[原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情
from bs4 import BeautifulSoup
import requests
import os def getdepotdetailcontent(title,url):#爬取每个仓库列表的详情
r=requests.get("https://www.50yc.com"+url).content
soup = BeautifulSoup(r,"html.parser")
result = soup.find(name='div',attrs={"class":"sm-content"})#返回元素集
content = result.find_all("li")#返回元素集
with open(os.getcwd()+"\\depot\\"+title+"\\depotdetail.txt","w") as f :
for i in content:
b = i.find("span").text
br = i.find("div").text
f .write(b.replace(" ","").replace("\n","")+br.replace(" ","")+"\n"+"****************************"+"\n")
f.close() def getdepot(page):#爬取仓库列表信息
depotlisthtml = requests.get("https://www.50yc.com/xan"+page).content
content = BeautifulSoup(depotlisthtml,"html.parser")
tags = content.find_all(name="div",attrs={"class":"bg-hover"})
for i in tags:
y = i.find_all(name="img")#返回tag标签
for m in y:
if m["src"].startswith("http"):
imgurl = m["src"]
print(imgurl)
title = i.strong.text
depotdetailurl = i.a['href']
# print(depotdetailurl)
os.mkdir(os.getcwd()+'\\depot\\'+title+'\\')
with open(os.getcwd()+'\\depot\\'+title+'\\'+"depot.jpg","wb") as d :
d.write(requests.get(imgurl).content)
with open(os.getcwd()+'\\depot\\'+title+'\\'+"depot.txt","w") as m:
m.write(i.text.replace(" ",""))
m.close()
getdepotdetailcontent(title,depotdetailurl) for i in range(1,26):#爬取每页的仓库列表与仓库详情
getdepot("/page"+str(i))
print("/page"+str(i))
爬取内容为:
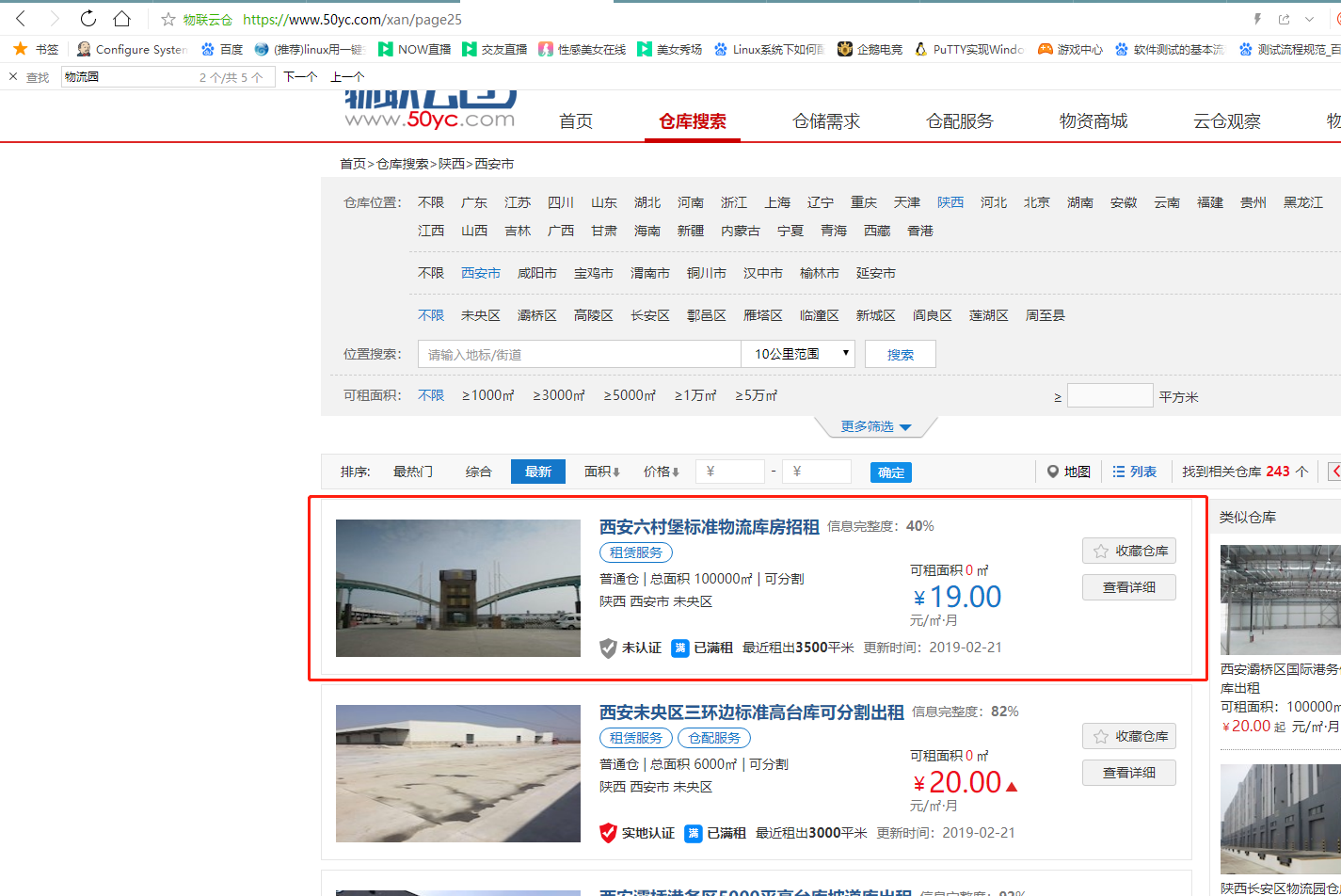
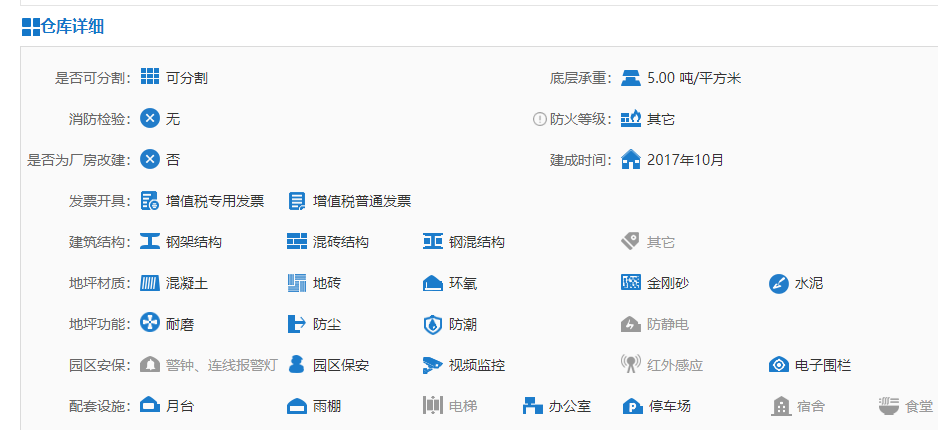
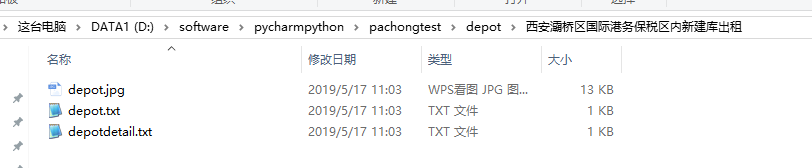
爬取结果如下:

[原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情的更多相关文章
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- Python多线程爬取某网站表情包
