Jmeter(十九)_ForEach控制器实现网页爬虫
一直以来,爬虫似乎都是写代码去实现的,今天像大家介绍一下Jmeter如何实现一个网页爬虫! 龙渊阁测试开发家园 317765580
Jmeter的爬虫原理其实很简单,就是对网页提交一个请求,然后把返回的所有href提取出来,利用ForEach控制器去实现url遍历。这样解释是不是很清晰?下面就来简单介绍一下如何操作。
首先我们需要对网页提交一个请求,就拿腾讯新闻网举例子吧!我们像腾讯新闻网发起一个请求,观察一下返回值可以发现中间有很多href标签+文字标题的url
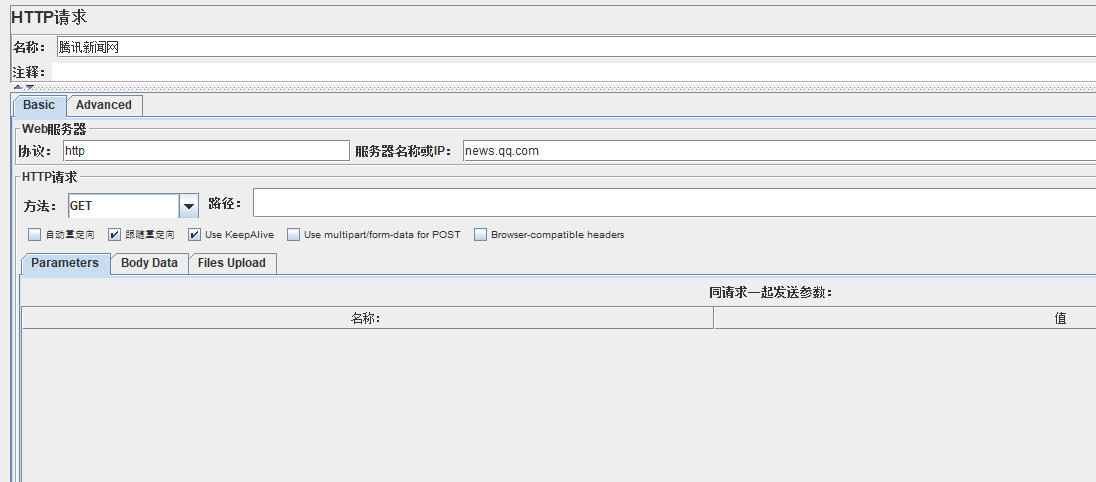

我们现在需要把这些url提取出来,利用强大的正则表达式!记得匹配数字填-1,意思就是把所有合适的url都取出来 龙渊阁测试开发家园 317765580
a target="_blank" class="linkto" href="http:// *(.*l)"

加一个debug查看一下是否真的取出来了 龙渊阁测试开发家园 317765580

又或者我们在结果里面直接利用正则匹配一下,可以看到很多网页链接都被取出来了 龙渊阁测试开发家园 317765580

接下来我们需要动用到ForEach控制器了,利用这个控制器对所有取出来的url进行遍历触发。记得在控制器里面填入变量名称,也就是刚刚正则表达式里面的变量名
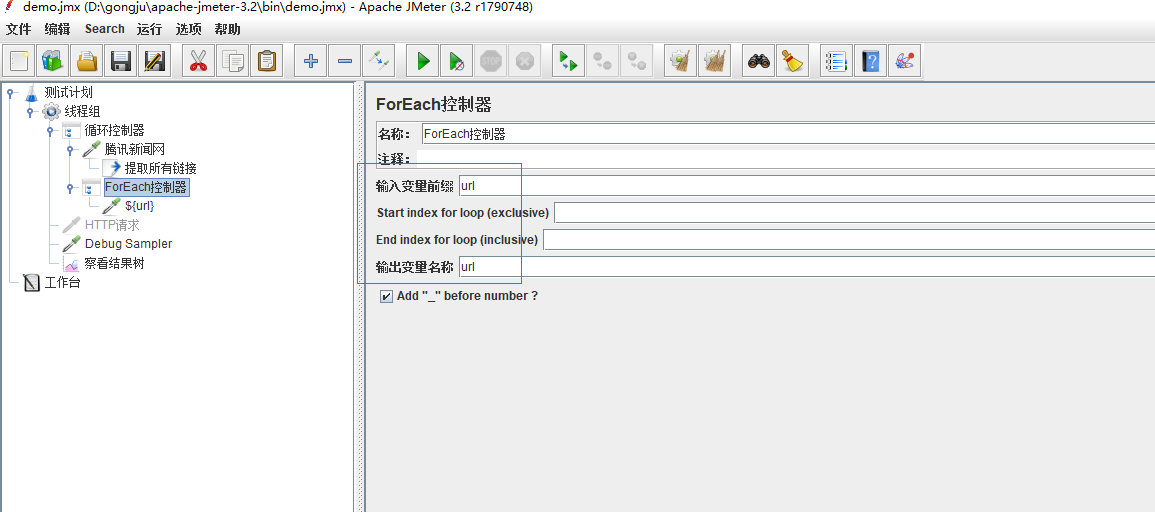
接下来在ForEach控制器下面再添加一个http请求,利用它去执行请求触发

