python3 scrapy 使用selenium 模拟浏览器操作
零. 在用scrapy爬取数据中,有写是通过js返回的数据,如果我们每个都要获取,那就会相当麻烦,而且查看源码也看不到数据的,所以能不能像浏览器一样去操作他呢?
所以有了->
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。Selenium 测试可以在 Windows、Linux 和 Macintosh上的 Internet Explorer、Chrome和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。
一.http://selenium-python.readthedocs.io/installation.html
下载谷歌浏览器模拟
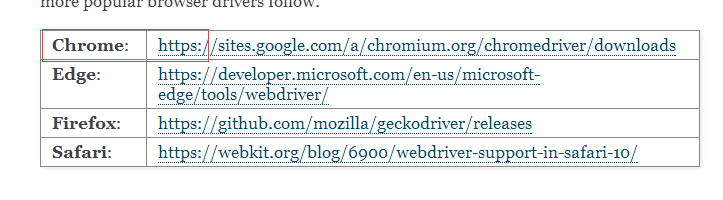
二.安装selenium
pip install selenium
from selenium import webdriver
from scrapy.selector import Selector browser = webdriver.Chrome(executable_path="F:/GitHub/python/chromedriver_win32/chromedriver.exe");
browser.get("https://detail.tmall.com/item.htm?spm=a222t.8063993.4308149192.1.4d1c4546jqNJNV&acm=lb-zebra-164656-978500.1003.4.3165043&id=566510433862&scm=1003.4.lb-zebra-164656-978500.OTHER_222_3165043&scene=taobao_shop&sku_properties=10004:653780895;5919063:6536025")
print(browser.page_source)
t_selector = Selector(text=browser.page_source)
ttt = t_selector.xpath('//*[@class="tm-price"]//text()').extract()
print(ttt)
browser.quit();
模拟访问淘宝
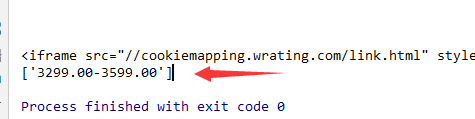
OK! 拿到了淘宝的商品价格了!
python3 scrapy 使用selenium 模拟浏览器操作的更多相关文章
- python下selenium模拟浏览器基础操作
1.安装及下载 selenium安装: pip install selenium 即可自动安装selenium geckodriver下载:https://github.com/mozilla/ge ...
- 孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1
孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1 (完整学习过程屏幕记录视频地址在文末) 要模拟进行浏览器操作,只用requests是不行的,因此今天了解到有专门的解决方案 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- selenium模拟浏览器对搜狗微信文章进行爬取
在上一篇博客中使用redis所维护的代理池抓取微信文章,开始运行良好,之后运行时总是会报501错误,我用浏览器打开网页又能正常打开,调试了好多次都还是会出错,既然这种方法出错,那就用selenium模 ...
- 浏览器与服务器交互原理以及用java模拟浏览器操作v
浏览器应用服务器JavaPHPApache * 1,在HTTP的WEB应用中, 应用客户端和服务器之间的状态是通过Session来维持的, 而Session的本质就是Cookie, * 简单的讲,当浏 ...
- selenium控制浏览器操作
selenium控制浏览器操作 控制浏览器有哪些操作? 控制页面大小 前进.后退 刷新 自动输入.提交 ........ 控制页面大小,实例: # -*- coding:utf-8 -*- from ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- python爬虫:使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动 ...
随机推荐
- cocos代码研究(15)Widget子类CheckBox学习笔记
理论基础 复选框是一种特定类型的“两状态”按钮,可以处于“选中”和“未选中状态”.继承自AbstractCheckButton.注 AbstractCheckButton继承自Widget类. 代码部 ...
- vim7.4在Win8下的安装及简单配置
软件环境 vim74 git vim中文帮助 vundle安装——插件管理软件 cd vim所在路径/vimfiles/bundle git clone https://github.com/gmar ...
- python webdriver 显示等待-自动登录126邮箱,添加联系人
脚本内容:#encoding=utf-8#author-夏晓旭from selenium import webdriverimport timefrom selenium.webdriver.supp ...
- 20145319 《网络渗透》MS12_020安全漏洞
20145319 <网络渗透>MS12_020安全漏洞 一 实验内容 初步掌握平台matesploit辅助模块aux的使用 辅助模块包括扫描等众多辅助功能 本次展示DOS攻击的实现 有了初 ...
- Git review :error: unpack failed: error Missing tree
环境 git version 1.9.1 Gerrit Code Review (2.11.3) 1 2 现象 修改后调用 git review可以提交到Gerrit上,然后只要一用 git comm ...
- arm-linux-ld命令
我们对每个c或者汇编文件进行单独编译,但是不去连接,生成很多.o 的文件,这些.o文件首先是分散的,我们首先要考虑的如何组合起来:其次,这些.o文件存在相互调用的关系:再者,我们最后生成的bin文件是 ...
- MSSQL 重建索引(在线重建、控制最大处理器数 、MAXDOP )
一.什么情况下需要重建索引 1.碎片过多(参考值:>20%) 索引碎片如何产生,请移步至< T-SQL查询高级—SQL Server索引中的碎片和填充因子> 2.填充度过低(参考值: ...
- HDU 2485 Destroying the bus stations(费用流)
http://acm.hdu.edu.cn/showproblem.php?pid=2485 题意: 现在要从起点1到终点n,途中有多个车站,每经过一个车站为1时间,现在要在k时间内到达终点,问至少要 ...
- springboot p6spy 打印完整sql
调试时打印出sql的需求,太正常不过了,mybatis也提供了这样的功能: mybatis: configuration: log-impl: org.apache.ibatis.logging.st ...
- R语言数据去重
R语言常用的去重命令有unique duplicated unique主要是返回一个把重复元素或行给删除的向量.数据框或数组 > x <- c(3:5, 11:8, 8 + 0:5)> ...