# 爬取网络图片import requestsfrom lxml import etreefrom urllib import requestfrom queue import Queue # 导入队 ...
- python 爬虫 爬取序列博客文章列表
python中写个爬虫真是太简单了 import urllib.request from pyquery import PyQuery as PQ # 根据URL获取内容并解码为UTF-8 def g ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
- python之简单爬取一个网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
随机推荐
- 人工智能+Python:十大Markdown语法简明教程
Markdown 是一种轻量级的标记语言,用户可以使用诸如 * # 等简单的标记符号以最小的输入代价生成极富表现力的文档,目前也被越来越多的写作爱好者,撰稿者广泛使用.本文希望用直观的方法来讲述Mar ...
- c# 第28节 面向对象概述
本节内容: 1:面向对象概述 2:类与对象的概念 1:面向对象概述 面向对象也称:OOP :object-oriented programming 面向对象的程序设计 面向过程:堆代码,从头开始,自己 ...
- 【转】HTTPS建立连接的过程
原文链接:https://www.cnblogs.com/shiqi17/p/9756880.html https://www.jianshu.com/p/bd75ab32ae57 HTTP建立连接的 ...
- ubuntu16.04matlab中文注释乱码的解决办法
中文注释乱码的原因是windows下的m文件采用的是gb2312编码,只要将所有的m文件转成 utf8文件,显示就正常了. 1.首先安装enca:sudo apt-get install enca 2 ...
- layui教程---table
layui.config({ base: "${ctx}/static/js/" }).use(['form', 'layer', 'jquery', 'common','elem ...
- Django views 中的装饰器
关于装饰器 示例: 有返回值的装饰器:判断用户是否登录,如果登录继续执行函数,否则跳回登录界面 def auth(func): def inner(request, *args, **kwargs): ...
- Python进阶-XVIII 封装、(属性、静态方法、类方法)语法糖、反射
1.封装 类中的私有化:属性的私有化和方法的私有化 会用到私有的这个概念de场景 1.隐藏起一个属性 不想让类的外部调用 2.我想保护这个属性,不想让属性随意被改变 3.我想保护这个属性,不被子类继承 ...
- IDEA取消SVN关联 , 在重新分享项目
IDEA取消SVN关联,在重新分享项目 安装插件 1.打开Intellij中工具栏File的setting(ctrl+alt+s),选择plugins,在右边搜索框输入“SVN”,搜索.选择“ ...
- 【转】UML各种图总结
UML(Unified Modeling Language)是一种统一建模语言,为面向对象开发系统的产品进行说明.可视化.和编制文档的一种标准语言.下面将对UML的九种图+包图的基本概念进行介绍以及各 ...
- 集成Azure DevOps Server(TFS) 与微软Teams
1.概述 Microsoft Teams是Office 365中团队协作的中心.将团队的所有聊天.会议.文件和应用程序放在一个位置.软件开发团队可以在一个专门的协作中心中即时访问他们所需的所有内容,T ...