scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表:
scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy01.html
scrapy爬虫学习系列二:scrapy简单爬虫样例学习: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy02.html
scrapy爬虫学习系列三:scrapy部署到scrapyhub上: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_004_scrapyhub.html
scrapy爬虫学习系列四:portia的学习入门: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_010_scrapy04.html
scrapy爬虫学习系列五:图片的抓取和下载: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_011_scrapy05.html
scrapy爬虫学习系列六:官方文档的学习: https://github.com/zhaojiedi1992/My_Study_Scrapy
注意: 我自己新建的一个QQ群(新建的),欢迎大家加入一起学习一起进步 ,群号646187336
这篇文章主要对一个车标网(http://car.bitauto.com/qichepinpai)的图片进行抓取,并按照图片的alt属性值去设置输出图片命名。
本文的最终源码下载地址(github):https://github.com/zhaojiedi1992/caricon
1.创建工程和爬虫
C:\Users\Administrator>e: E:\>cd scrapytest E:\scrapytest>scrapy startproject caricon
New Scrapy project 'caricon', using template directory 'C:\\Program Files\\Anaconda3\\lib\\site-packages\\scrapy\\templa
tes\\project', created in:
E:\scrapytest\caricon You can start your first spider with:
cd caricon
scrapy genspider example example.com E:\scrapytest>cd caricon E:\scrapytest\caricon>scrapy genspider car car.bitauto.com/qichepinpai
Created spider 'car' using template 'basic' in module:
caricon.spiders.car
4.修改item
添加字段,修改后为如下内容:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class CariconItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
alt = scrapy.Field()
- image_urls : 作为项目的图片网址(需要我们指定url)。
