Apache Spark源码走读之4 -- DStream实时流数据处理
欢迎转载,转载请注明出处,徽沪一郎。
Spark Streaming能够对流数据进行近乎实时的速度进行数据处理。采用了不同于一般的流式数据处理模型,该模型使得Spark Streaming有非常高的处理速度,与storm相比拥有更高的吞能力。
本篇简要分析Spark Streaming的处理模型,Spark Streaming系统的初始化过程,以及当接收到外部数据时后续的处理步骤。
系统概述
流数据的特点
与一般的文件(即内容已经固定)型数据源相比,所谓的流数据拥有如下的特点
- 数据一直处在变化中
- 数据无法回退
- 数据一直源源不断的涌进
DStream
如果要用一句话来概括Spark Streaming的处理思路的话,那就是"将连续的数据持久化,离散化,然后进行批量处理"。
让我们来仔细分析一下这么作的原因。
- 数据持久化 将从网络上接收到的数据先暂时存储下来,为事件处理出错时的事件重演提供可能,
- 离散化 数据源源不断的涌进,永远没有一个尽头,就像周星驰的喜剧中所说“崇拜之情如黄河之水绵绵不绝,一发而不可收拾”。既然不能穷尽,那么就将其按时间分片。比如采用一分钟为时间间隔,那么在连续的一分钟内收集到的数据集中存储在一起。
- 批量处理 将持久化下来的数据分批进行处理,处理机制套用之前的RDD模式
DStream可以说是对RDD的又一层封装。如果打开DStream.scala和RDD.scala,可以发现几乎RDD上的所有operation在DStream中都有相应的定义。
作用于DStream上的operation分成两类
- Transformation
- Output 表示将输出结果,目前支持的有print, saveAsObjectFiles, saveAsTextFiles, saveAsHadoopFiles
DStreamGraph
有输入就要有输出,如果没有输出,则前面所做的所有动作全部没有意义,那么如何将这些输入和输出绑定起来呢?这个问题的解决就依赖于DStreamGraph,DStreamGraph记录输入的Stream和输出的Stream。
private val inputStreams = new ArrayBuffer[InputDStream[_]]()
private val outputStreams = new ArrayBuffer[DStream[_]]()
var rememberDuration: Duration = null
var checkpointInProgress = false
outputStreams中的元素是在有Output类型的Operation作用于DStream上时自动添加到DStreamGraph中的。
outputStream区别于inputStream一个重要的地方就是会重载generateJob.
初始化流程
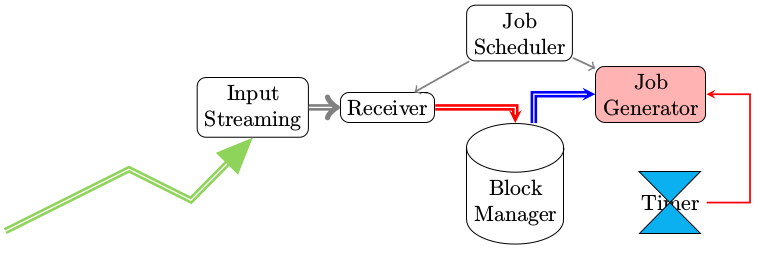
StreamingContext
StreamingContext是Spark Streaming初始化的入口点,主要的功能是根据入参来生成JobScheduler
设定InputStream
如果流数据源来自于socket,则使用socketStream。如果数据源来自于不断变化着的文件,则可使用fileStream
提交运行
StreamingContext.start()
数据处理

以socketStream为例,数据来自于socket。
SocketInputDstream启动一个线程,该线程使用receive函数来接收数据
def receive() {
var socket: Socket = null
try {
logInfo("Connecting to " + host + ":" + port)
socket = new Socket(host, port)
logInfo("Connected to " + host + ":" + port)
val iterator = bytesToObjects(socket.getInputStream())
while(!isStopped && iterator.hasNext) {
store(iterator.next)
}
logInfo("Stopped receiving")
restart("Retrying connecting to " + host + ":" + port)
} catch {
case e: java.net.ConnectException =>
restart("Error connecting to " + host + ":" + port, e)
case t: Throwable =>
restart("Error receiving data", t)
} finally {
if (socket != null) {
socket.close()
logInfo("Closed socket to " + host + ":" + port)
}
}
}
}
接收到的数据会被先存储起来,存储最终会调用到BlockManager.scala中的函数,那么BlockManager是如何被传递到StreamingContext的呢?利用SparkEnv传入的,注意StreamingContext构造函数的入参。

处理定时器
数据的存储有是被socket触发的。那么已经存储的数据被真正的处理又是被什么触发的呢?
