prometheus学习系列三:node_exporter安装部署
node_exporter简介
node_exporter安装部署
[root@node00 ~]# cd /usr/src/
[root@node00 src]# wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
[root@node00 src]# mkdir /usr/local/exporter -pv
mkdir: created directory ‘/usr/local/exporter’
[root@node00 src]# tar xf node_exporter-0.18..linux-amd64.tar.gz -C /usr/local/exporter/
[root@node00 src]# cd /usr/local/exporter/
[root@node00 exporter]# ls
node_exporter-0.18..linux-amd64
[root@node00 exporter]# ln -s node_exporter-0.18..linux-amd64/ node_exporter
node_exporter启动
[root@node00 node_exporter]# ./node_exporter
INFO[] Starting node_exporter (version=0.18., branch=HEAD, revision=3db77732e925c08f675d7404a8c46466b2ece83e) source="node_exporter.go:156"
INFO[] Build context (go=go1.12.5, user=root@b50852a1acba, date=-::) source="node_exporter.go:157"
INFO[] Enabled collectors: source="node_exporter.go:97"
# 中间输出省略
INFO[] Listening on : source="node_exporter.go:170"
测试node_exporter
[root@node00 ~]# curl 127.0.0.1:9100/metrics
# 这里可以看到node_exporter暴露出来的数据。
配置node_exporter开机自启
[root@node00 system]# cd /usr/lib/systemd/system
# 准备systemd文件
[root@node00 systemd]# cat node_exporter.service
[Unit]
Description=node_exporter
After=network.target [Service]
User=prometheus
Group=prometheus
ExecStart=/usr/local/exporter/node_exporter/node_exporter\
--web.listen-address=:\
--collector.systemd\
--collector.systemd.unit-whitelist=(sshd|nginx).service\
--collector.processes\
--collector.tcpstat\
--collector.supervisord
[Install]
WantedBy=multi-user.target
# 启动
[root@node00 exporter]# systemctl restart node_exporter
# 查看状态
[root@node00 exporter]# systemctl status node_exporter
● node_exporter.service - node_exporter
Loaded: loaded (/usr/lib/systemd/system/node_exporter.service; enabled; vendor preset: disabled)
