prometheus学习系列五: Prometheus配置文件
在prometheus监控系统,prometheus的职责是采集,查询和存储和推送报警到alertmanager。本文主要介绍下prometheus的配置文件。
全局配置文件简介
默认配置文件
[root@node00 prometheus]# cat prometheus.yml.default
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s). # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'. static_configs:
- targets: ['localhost:9090']
- global: 此片段指定的是prometheus的全局配置, 比如采集间隔,抓取超时时间等。
- rule_files: 此片段指定报警规则文件, prometheus根据这些规则信息,会推送报警信息到alertmanager中。
- scrape_configs: 此片段指定抓取配置,prometheus的数据采集通过此片段配置。
- alerting: 此片段指定报警配置, 这里主要是指定prometheus将报警规则推送到指定的alertmanager实例地址。
- remote_write: 指定后端的存储的写入api地址。
- remote_read: 指定后端的存储的读取api地址。
global片段主要参数
# How frequently to scrape targets by default.
[ scrape_interval: <duration> | default = 1m ] # 抓取间隔 # How long until a scrape request times out.
[ scrape_timeout: <duration> | default = 10s ] # 抓取超时时间 # How frequently to evaluate rules.
[ evaluation_interval: <duration> | default = 1m ] # 评估规则间隔 # The labels to add to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels: # 外部一些标签设置
[ <labelname>: <labelvalue> ... ]
scrapy_config片段主要参数
一个scrape_config 片段指定一组目标和参数, 目标就是实例,指定采集的端点, 参数描述如何采集这些实例, 主要参数如下
- scrape_interval: 抓取间隔,默认继承global值。
- scrape_timeout: 抓取超时时间,默认继承global值。
- metric_path: 抓取路径, 默认是/metrics
- scheme: 指定采集使用的协议,http或者https。
- params: 指定url参数。
- basic_auth: 指定认证信息。
- *_sd_configs: 指定服务发现配置
- static_configs: 静态指定服务job。
- relabel_config: relabel设置。
static_configs样例
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'. static_configs:
- targets: ['localhost:9090']
- job_name: "node"
static_configs:
- targets:
- "192.168.100.10:20001"
- "192.168.100.11:20001
- "192.168.100.12:20001"
file_sd_configs样例
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'. static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml" # 独立文件配置如下
cat conf/node-dis.conf
- targets:
- "192.168.100.10:20001"
- "192.168.100.11:20001"
- "192.168.100.12:20001" 或者可以这样配置
[root@node00 conf]# cat node-dis.yml
- targets:
- "192.168.100.10:20001"
labels:
hostname: node00
- targets:
- "192.168.100.11:20001"
labels:
hostname: node01
- targets:
- "192.168.100.12:20001"
labels:
hostname: node02
通过file_fd_files 配置后我们可以在不重启prometheus的前提下, 修改对应的采集文件(node_dis.yml), 在特定的时间内(refresh_interval),prometheus会完成配置信息的载入工作。
