python3 scrapy 使用selenium 模拟浏览器操作
零. 在用scrapy爬取数据中,有写是通过js返回的数据,如果我们每个都要获取,那就会相当麻烦,而且查看源码也看不到数据的,所以能不能像浏览器一样去操作他呢?
所以有了->
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。Selenium 测试可以在 Windows、Linux 和 Macintosh上的 Internet Explorer、Chrome和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。
一.http://selenium-python.readthedocs.io/installation.html
下载谷歌浏览器模拟
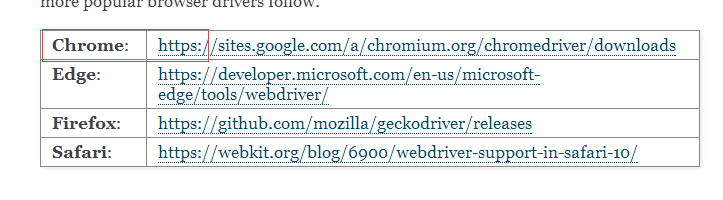
二.安装selenium
pip install selenium
from selenium import webdriver
from scrapy.selector import Selector browser = webdriver.Chrome(executable_path="F:/GitHub/python/chromedriver_win32/chromedriver.exe");
browser.get("https://detail.tmall.com/item.htm?spm=a222t.8063993.4308149192.1.4d1c4546jqNJNV&acm=lb-zebra-164656-978500.1003.4.3165043&id=566510433862&scm=1003.4.lb-zebra-164656-978500.OTHER_222_3165043&scene=taobao_shop&sku_properties=10004:653780895;5919063:6536025")
print(browser.page_source)
t_selector = Selector(text=browser.page_source)
ttt = t_selector.xpath('//*[@class="tm-price"]//text()').extract()
print(ttt)
browser.quit();
模拟访问淘宝
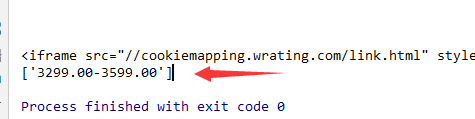
OK! 拿到了淘宝的商品价格了!
python3 scrapy 使用selenium 模拟浏览器操作的更多相关文章
- python下selenium模拟浏览器基础操作
1.安装及下载 selenium安装: pip install selenium 即可自动安装selenium geckodriver下载:https://github.com/mozilla/ge ...
- 孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1
孤荷凌寒自学python第八十五天配置selenium并进行模拟浏览器操作1 (完整学习过程屏幕记录视频地址在文末) 要模拟进行浏览器操作,只用requests是不行的,因此今天了解到有专门的解决方案 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- selenium模拟浏览器对搜狗微信文章进行爬取
在上一篇博客中使用redis所维护的代理池抓取微信文章,开始运行良好,之后运行时总是会报501错误,我用浏览器打开网页又能正常打开,调试了好多次都还是会出错,既然这种方法出错,那就用selenium模 ...
- 浏览器与服务器交互原理以及用java模拟浏览器操作v
浏览器应用服务器JavaPHPApache * 1,在HTTP的WEB应用中, 应用客户端和服务器之间的状态是通过Session来维持的, 而Session的本质就是Cookie, * 简单的讲,当浏 ...
- selenium控制浏览器操作
selenium控制浏览器操作 控制浏览器有哪些操作? 控制页面大小 前进.后退 刷新 自动输入.提交 ........ 控制页面大小,实例: # -*- coding:utf-8 -*- from ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- python爬虫:使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动 ...
随机推荐
- (转)JavaScriptSerializer,DataContractJsonSerializer解析JSON字符串功能小记
JsonAbout: using System;using System.Collections.Generic;using System.Linq;using System.Text;using S ...
- java基础类型中的char和byte的辨析及Unicode编码和UTF-8的区别
在平常工作中使用到char和byte的场景不多,但是如果项目中使用到IO流操作时,则必定会涉及到这两个类型,下面让我们一起来回顾一下这两个类型吧. char和byte的对比 byte byte 字节, ...
- 89. Gray Code(公式题)
The gray code is a binary numeral system where two successive values differ in only one bit. Given a ...
- 587. Erect the Fence(凸包算法)
问题 给定一群树的坐标点,画个围栏把所有树围起来(凸包). 至少有一棵树,输入和输出没有顺序. Input: [[1,1],[2,2],[2,0],[2,4],[3,3],[4,2]] Output: ...
- 通过J2EE Web工程添加Flex项目,进行BlazeDS开发
http://www.cnblogs.com/noam/archive/2010/07/22/1782955.html 环境:Eclipse 7.5 + Flex Builder 4 plugin f ...
- 【图像处理】计算Haar特征个数
http://blog.csdn.net/xiaowei_cqu/article/details/8216109 Haar特征/矩形特征 Haar特征本身并不复杂,就是用图中黑色矩形所有像素值的和减去 ...
- MySQL基准测试工具--sysbench
我们需要知道的是sysbench并不是一个压力测试工具,是一个基准测试工具.linux自带的版本比较低,我们需要自己安装sysbench. [root@test2 ~]# sysbench --ver ...
- vSphere Client开启虚拟机提示:出现了常规系统错误: 由于目标计算机积极拒绝,无法连接。
进入VCenter Server服务器上 进入服务管理器,查看 VMware vCenter workflow manager 是否启动,如未启动,则改为启动,问题得以解决 再次启动虚拟机,已启动!
- git使用合集
1.git 克隆时重命名本地文件夹或目录 如:git clone https://github.com/torvalds/linux.git linux_kernel 2.git查看tag git t ...
- Mysql加锁处理分析-基于InnoDB存储引擎
MVCC MySQL INNODB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-VERSION Concurrency Control).MVCC最大的好处,相信也是耳熟能详: ...