Active: active (running) since Fri -- :: EDT; 5s ago
Main PID: (node_exporter)
CGroup: /system.slice/node_exporter.service
└─ /usr/local/exporter/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(sshd|nginx).service Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - stat" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - systemd" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - textfile" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - time" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - timex" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - uname" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - vmstat" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - xfs" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg=" - zfs" source="node_exporter.go:104"
Sep :: node00 node_exporter[]: time="2019-09-20T22:43:09-04:00" level=info msg="Listening on :9100" source="node_exporter.go:170" # 开机自启
[root@node00 exporter]# systemctl enable node_exporter
配置prometheus采集node信息
修改配置文件
[root@node00 prometheus]# cd /usr/local/prometheus/prometheus
[root@node00 prometheus]# vim prometheus.yml
# 在scrape_configs中加入job node ,最终scrape_configs如下配置
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # metrics_path defaults to '/metrics'
# scheme defaults to 'http'. static_configs:
- targets: ['localhost:9090']
- job_name: "node"
static_configs:
- targets:
- "192.168.100.10:20001" [root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheus
查看集成
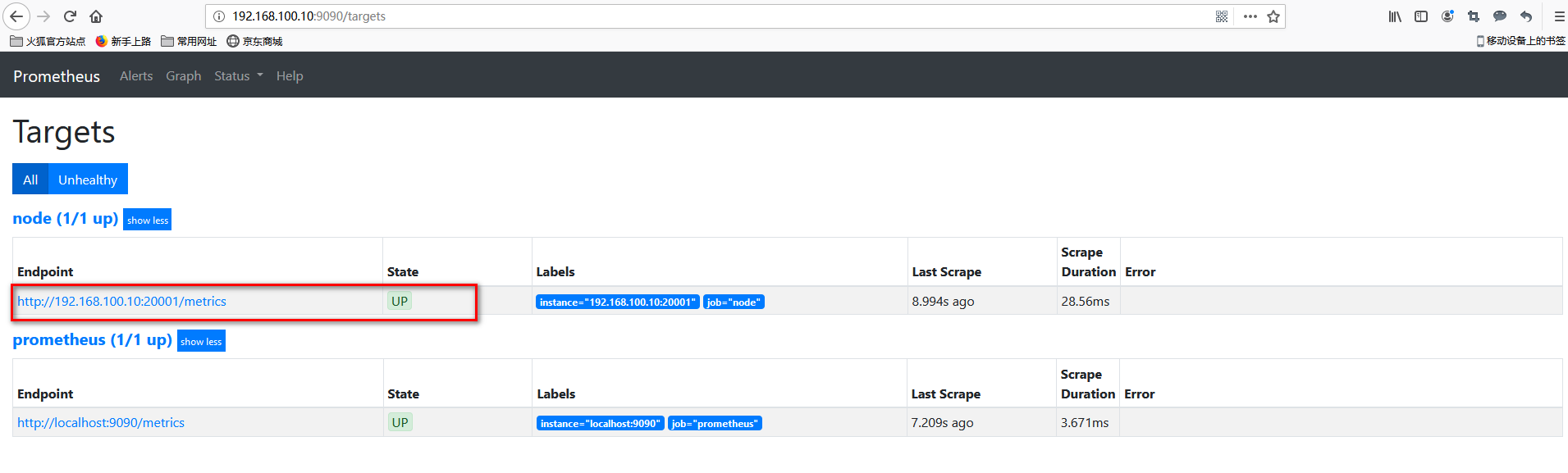
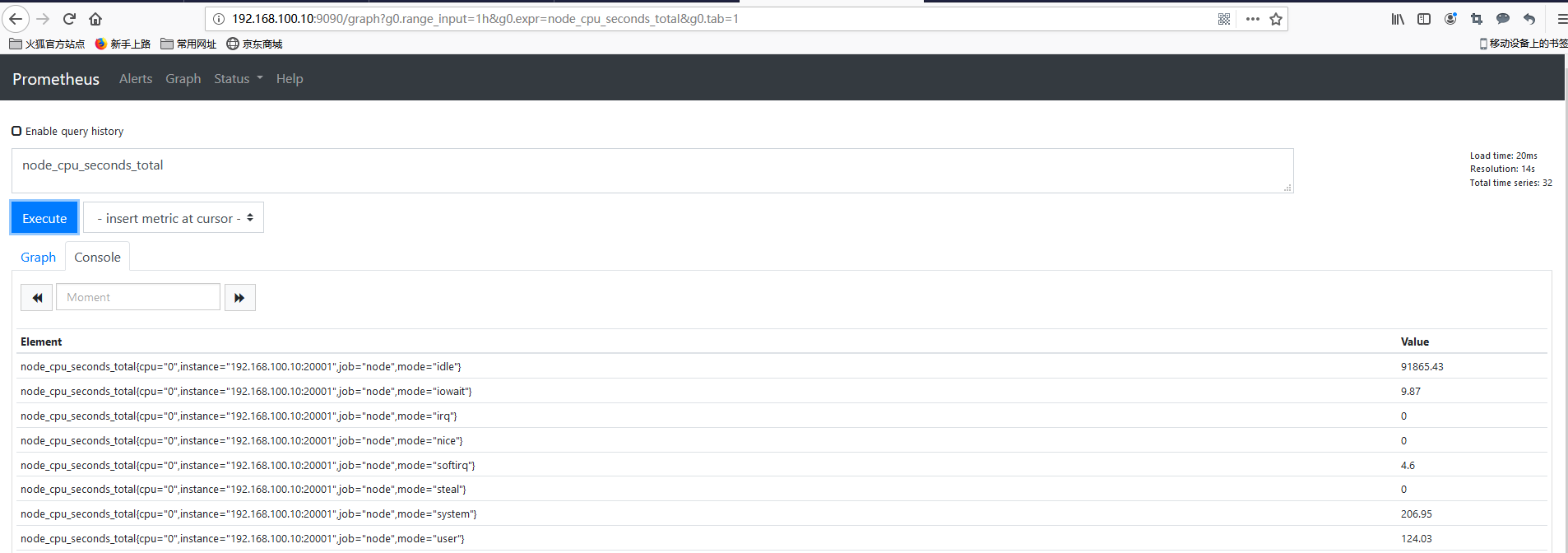
样例查询
prometheus学习系列三:node_exporter安装部署的更多相关文章
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- RabbitMQ学习系列三-C#代码接收处理消息
RabbitMQ学习系列三:.net 环境下 C#代码订阅 RabbitMQ 消息并处理 http://www.80iter.com/blog/1438251320680361 http://www. ...