- images :下载的影像信息(这个字段不是我们填充的)。
注意: 上面的alt字段是我自己加的,image_urls ,images这2个字段是请求图片的默认字段,必须要有的,建议使用默认字段。你要是喜欢折腾可以参考这个网址:https://docs.scrapy.org/en/latest/topics/media-pipeline.html#usage-example
3.修改爬虫
这里我们先使用火狐浏览器的Firefinder插件找找我们需要提取的图片,图片如下:
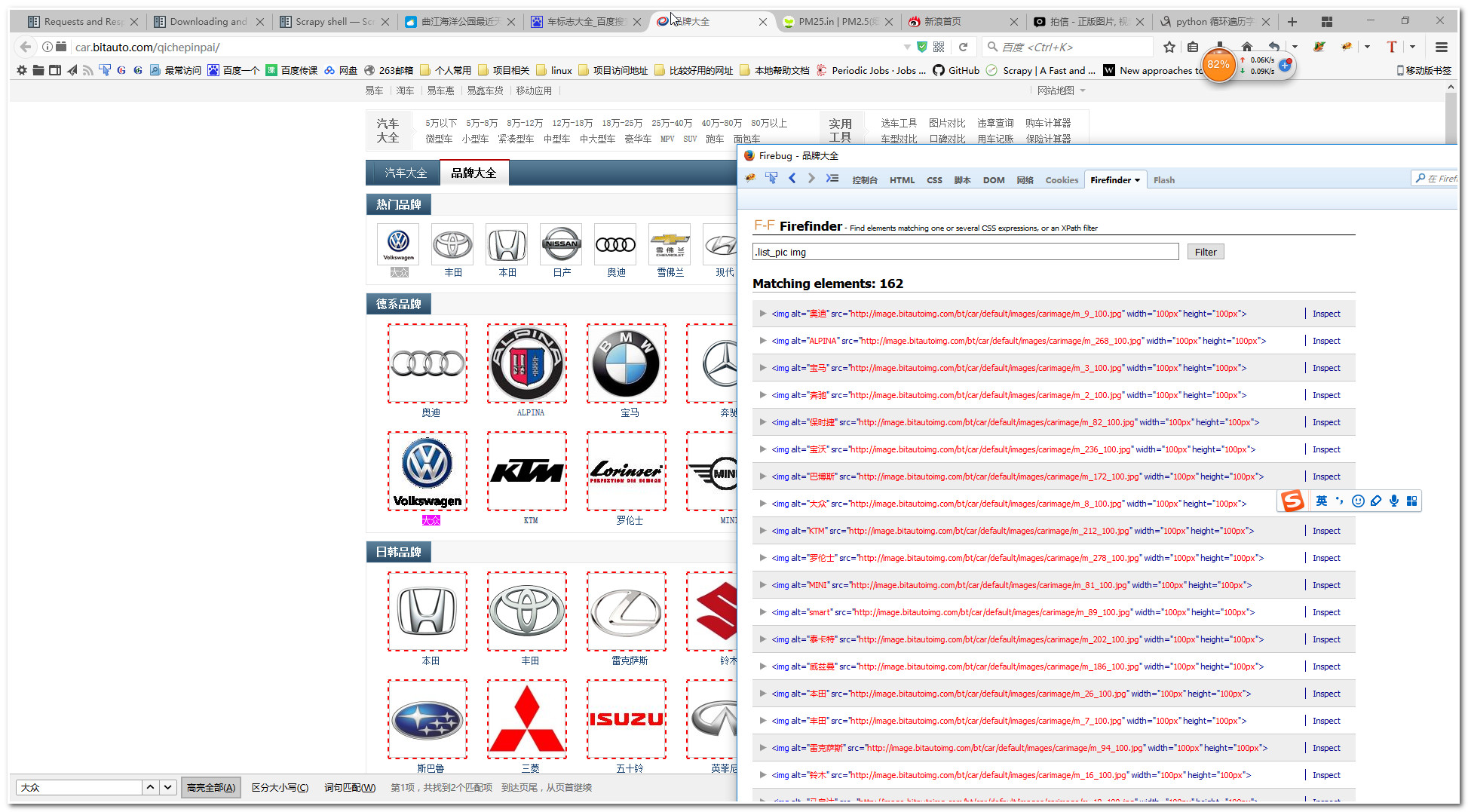
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class CariconPipeline(object):
def process_item(self, item, spider):
return item
from scrapy.contrib.pipeline.images import ImagesPipeline
from scrapy.http import Request
from scrapy.exceptions import DropItem
import os class MyImagesPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
#url_file_name= request.url.split('/')[-1]
#image_guid = hashlib.sha1(to_bytes(url)).hexdigest()
alt_name=request.meta["alt"]
return 'full/%s%s' % (alt_name, os.path.splitext(request.url)[-1]) def get_media_requests(self, item, info):
yield Request(item["image_urls"][0], meta={'alt':item["alt"]})
代码简介:通常我们使用官方的那个imagepipeline导出的文件是SHA1 hash 你的url作为文件名,很难区别啊,这里使用到了request方法的meta参数,把我们的图片的alt属性传递过去,这样我们返回文件名的时候就可以使用这个alt的名字来区别了。(但是如果alt重复又替换了原来的图片的)
注意,firefinder这个插件依赖与firebug的,你可以在你的浏览器找类似firefinder的工具。
6.修改setttings.py文件
修改下面片段为如下内容:
ITEM_PIPELINES = {
'caricon.pipelines.MyImagesPipeline': 300,
}
IMAGES_STORE = r'e:\test\pic\'
当然我们这里可以使用官方的imagepipeline(scrapy.pipelines.images.ImagesPipeline)
6.运行爬虫
E:\scrapytest\caricon>scrapy crawl car
7.查看结果
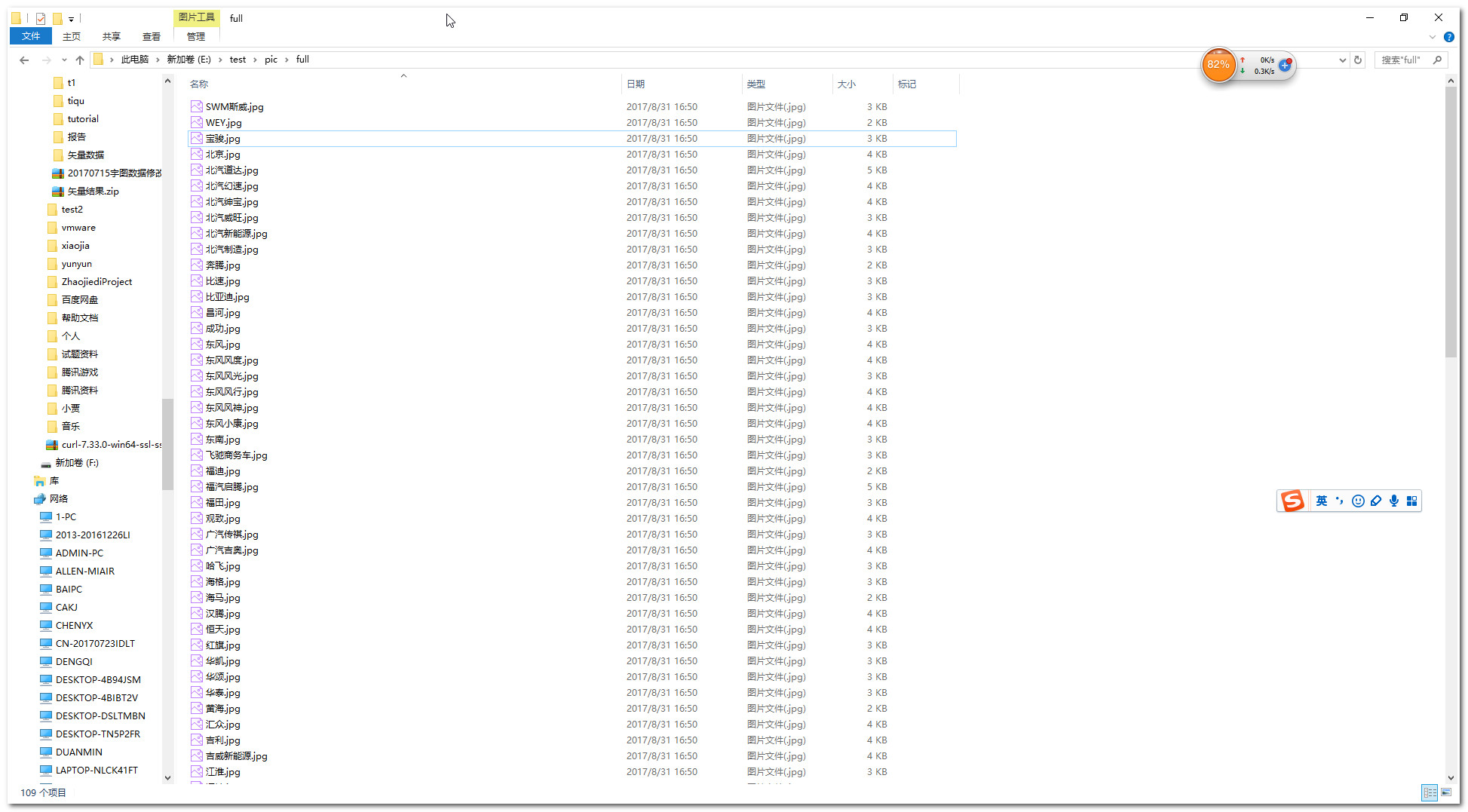
scrapy爬虫学习系列五:图片的抓取和下载的更多相关文章
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列七:scrapy常见问题解决方案
