「每日五分钟,玩转JVM」:对象内存布局
概览
一个对象根据不同情况可以被划分成两种情况,当对象是一个非数组对象的时候,对象头,实例数据,对齐填充在内存中三分天下,而数组对象中在对象头中多了一个用于描述数组对象长度的部分
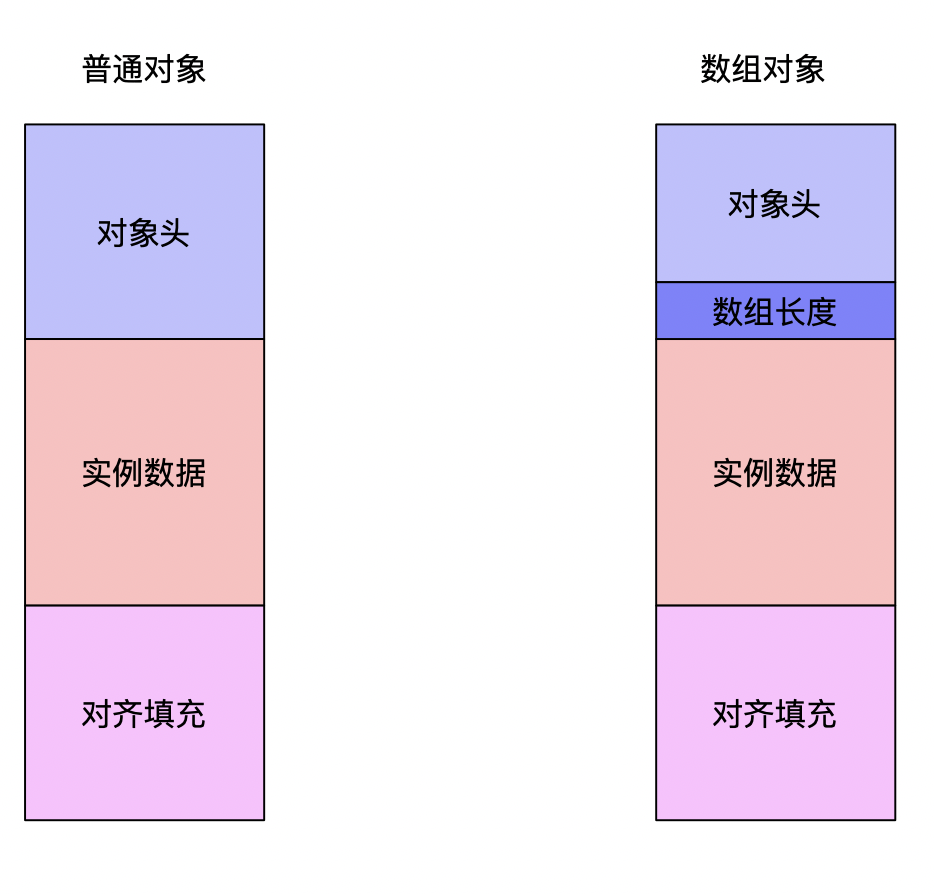
对象头
对象头分为两部分,第一部分称之为"Mark Word",第二部分是用于获取该对象类型的类型指针,如果是数组对象还包括记录数组长度的数据。
在不同的操作系统中,这些区域所占的内存也不同,在32位的系统中,MarkWord占用32bit的空间(也就是4字节)。类型指针和数组长度数据一样合作占用32bit的空间。
在64位的操作系统中,MarkWord占用64bit的空间,类型指针在不开启指针压缩(CompressedOOPs)的情况下是64bit(8 byte),而在开启指针压缩的情况下,仅剩32bit(4 byte)

Mark Word
这一部分存储的是对象自身的运行时数据,这一块儿内容的数据结构并不固定,它会根据对象的状态复用自己的存储空间,
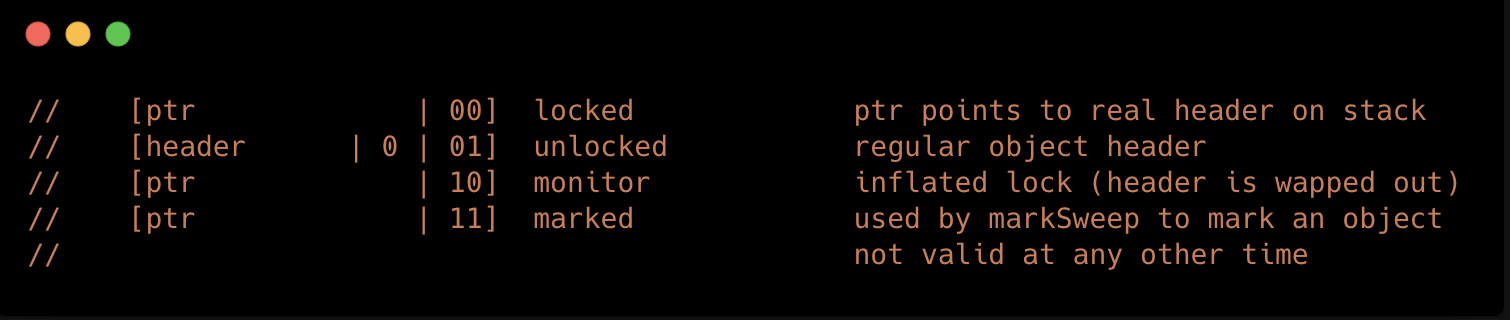
这是摘自markOop.hpp文件中的片段,其中表示了对象的以下五种状态:
| 标志位 | 偏向锁标识位 | 状态 |
|---|---|---|
| 01 | 0 | 无锁 |
| 01 | 1 | 偏向锁 |
| 00 | 无 | 轻量级锁 |
| 10 | 无 | 重量级锁 |
| 11 | 无 | GC Mark |
我们接下来接着去看MarkWord的结构:
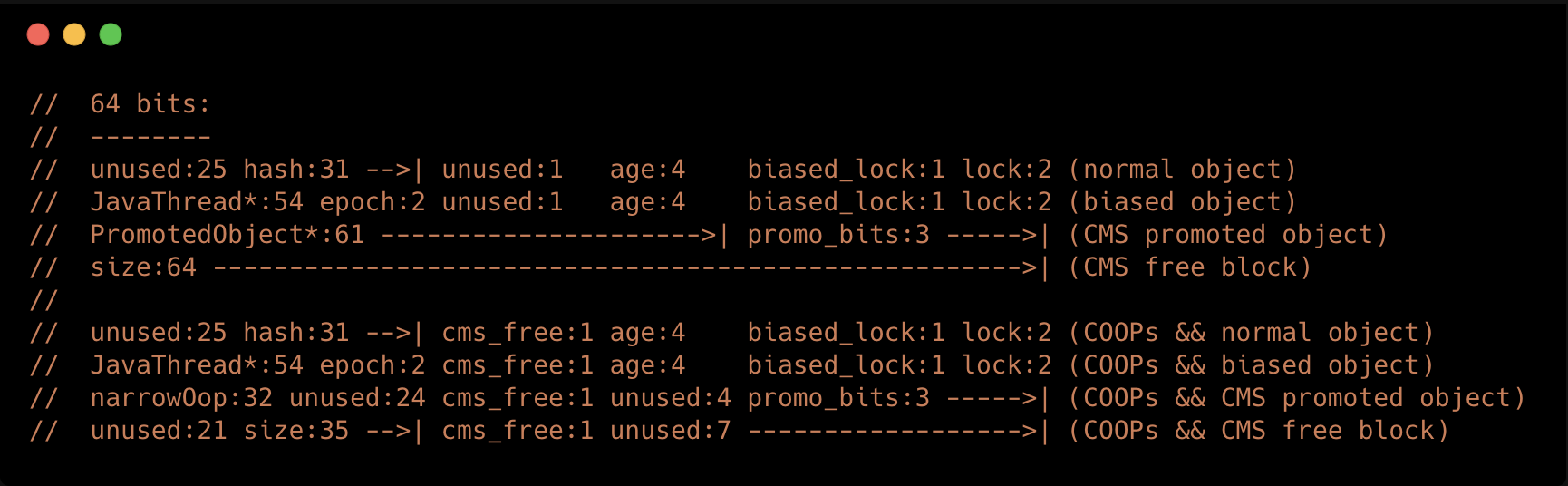