consul_sd_file样例
由于consul的配置需要有consul的服务提供, 这里简单部署下consul的服务。
# 进入下载目录
[root@node00 prometheus]# cd /usr/src/
# 下载
[root@node00 src]# wget https://releases.hashicorp.com/consul/1.6.1/consul_1.6.1_linux_amd64.zip
# 解压
[root@node00 src]# unzip consul_1..1_linux_amd64.zip
Archive: consul_1..1_linux_amd64.zip
inflating: consul
# 查看
[root@node00 src]# ls
consul consul_1..1_linux_amd64.zip debug kernels node_exporter-0.18..linux-amd64.tar.gz prometheus-2.12..linux-amd64.tar.gz
# 查看文件类型
[root@node00 src]# file consul
consul: ELF -bit LSB executable, x86-, version (SYSV), statically linked, not stripped
# 防止到系统bin目录
[root@node00 src]# mv consul /usr/local/bin/
# 确保环境变量包含
[root@node00 src]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# 运行测试
[root@node00 consul.d]# consul agent -dev
# 测试获取成员
[root@node00 ~]# consul members
# 创建配置目录
[root@node00 ~]#mkdir /etc/consul.d
[root@node00 consul.d]# cat prometheus-node.json
{
"addresses": {
"http": "0.0.0.0",
"https": "0.0.0.0"
},
"services": [{
"name": "prometheus-node",
"tags": ["prometheus","node"],
"port": 20001
}]
}
# 指定配置文件运行
consul agent -dev -config-dir=/etc/consul.d
打开web管理界面 192.169.100.10:8500,查看相应的服务信息。

上面我们可以看到有2个service , 其中prometheus-node是我们定义的service。
和prometheus集成样例:
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090'] - job_name: "node"
consul_sd_configs:
- server: localhost:8500
services:
- prometheus-node
# tags:
# - prometheus
# - node
#- refresh_interval: 1m
在prometheus的target界面上我们看到服务注册发现的结果。
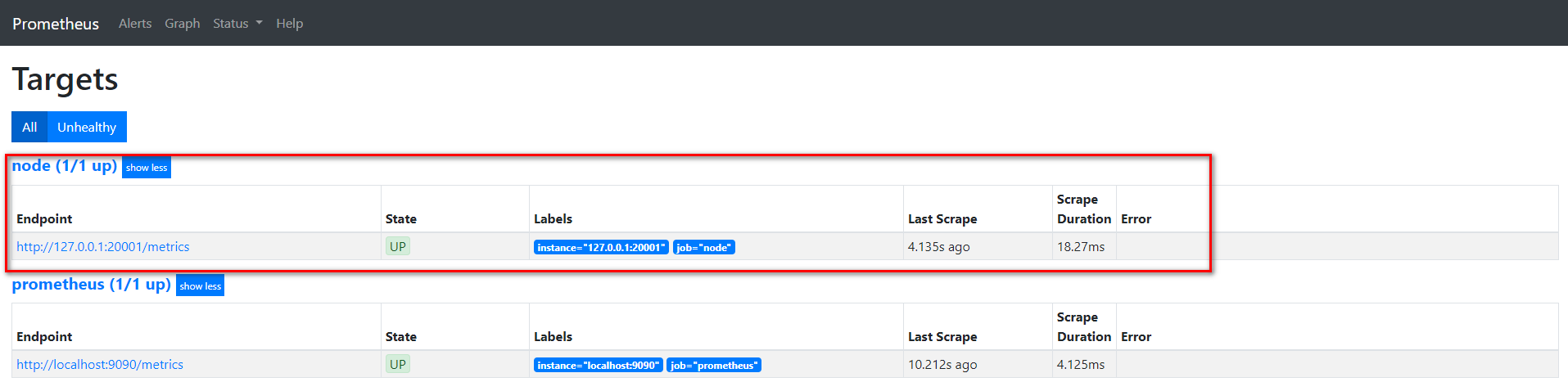
我们通过api接口给该service添加一个节点, 看看是否可以同步过来。
[root@node00 ~]# curl -XPUT -d@node01.json 127.0.0.1:8500/v1/catalog/register
true
[root@node00 ~]# cat node01.json
{
"id":"0cc931ea-9a3a-a6ff-3ef5-e0c99371d77d",
"Node": "node01",
"Address": "192.168.100.11",
"Service":
{
"Port": 20001,
"ID": "prometheus-node",
"Service": "prometheus-node"
}
}
在consul和prometheus中查看


可以发现通过向consul中特定服务加入节点, 就可以在prometheus动态变动采集的实例地址。
prometheus学习系列五: Prometheus配置文件的更多相关文章
- scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Prometheus学习系列(五)之Prometheus 规则(rule)、模板配置说明
前言 本文来自Prometheus官网手册1.2.3.4和 Prometheus简介1.2.3.4 记录规则 一.配置规则 Prometheus支持两种类型的规则,这些规则可以定期配置,然后定期评估: ...
