AdaBoost算法原理简介
AdaBoost算法原理
AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器)。理论证明,只要每个弱分类器分类能力比随机猜测要好,当其个数趋向于无穷个数时,强分类器的错误率将趋向于零。AdaBoost算法中不同的训练集是通过调整每个样本对应的权重实现的。最开始的时候,每个样本对应的权重是相同的,在此样本分布下训练出一个基本分类器h1(x)。对于h1(x)错分的样本,则增加其对应样本的权重;而对于正确分类的样本,则降低其权重。这样可以使得错分的样本突出出来,并得到一个新的样本分布。同时,根据错分的情况赋予h1(x)一个权重,表示该基本分类器的重要程度,错分得越少权重越大。在新的样本分布下,再次对基本分类器进行训练,得到基本分类器h2(x)及其权重。依次类推,经过T次这样的循环,就得到了T个基本分类器,以及T个对应的权重。最后把这T个基本分类器按一定权重累加起来,就得到了最终所期望的强分类器。
AdaBoost算法的具体描述如下:
假定X表示样本空间,Y表示样本类别标识集合,假设是二值分类问题,这里限定Y={-1,+1}。令S={(Xi,yi)|i=1,2,…,m}为样本训练集,其中Xi∈X,yi∈Y。
① 始化m个样本的权值,假设样本分布Dt为均匀分布:Dt(i)=1/m,Dt(i)表示在第t轮迭代中赋给样本(xi,yi)的权值。
② 令T表示迭代的次数。
③ For t=1 to T do
根据样本分布Dt,通过对训练集S进行抽样(有回放)产生训练集St。
在训练集St上训练分类器ht。
用分类器ht对原训练集S中的所有样本分类。
得到本轮的分类器ht:X →Y,并且有误差εt=Pri-Di[ht(xi) ≠yi]。
令αt=(1/2)ln[(1-εt)/ εt]。
更新每个样本的权值,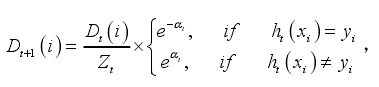
其中,Zt是一个正规因子,用来确保ΣiDt+1(i)=1。
end for
④ 最终的预测输出为: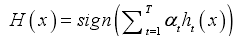
AdaBoost算法原理简介的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10 在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术.通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导 ...
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- AdaBoost 算法-分析波士顿房价数据集
公号:码农充电站pro 主页:https://codeshellme.github.io 在机器学习算法中,有一种算法叫做集成算法,AdaBoost 算法是集成算法的一种.我们先来看下什么是集成算法. ...
随机推荐
- localstorage与sessionstorage的使用
cookie,sessionStorage,localeStorage的区别 cookie是存储在浏览器端,并且随浏览器的请求一起发送到服务器端的,它有一定的过期时间,到了过期时间自动会消失.sess ...
- Centos6虚拟主机的实现
centos6上虚拟主机的实现 实现虚拟主机有三种方式:基于IP的实现.基于端口的实现.基于FQDN的实现 一.基于IP的实现 1.先创建三个站点: mkdir /app/site1 mkdir ...
- python linux安装anaconda
步骤: 1.在清华大学镜像站中下载anaconda版本:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ https://mirrors.t ...
- SPOJ NSUBSTR Substrings ——后缀自动机
建后缀自动机 然后统计次数,只需要算出right集合的大小即可, 然后更新f[l[i]]和rit[i]取个max 然后根据rit集合短的一定包含长的的性质,从后往前更新一遍即可 #include &l ...
- BZOJ 4566 [Haoi2016]找相同字符 ——广义后缀自动机
建立广义后缀自动机. 然后统计子树中的siz,需要分开统计 然后对(l[i]-l[fa[i]])*siz[i][0]*siz[i][1]求和即可. #include <cstdio> #i ...
- SPOJ QTREE Query on a tree ——树链剖分 线段树
[题目分析] 垃圾vjudge又挂了. 树链剖分裸题. 垃圾spoj,交了好几次,基本没改动却过了. [代码](自带常数,是别人的2倍左右) #include <cstdio> #incl ...
- KVM 网络虚拟化基础
网络虚拟化是虚拟化技术中最复杂的部分,学习难度最大. 但因为网络是虚拟化中非常重要的资源,所以再硬的骨头也必须要把它啃下来. 为了让大家对虚拟化网络的复杂程度有一个直观的认识,请看下图 这是 Open ...
- UOJ#370. 【UR #17】滑稽树上滑稽果
$n \leq 1e5$个点,每个点有个权值$a_i \leq 2e5$.现将点连成树,每个点$i$的链接代价为$a_i \ \ and \ \ i父亲的代价$,这里的$and$是二进制按位与,求最小 ...
- SQL 随机取出一条数据
今天遇到一需求,需要随机取出一条数据.网上找了下,sqlserver自带的有newID()这个函数,可以随机出来一个guid,用来取随机数还是蛮不错的. 直接上SQL: select top 1 *, ...
- Redis数据结构之简单动态字符串
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组), 而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型, 并将SDS用作Redi ...