? 介绍orm之前我应 ...
- JavaSE总结(一)
一.Java 简介 Java是由Sun Microsystems公司于1995年5月推出的Java面向对象程序设计语言和Java平台的总称.由James Gosling和同事们共同研发,并在1995年 ...
- Spring还可以这样用缓存,你知道吗?
大家在项目开发过程中,或多或少都用过缓存,为了减少数据库的压力,把数据放在缓存当中,当访问的请求过来时,直接从缓存读取.缓存一般都是基于内存的,读取速度比较快,市面上比较常见的缓存有:memcache ...
- 0728 history
-- :: cd /etc/yum.repos.d/ -- :: wget http://download.virtualbox.org/virtualbox/rpm/rhel/virtualbox. ...
- 单调栈&单调队列
最近打了三场比赛疯狂碰到单调栈和单调队列的题目,第一,二两场每场各一个单调栈,第三场就碰到单调队列了.于是乎就查各种博客,找单调栈,单调队列的模板题去做,搞着搞着发现其实这两个其实是一回事,只不过利用 ...
- SSM - Mybatis SQL映射文件
MyBatis 真正的力量是在映射语句中.和对等功能的jdbc来比价,映射文件节省很多的代码量.MyBatis的构建就是聚焦于sql的. sql映射文件有如下几个顶级元素:(按顺序) cache配置给 ...