在这里我们可以看到,初始化的时候只是定义了无锁和偏向锁状态的结构(上半部分是没有开启COOPs-指针压缩的结构,下半部分是开启了指针压缩的结构),
当处于轻量级锁、重量级锁时,记录的对象指针,根据JVM的说明,此时认为指针仍然是64位,最低两位假定为0;当处于偏向锁时,记录的为获得偏向锁的线程指针,该指针也是64位;

更多的内容我们就不再这里扩展了,根据反馈的情况,我会在后面并发编程中单开一篇来聊聊锁的进化之路。
类型指针
这个东西有时候会用到去确定该对象属于哪个类的实例,也有用不到的时候,这个要根据不同的虚拟机对于对象的定位实现算法的选择来进行(比如HotSpot JVM就使用该类型指针去获取该对象类型数据)
实例数据
实例数据是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容,这里的字段内容不仅仅包括当前类的字段,也包括他的父类中所定义的字段。
这部分的存储规则遵循虚拟机分配策略参数和字段在Java源码中的定义顺序,HotSpot JVM默认的分配策略是long/double, int,short/char,byte/boolean,oops(普通对象指针,Ordinary Object Pointers)也可以理解为reference,关于指针压缩我们下节去说。
这里需要注意,在父类中定义的变量会出现在子类前,但是我们可以通过将CompactFileds参数设置为true,将子类中较小的变量插入到父类大变量的空隙中。

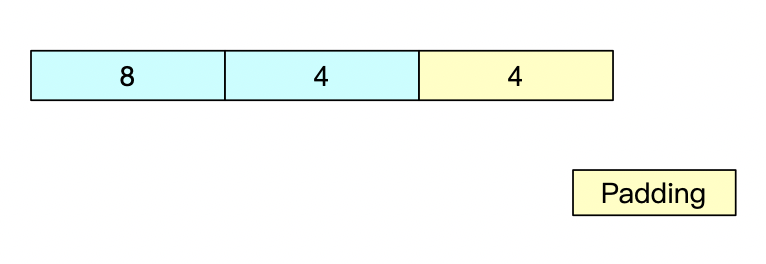
对齐填充