记得在初始化StreamingContext的时候,我们指定了一个时间参数,那么用这个参数会构造相应的重复定时器,一旦定时器超时,调用generateJobs函数。
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds, longTime => eventActor ! GenerateJobs(new Time(longTime)), "JobGenerator")事件处理函数
/** Processes all events */
private def processEvent(event: JobGeneratorEvent) {
logDebug("Got event " + event)
event match {
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time) => doCheckpoint(time)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}
generteJobs
private def generateJobs(time: Time) {
SparkEnv.set(ssc.env)
Try(graph.generateJobs(time)) match {
case Success(jobs) =>
val receivedBlockInfo = graph.getReceiverInputStreams.map { stream =>
val streamId = stream.id
val receivedBlockInfo = stream.getReceivedBlockInfo(time)
(streamId, receivedBlockInfo)
}.toMap
jobScheduler.submitJobSet(JobSet(time, jobs, receivedBlockInfo))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventActor ! DoCheckpoint(time)
}
generateJobs->generateJob一路下去会调用到Job.run,在job.run中调用sc.runJob,在具体调用路径就不一一列出。
private class JobHandler(job: Job) extends Runnable {
def run() {
eventActor ! JobStarted(job)
job.run()
eventActor ! JobCompleted(job)
}
}
DStream.generateJob函数中定义了jobFunc,也就是在job.run()中使用到的jobFunc
private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) => {
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
}
case None => None
}
}
在这个流程中,DStreamGraph起到非常关键的作用,非常类似于TridentStorm中的graph.
在generateJob过程中,DStream会通过调用compute函数生成相应的RDD,SparkContext则是将基于RDD的抽象转换成为多个stage,而执行。
StreamingContext中一个重要的转换就是DStream到RDD的转换,而SparkContext中一个重要的转换是RDD到Stage及Task的转换。在这两个不同的抽象类中,要注意其中getOrCompute和compute函数的实现。
小结
本篇内容有点仓促,内容不够丰富翔实,争取回头有空的时候再好好丰富一下具体的调用路径。
对于容错处理机制,本文没有涉及,待研究明白之后另起一篇进行阐述。
Apache Spark源码走读之4 -- DStream实时流数据处理的更多相关文章
- Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理.在Spark Streaming的处理机制 ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
欢迎转载,转载请注明出处,徽沪一郎. 概要 上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅.本篇讲述如何使用 ...
- Apache Spark源码走读之6 -- 存储子系统分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数 ...
- Apache Spark源码走读之17 -- 如何进行代码跟读
欢迎转载,转载请注明出处,徽沪一郎 概要 今天不谈Spark中什么复杂的技术实现,只稍为聊聊如何进行代码跟读.众所周知,Spark使用scala进行开发,由于scala有众多的语法糖,很多时候代码跟着 ...
- Apache Spark源码走读之11 -- sql的解析与执行
欢迎转载,转载请注明出处,徽沪一郎. 概要 在即将发布的spark 1.0中有一个新增的功能,即对sql的支持,也就是说可以用sql来对数据进行查询,这对于DBA来说无疑是一大福音,因为以前的知识继续 ...
随机推荐
- 【读书笔记】读《JavaScript模式》 - 函数复用模式之现代继承模式
现代继承模式可表述为:其他任何不需要以类的方式考虑得模式. 现代继承方式#1 —— 原型继承之无类继承模式 function object(o) { function F() {}; F.protot ...
- Jpush推送模块
此文章已于 14:17:10 2015/3/24 重新发布到 鲸歌 Jpush推送模块 或以上版本的手机系统. SDK集成步骤 .导入 SDK 开发包到你自己的应用程序项目 • 解压 ...
- Android实现高仿QQ附近的人搜索展示
本文主要实现了高仿QQ附近的人搜索展示,用到了自定义控件的方法 最终效果如下 1.下面展示列表我们可以使用ViewPager来实现(当然如果你不觉得麻烦,你也可以用HorizontalScrollVi ...
- 每个人都应该知晓的8项Resharper快捷键
(此文章同时发表在本人微信公众号“dotNET每日精华文章”) 如果你已经在用Resharper这个编程神器(机器杀手)的话,那么为了进一步提高工作效率熟悉它的一些特殊特性和快捷键那是必须的. Res ...
- strcat函数造成的段错误(Segmentation fault)
转自:http://book.51cto.com/art/201311/419441.htm 3.21 strcat函数造成的段错误 代码示例 int main() { char dest[7]=& ...
- ☆☆配置NDK环境
1 前提是 已经配置好 安卓SDK开发环境. 2 下载 android-ndk64-r10-windows-x86_64,可以从官方网站下载,这里有一个现成的. http://pan.baidu.co ...
- UVALive 6887 Book Club 最大流解最大匹配
题目连接: https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show ...
- MATLAB学习笔记(九)——MATLAB符号计算
(一)符号对象 一.建立符号对象 1.建立符号变量和符号常量(sym,syms): 只可以建立一个符号变量 可以一次性建立多个符号变量 PS:符号常量计算的结果是精确的数学表达式,而数值常量是进行约分 ...
- matlab参数查询
nargout nargout的作用是在matlab中定义一个函数时, 在函数体内部, nargout指出了输出参数的个数(nargin指出了输入参数的个数). 特别是在利用了可变参数列表的函数中, ...
- [LintCode] Trapping Rain Water
Given n non-negative integers representing an elevation map where the width of each bar is 1, comput ...