Python爬虫教程-使用chardet
Spider-03-使用chardet
继续学习python爬虫,我们经常出现解码问题,因为所有的页面编码都不统一,我们使用chardet检测页面的编码,尽可能的减少编码问题的出现
网页编码问题解决
使用chardet 可以自动检测页面文件的编码格式,但是也有可能出错
需要安装chardet,
如果使用Anaconda环境,使用下面命令:
conda install chardet
如果不是,就自己手动在【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】>【chardet】>【install】
具体操作截图: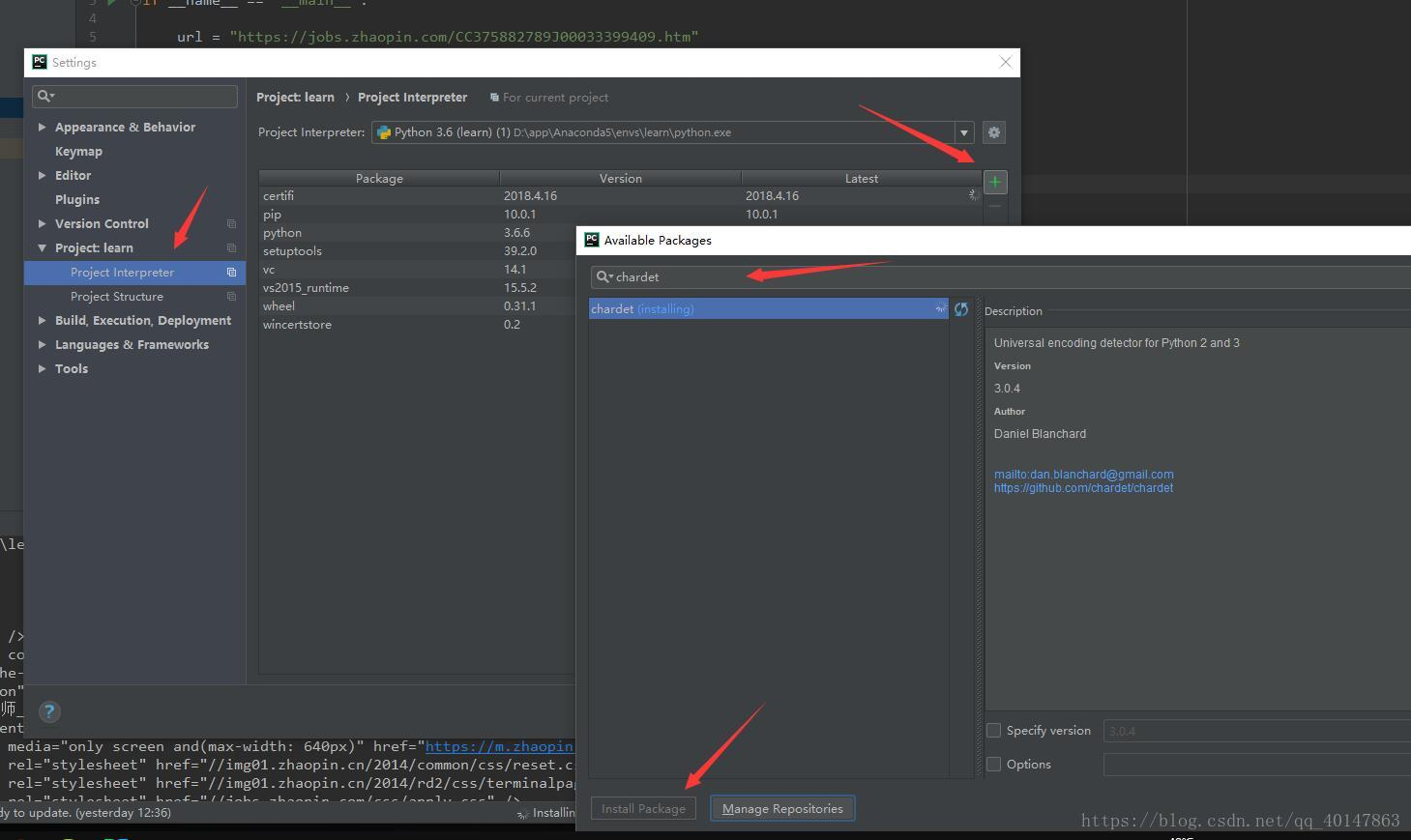
案例v2
- py03chardet.py文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py03chardet.py
# py03chardet.py
# 使用request下载页面,并自动检测页面编码 from urllib import request
import chardet if __name__ == '__main__': url = 'https://jobs.zhaopin.com/CC375882789J00033399409.htm' rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法 html = rsp.read()
cs = chardet.detect(html) print("cs的类型:{0}".format(type(cs)))
print("监测到的cs数据:{0}".format(cs)) html = html.decode(cs.get("encoding", "utf-8"))
# 意思是监测到就使用监测到的,监测不到就使用utf-8 print("HTML页面为:\n%s" % html)
右键运行,截图如下

编码检测就介绍完了,最要的功能是检测页面的编码,尽可能的减少编码问题的出现
如果还有问题未能得到解决,搜索887934385交流群,进入后下载资料工具安装包等。最后,感谢观看!
Python爬虫教程-使用chardet的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- SQL Server 之事务执行,让语句在事务中执行
BEGIN TRAN BEGIN TRY DELETE FROM dbo.表 INSERT INTO dbo.表( Id, 字段....) SELECTId,字段... F ...
- JSON字符串转Map的几种方法
String json = "{"status":0,"result":{"location":{"lng": ...
- Python网络爬虫_Scrapy框架_2.logging模块的使用
logging模块提供日志服务 在scrapy框架中已经对其进行一些操作所以使用更为简单 在Scrapy框架中使用: 1.在setting.py文件中设置LOG_LEVEL(设置日志等级,只有高于等于 ...
- Object对象方法ES5
Object.create(proto,propertiesObject)方法创建一个新对象,使用现有的对象来提供新创建的对象的__proto__. 参数: proto:新创建对象的原型对象. pro ...
- LeetCode 49: 字母异位词分组 Group Anagrams
LeetCode 49: 字母异位词分组 Group Anagrams 题目: 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. Given an array o ...
- Python的生成器和生成器表达式
一,生成器和生成器表达式 什么是生成器,生成器实质就是迭代器,在python中有三种方式来获取生成器: 1. 通过生成器函数 和普通函数没有区别,里面有yield的函数就是生成器函数,生成器函数在执行 ...
- ETCD:词汇表
原文地址:词汇表 本文档定义了etcd文档,命令行和源代码中使用的各种术语. Alarm 每当集群需要操作员干预以保持可靠性时,etcd服务器都会发出警报. Authentication 身份验证管理 ...
- ETCD:运行时重新配置设计
原文地址:the runtime configuration design 运行时重新配置是分布式系统中最难,最容易出错的部分,尤其是在基于共识(像etcd)的系统中. 阅读并学习关于etcd的运行时 ...
- Nginx图片防盗链配置
如果我们自己网站内的图片资源被其它网站所盗用,这会增加自己网站的带宽资源,增加很多额外的消耗,而且会对我们系统的稳定性有影响,为了防止自己网站上的图片资源被其它网站所盗用,我们需要给自己的服务器配置防 ...
- Postman安装出错.NET Framework 4.5 failed to install
正常情况下安装Postman不会出错,联网下载即可,这里的异常是因为环境不允许升级.NET4.5 解决方法:找到Postman的安装文件夹,将postman.exe启动发现可以使用 若没有安装过的文件 ...