这部分内容并不是必须存在的,因为Hot Spot JVM中规定了对象的大小必须是8字节的整数倍,在C/C++中类似的功能被称之为内存对齐,内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
内存对齐遵循两个规则:
假设第一个成员的起始地址为0,每个成员的起始地址(startpos)必须是其数据类型所占空间大小的整数倍
结构体的最终大小必须是其成员(基础数据类型成员)里最大成员所占大小的整数倍。
这里也就不难理解为什么JVM规定对象的大小必须是8字节的整数倍了,因为在64位系统下(不开启指针压缩),对象中存在很多占用8 byte的数据类型。但是同时也存在一些4 byte的数据类型,这时我们的Padding就起到了作用,去补充不满8 byte的部分,凑齐8的整数倍。
公众号

「每日五分钟,玩转JVM」:对象内存布局的更多相关文章
- 「每日五分钟,玩转JVM」:线程共享区
前言 上一篇中,我们了解了JVM中的线程独占区,这节课我们就来了解一下JVM中的线程共享区,JVM中的线程共享区是跟随JVM启动时一起创建的,包括堆(Heap)和方法区()两部分,而线程独占区的程序计 ...
- 「每日五分钟,玩转JVM」:对象从哪来
面向对象 众所周知,Java是一门面向对象的高级编程语言,那么现在问题来了,对象从哪来呢?有些人会说通过new关键字来创建一个对象,说的很好,本篇我们就来解密在new一个对象的过程中,JVM都给我们做 ...
- 「每日五分钟,玩转JVM」:线程独占区
前言 如果我们对计算机组成有所了解,那么我们一定会知道在计算机中有一块儿特殊的区域,称之为寄存器,寄存器包括了指令寄存器和程序计数器,这两样位于CPU中,作为程序运行的大脑来控制程序的运行和流转. 而 ...