- Prometheus学习系列(六)之Prometheus 查询说明
前言 本文来自Prometheus官网手册和 Prometheus简介 Prothetheus查询 Prometheus提供一个函数式的表达式语言PromQL (Prometheus Query La ...
- Prometheus学习系列(二)之Prometheus FIRST STEPS
前言 本文来自Prometheus官网手册 和 Prometheus简介 说明 Prometheus是一个监控平台,通过在监控目标上的HTTP端点来收集受监控目标的指标.本指南将向您展示如何使用Pro ...
- Prometheus学习系列(九)之Prometheus 联盟、迁移
前言 本文来自Prometheus官网手册 和 Prometheus简介 FEDERATION 允许Prometheus服务器从另一台Prometheus服务器抓取选定的时间序列. 一,用例 联盟有不 ...
- prometheus学习系列九: Prometheus AlertManager使用
在Prometheus的报警系统中,是分为2个部分的, 规则是配置是在prometheus中的, prometheus组件完成报警推送给alertmanager的, alertmanager然后管理这 ...
- prometheus学习系列三:node_exporter安装部署
node_exporter简介 node_exporter安装部署 [root@node00 ~]# cd /usr/src/ [root@node00 src]# wget https://gith ...
- prometheus学习系列二: Prometheus安装
下载 在prometheus的官网的download页面,可以找到prometheus的下载二进制包. [root@node00 src]# cd /usr/src/ [root@node00 src ...
- Prometheus学习系列(一)之Prometheus简介
前言 本文来自Prometheus官网手册 和 Prometheus简介 什么是prometheus? Prometheus是一个最初在SoundCloud上构建的开源系统监视和警报工具包.自2012 ...
随机推荐
- ZROI 暑期高端峰会 A班 Day4 生成函数
一般生成函数 很普及组,不讲了 生成函数是一种形式幂级数,也就是我们只关心系数,不关心未知数具体的值. 比如 \(\sum\limits_{i\ge 0}x^i=\frac{1}{1-x}\).虽然只 ...
- java 集合运算
package testjavapro; import java.util.BitSet; public class testjavaa { public static void main(Strin ...
- 第10组 Beta版本演示
一.小组信息 组长博客链接 组名:凹秃曼 组内成员 学号 组员 031702240 童景霖(组长) 031702225 叶泽林 031702246 陈鸿立 031702201 万本琳 03170222 ...
- UDF——文件编码造成UDF编译失败
有时候我们觉得我们的代码写得很正确的,但是在Fluent当中编译的时候一直编译不通过,提示我们错误,我们根据Fluent当中的错误提示去找到源代码中对应的行,却发现没有错误提示当中的问题,出现这个问题 ...
- [技术博客]使用wx.downloadfile将图片下载到本地临时存储
目录 目标 代码展示 重点讲解 目标 在上一篇技术博客中,我们生成的海报中包含图片,这些图片是存储到服务器上的,而canvas的drawimage函数只能读取本地文件,因此我们在drawCanvas之 ...
- vscode配合less的编译
1.安装Easy LESS插件 2.打开settings.json,添加以下代码: "less.compile": { "sourceMap": true, & ...
- react-native 设置启动模拟器
react-native 设置启动模拟器 查看iOS可选设备: xcrun simctl list devices iPhone7 Plus启动(下次启动会默认使用最后一次选择设备,直接启动npx r ...
- 数据对象如何定义为Java代码示例
想将数据保存为这样子: [{ "subject": { "code": "B123", "words": [{ &quo ...
- StringTable
首先看这样一个面试题 // StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容 public ...
- 哈夫曼树的构建(C语言)
哈夫曼树的构建(C语言) 算法思路: 主要包括两部分算法,一个是在数组中找到权值最小.且无父结点两个结点位置,因为只有无父结点才能继续组成树: 另一个就是根据这两个结点来修改相关结点值. 结构定义 ...