- kubernetes系列03—kubeadm安装部署K8S集群
本文收录在容器技术学习系列文章总目录 1.kubernetes安装介绍 1.1 K8S架构图 1.2 K8S搭建安装示意图 1.3 安装kubernetes方法 1.3.1 方法1:使用kubeadm ...
- .net reactor 学习系列(三)---.net reactor代码自动操作相关保护功能
原文:.net reactor 学习系列(三)---.net reactor代码自动操作相关保护功能 接上篇,上篇已经学习了界面的各种功能以及各种配置,这篇准备学习下代码控制许可证. ...
- MyBatis学习系列三——结合Spring
目录 MyBatis学习系列一之环境搭建 MyBatis学习系列二——增删改查 MyBatis学习系列三——结合Spring MyBatis在项目中应用一般都要结合Spring,这一章主要把MyBat ...
- DocX开源WORD操作组件的学习系列三
DocX学习系列 DocX开源WORD操作组件的学习系列一 : http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_sharp_001_docx1.htm ...
- Identity Server4学习系列三
1.简介 在Identity Server4学习系列一和Identity Server4学习系列二之令牌(Token)的概念的基础上,了解了Identity Server4的由来,以及令牌的相关知识, ...
- RabbitMQ学习系列三:.net 环境下 C#代码订阅 RabbitMQ 消息并处理
上一篇已经讲了Rabbitmq如何在Windows平台安装 不懂请移步: RabbitMQ学习系列二:.net 环境下 C#代码使用 RabbitMQ 消息队列 一.理论 .net环境下,C#代码订阅 ...
- C# Redis学习系列三:Redis配置主从
Redis配置主从 主IP :端口 192.168.0.103 6666 从IP:端口 192.168.0.108 3333 配置从库 (1)安装服务: redis-server ...
随机推荐
- Linux下进程间通信方式——pipe(管道)
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程A把数据从用户空间拷到内核缓冲区,进程B再从内核缓冲区把 ...
- Linux进程通信的几种方式总结
进程通信的目的 数据传输 一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几M字节之间 共享数据 多个进程想要操作共享数据,一个进程对共享数据 通知事 一个进程需要向另一个或一组进程发 ...
- Computer-Hunters——项目系统设计与数据库设计
Computer-Hunters--项目系统设计与数据库设计 前言 本次作业属于2019秋福大软件工程实践Z班 本次作业要求 团队名称: Computer-Hunters 本次作业目标:撰写一份针对团 ...
- 计算机原理学习(1)-- 冯诺依曼体系和CPU工作原理
前言 对于我们80后来说,最早接触计算机应该是在95年左右,那个时候最流行的一个词语是多媒体. 依旧记得当时在同学家看同学输入几个DOS命令就成功的打开了一个游戏,当时实在是佩服的五体投地.因为对我来 ...
- Linux内核文档翻译——kobject.txt
==================================================================== Everything you never wanted to ...
- Lua函数声明与调用
lua编程中,我们经常也会遇到函数的声明定义和调用. [1]lua中函数定义与调用的方法 lua有两种函数定义和调用的方法(本质都是用属性,方式不同而已): (1)点号形式 (2)冒号形式 两种方法的 ...
- Spark Core知识点复习-2
day1112 1.spark core复习 任务提交 缓存 checkPoint 自定义排序 自定义分区器 自定义累加器 广播变量 Spark Shuffle过程 SparkSQL 一. Spark ...
- DDR3(5):读写仲裁
上一讲我们完成了读的控制,但是并不知道是否设计成功,必须读写结合才行.DDR3 的 app 端的命令总线是读写复用的,因此可能会存在读写冲突的时刻,为了解决此问题,必须进行分时读写,也就是我们说的仲裁 ...
- linux权限管理(chown、chgrp、chomd)
一.文件权限 我们以/etc/passwd 文件为例,用ll长列出其属性如下所示 ll /etc/passwd 每个文件针对每类访问访问者都定义了三种权限 文件类型中: p:表示命名管道文件 d:表示 ...
- kafka Authentication using SASL/Kerberos
Authentication using SASL/Kerberos Prerequisites KerberosIf your organization is already using a Ker ...