下面我们可以观察结果了,见证奇迹的时候到了。观察结果我们发现所有匹配的url都被触发了! 龙渊阁测试开发家园 317765580

Jmeter(十九)_ForEach控制器实现网页爬虫的更多相关文章
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式 我们自定义一个main.py来作为启动文件 main.py #!/usr/bin/en ...
- Jmeter(三十五)_精确实现网页爬虫
Jmeter实现了一个网站文章的爬虫,可以把所有文章分类保存到本地文件中,并以文章标题命名 它原理就是对网页提交一个请求,然后把返回的所有值提取出来,利用ForEach控制器去实现遍历.下面来介绍一下 ...
- Jmeter_ForEach控制器实现网页爬虫
一直以来,爬虫似乎都是写代码去实现的,今天像大家介绍一下Jmeter如何实现一个网页爬虫! Jmeter的爬虫原理其实很简单,就是对网页提交一个请求,然后把返回的所有href提取出来,利用ForEac ...
- Jmeter(十九) - 从入门到精通 - JMeter监听器 -上篇(详解教程)
1.简介 监听器用来监听及显示JMeter取样器测试结果,能够以树.表及图形形式显示测试结果,也可以以文件方式保存测试结果,JMeter测试结果文件格式多样,比如XML格式.CSV格式.默认情况下,测 ...
- Jmeter(四十五) - 从入门到精通高级篇 - Jmeter之网页爬虫-上篇(详解教程)
1.简介 上大学的时候,第一次听同学说网页爬虫,当时比较幼稚和懵懂,觉得就是几只电子虫子爬在网页上在抓取东西.后来又听说写代码可以实现网页爬虫,宏哥感觉高大上,后来工作又听说,有的公司做爬虫被抓的新闻 ...
- Python之路【第十九篇】:爬虫
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
随机推荐
- python 多进程 Event的使用
Event事件 多进程的使用 通俗点儿讲 就是 1. Event().wait() 插入在进程中插入一个标记(flag) 默认为 false 然后flag为false时 程序会停止运 ...
- AndroidManifest 配置主活动
在activity标签中写如下代码: <activity android:name=".MainActivity" android:label="This is M ...
- Django2.0路由层-URLconf
目录 DJango2.0路由层-URLconf 概述 urlpatterns 实例 path转换器 自定义path转换器 使用正则表达式 命名组(有名分组) URLconf匹配请求URL中的哪些部分 ...
- 设计一个 Java 程序,自定义异常类,从命令行(键盘)输入一个字符串,如果该字符串值为“XYZ”。。。
设计一个 Java 程序,自定义异常类,从命令行(键盘)输入一个字符串,如果该字符串值为“XYZ”,则抛出一个异常信息“This is a XYZ”,如果从命令行输入 ABC,则没有抛出异常.(只有 ...
- beta冲刺————第一天(1/5)
人员的再次分配: 调走人员:陈裕鹏(原来在本队伍主要进行文章推荐算法的设计) 调入人员:陈邡(原Dipper团队,负责游戏内容的策划案,以及做一些后端的探索工作.) 现队员工作划分: 王国华,吴君毅, ...
- spark的shuffle和原理分析
概述 Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂. 在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段 ...
- ModuleNotFoundError No module named urllib2
ModuleNotFoundError No module named urllib2?那么在进行编辑的来进行代码上开发,那就会出现的来代码的上错误,也是版本的上差异导致的问题. 工具/原料 ...
- Java继承访问权限
JAVA 子类重写继承的方法时,不可以降低方法的访问权限,子类继承父类的访问修饰符要比父类的更大,也就是更加开放,假如我父类是protected修饰的,其子类只能是protected或者public, ...
- mysql安装及错误解决
#下载mysql源安装包shell> wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm# 安装my ...
- python+jenkins 构建节点环境编译器配置问题
python 编译器默认添加环境变量路径