1 常见错误 1.1 错误: ImportError: No module named win32api 官方参考:https://doc.scrapy.org/en/latest/faq.html# ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
随机推荐
- javascript 数据类型 -- 检测
一.前言 在上一篇博文中 Javascript 数据类型 -- 分类 中,我们梳理了 javascript 的基本类型和引用类型,并提到了一些冷知识.大概的知识框架如下: 这篇博文就讲一下在写代码的过 ...
- js 事件模型详解
把js的事件模型,分为两类,DOM0级和DOM2级, DOM0级 通常直接在DOM对象上绑定函数对象,指定事件类型,dom.onClick = function(){};类似于这种写法,移除事件,则直 ...
- python批量提取eml附件
从批量eml文件中提取附件,使用方式如下 代码如下 import email import os import sys #获取eml附件信息 def Get_Annex_Message(FilePat ...
- 【高并发架构】Redis缓存高并发之-主从架构
Redis主从架构 到目前为止,Redis Cluster 能实现很好的性能,但如果只是缓存几个G的数据,那么单机Redis就足够了,但缓存主要用来读的,单机的QPS有一定的极限,一两万QPS一台应该 ...
- 01.在vue中通过 JSONP 方式来跨域
//1.引入 : 在main.js 中引入该文件即可 //2.使用: axios.jsonp('地址').then(res => { // console.log(res) // } impor ...
- 浏览器css隐藏滚动条的方法!除了IE一般都支持
::-webkit-scrollbar { /* 滚动条整体部分 */ width:0px; margin-right:2px}::-webkit-scrollbar-track-piece { /* ...
- win7下配置mysql的my.ini文件
一.环境 操作系统是win7 x64, mysql是5.6.40. 二. 怎么配置? 修改my.ini文件, 添加[client], 在下面加一行 default-character-set=utf8 ...
- Mesos源码分析(2): Mesos Master的启动之一
Mesos Master的启动参数如下: /usr/sbin/mesos-master --zk=zk://127.0.0.1:2181/mesos --port=5050 --log_dir=/va ...
- React Native 断点调试 跨域资源加载出错问题的原因分析
写在前面 ————如果从头开始看还没解决,试试文章最后的绝招 闲来无事,折腾了一下React Native,相比之前,开发体验好了不少.但在真机断点调试那里遇到了跨域资源加载出错的问题,一番探索总算解 ...
- 【安富莱原创开源应用第1期】花式玩转网络摄像头之TCP上位机软件实现,高端大气上档次,速度2MB/S,华丽丽的界面效果
说明:1.例子是两年前做的,一直没有顾上整理出来,今天特地整理出来,开源出来给大家玩.2.上位机是emWin模拟器开发的,大家估计很难猜到,所以你会emWin话的,就可以轻松制作上位机.做些通信和控制 ...