- 「每日五分钟,玩转 JVM」:GC 概览
前言 GC(Garbage Collection)是我们在学习 JVM 的过程中不可避免的一道坎,接下来,我们就来系统的学习一下 GC. 做一件事情之前,我们一定要去知道我们为什么要去做,这里不仅仅指 ...
- 「每日五分钟,玩转JVM」:指针压缩
64位JVM和32位JVM 最初的时候,JVM是32位的,但是随着64位系统的兴起,JVM也迎来了从32位到64位的转换,32位的JVM对比64位的内存容量比较有限,但是我们使用64位虚拟机的同时,也 ...
- 「每日五分钟,玩转JVM」:两种算法
前言 上篇文章,我们了解了GC 的相关概念,这篇文章我们通过两个算法来了解如何去确定堆中的对象实例哪些是我们需要去回收的垃圾对象. 引用计数算法 引用计数法的原理很简单,就是在对象中维护一个计数器,当 ...
- 「每天五分钟,玩转 JVM」:对象访问定位
前言 在「对象内存布局」一节中,我们了解到对象头中包含了一个叫做类型指针的东西,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例.但是,并不是所有的虚拟机都是这么去做的.不 ...
- zookeeper-架构设计与角色分工-《每日五分钟搞定大数据》
本篇文章阅读时间5分钟左右 点击看<每日五分钟搞定大数据>完整思维导图 zookeeper作为一个分布式协调系统,很多组件都会依赖它,那么此时它的可用性就非常重要了,那么保证可用性的同 ...
- zookeeper核心-zab协议-《每日五分钟搞定大数据》
上篇文章<paxos与一致性>说到zab是在paxos的基础上做了重要的改造,解决了一系列的问题,这一篇我们就来说下这个zab. zab协议的全称是ZooKeeper Atomic Bro ...
随机推荐
- selenium定时签到程序
selenium定时签到程序 定时任务 # -*- coding: utf-8 -*- import time import os import sched import datetime from ...
- Log4j 2 配置
版本区别 Log4j 2 与 log4j 1.x 最大的区别在于,新版本的 log4j 2 只支持 json 与 xml,不再支持以前的 properties 资源文件 下载 log4j 的jar 包 ...
- 算法与数据结构基础 - 字典树(Trie)
Trie基础 Trie字典树又叫前缀树(prefix tree),用以较快速地进行单词或前缀查询,Trie节点结构如下: //208. Implement Trie (Prefix Tree)clas ...
- Linux系统与程序监控工具atop教程
引言 Linux以其稳定性,越来越多地被用作服务器的操作系统(当然,有人会较真地说一句:Linux只是操作系统内核:).但使用了Linux作为底层的操作系统,是否我们就能保证我们的服务做到7*24地稳 ...
- windows server2012 nVME和网卡等驱动和不识别RAID10问题
安装2012---不识别M.2 nVME,下官方驱动,注入到系统里 缺多驱动---用ITSK万能驱动添加:|Win8012R2.x64(可解决不支持操作系统,win10与server2012R2通用) ...
- scrapy xpath用法
一.实验环境 1.Windows7x64_SP1 2.anaconda3 + python3.7.3(anaconda集成,不需单独安装) 3.scrapy1.6.0 二.用法举例 1.开启scrap ...
- laya2d 与 cad 之间的坐标转换
坐标系基本概念 直角坐标系可分为左手坐标系与右手坐标系,cad 中用到的是右手坐标系, Laya2D 中用到的是左手坐标系, Laya3D 中使用右手坐标系. 那么如何判断二维直角坐标系是左手还是右手 ...
- Python 參考網站
Python 3 Readiness : http://py3readiness.org/ Python Speed Center : https://speed.python.org/ Python ...
- 性能测试学习第四天-----loadrunner:jdbc批量制造测试数据 & controller应用
Javavuser协议 1.过程概述:在eclipse中用java编写sql执行脚本,复制到lr中,调整后通过参数化迭代批量制造测试数据: 2.步骤: 1).在eclipse中新建java proje ...
- Zabbix-Web监控介绍篇
一.Web监控需求 监控一台Zabbix 3.0的WEB服务是否正常,包括登陆页,登陆后页面,退出页面 ps:zabbix的WEB监控可以实现登录后监控 二.监控环境介绍 监控服务器版本:zabbix ...