6、transformation和action1
一、transformation和action入门
1、介绍
Spark支持两种RDD操作:transformation和action。transformation操作会针对已有的RDD创建一个新的RDD;而action则主要是对RDD进行最后的操作,比如遍历、reduce、
保存到文件等,并可以返回结果给Driver程序。 例如,map就是一种transformation操作,它用于将已有RDD的每个元素传入一个自定义的函数,并获取一个新的元素,然后将所有的新元素组成一个新的RDD。而reduce
就是一种action操作,它用于对RDD中的所有元素进行聚合操作,并获取一个最终的结果,然后返回给Driver程序。 transformation的特点就是lazy特性。lazy特性指的是,如果一个spark应用中只定义了transformation操作,那么即使你执行该应用,这些操作也不会执行。也就是说,transformation是不会触发spark程序的执行的,它们只是记录了对RDD所做的操作,但是不会自发的执行。只有当transformation之后,接着执行了一个action操作,那么
所有的transformation才会执行。Spark通过这种lazy特性,来进行底层的spark应用执行的优化,避免产生过多中间结果。 action操作执行,会触发一个spark job的运行,从而触发这个action之前所有的transformation的执行。这是action的特性。
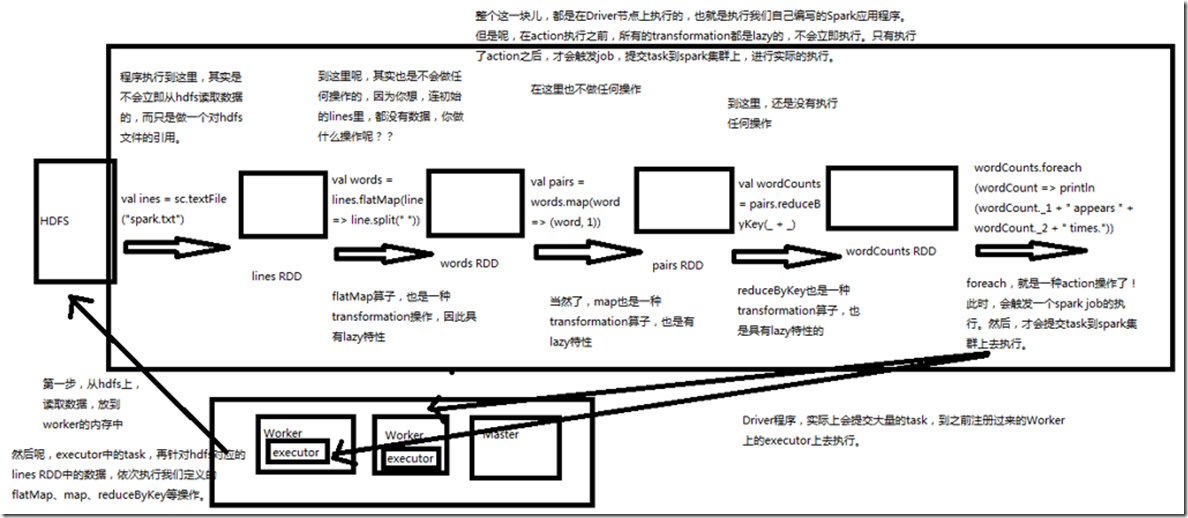
2、案例:统计文件字数
这里通过一个之前学习过的案例,统计文件字数,来讲解transformation和action。 // 这里通过textFile()方法,针对外部文件创建了一个RDD,lines,但是实际上,程序执行到这里为止,spark.txt文件的数据是不会加载到内存中的。lines,只是代表了一个
指向spark.txt文件的引用。
val lines = sc.textFile("spark.txt") // 这里对lines RDD进行了map算子,获取了一个转换后的lineLengths RDD。但是这里连数据都没有,当然也不会做任何操作。lineLengths RDD也只是一个概念上的东西而
已。
val lineLengths = lines.map(line => line.length) // 之后,执行了一个action操作,reduce。此时就会触发之前所有transformation操作的执行,Spark会将操作拆分成多个task到多个机器上并行执行,每个task会在本地执行
map操作,并且进行本地的reduce聚合。最后会进行一个全局的reduce聚合,然后将结果返回给Driver程序。
val totalLength = lineLengths.reduce(_ + _)
4、案例:统计文件每行出现的次数
Spark有些特殊的算子,也就是特殊的transformation操作。比如groupByKey、sortByKey、reduceByKey等,其实只是针对特殊的RDD的。即包含key-value对的RDD。
而这种RDD中的元素,实际上是scala中的一种类型,即Tuple2,也就是包含两个值的Tuple。 在scala中,需要手动导入Spark的相关隐式转换,import org.apache.spark.SparkContext._。然后,对应包含Tuple2的RDD,会自动隐式转换为PairRDDFunction,并提供
reduceByKey等方法。 -----------------java实现-------------------- package cn.spark.study.core; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; /**
* 统计每行出现的次数
*
* @author bcqf
*
*/ public class LineCount {
public static void main(String[] args) {
// 创建SparkConf
SparkConf sparkConf = new SparkConf().setAppName("LineCountJava").setMaster("local"); // 创建JavaSparkContext
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf); // 创建初始RDD,linesRDD 每个元素是一行文本
JavaRDD<String> linesRDD = javaSparkContext.textFile("D:\\test-file\\hello.txt"); // 对linesRDD执行mapToPair算子,将每一行映射为(lines,1)这种key-value对的格式,然后才能统计每一行出现的次数
/**
* PairFunction:一个函数返回键值对(Tuple2<K, V>),可以用于构造pairRDDs
* public interface PairFunction<T, K, V> extends Serializable {
* public Tuple2<K, V> call(T t) throws Exception;
* }
*/
JavaPairRDD<String, Integer> pairsRDD = linesRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
// 对pairsRDD执行reduceByKey算子,统计出每一行出现的总次数; Function2<T1,T2,R>
JavaPairRDD<String, Integer> linesCount = pairsRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
// 执行一个action操作,foreach,打印出每一行出现的总次数
linesCount.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
System.out.println(stringIntegerTuple2._1 + " appears " + stringIntegerTuple2._2 + " times");
}
});
// 关闭javaSparkContext
javaSparkContext.close();
}
}
----------------scala实现--------------------
package cn.spark.study.core
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object LineCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("LineCount").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("D:\\test-file\\hello.txt", 1)
val pairs = lines.map { line => (line, 1)}
val lineCounts = pairs.reduceByKey {_ + _}
lineCounts.foreach(lineCount => println(lineCount._1 + " appears " + lineCount._2 + " times."))
}
}
5、常用transformation
|
操作 |
介绍 |
|
map |
将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD |
|
filter |
对RDD中每个元素进行判断,如果返回true则保留,返回false则剔除。 |
|
flatMap |
与map类似,但是对每个元素都可以返回一个或多个新元素。 |
| groupByKey |
根据key进行分组,每个key对应一个Iterable<value> |
|
reduceByKey |
对每个key对应的value进行reduce操作。 |
|
sortByKey |
对每个key对应的value进行排序操作。 |
|
join |
对两个包含<key,value>对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理。 |
|
cogroup |
同join,但是是每个key对应的Iterable<value>都会传入自定义函数进行处理。 |
6、常用action
|
操作 |
介绍 |
|
reduce |
将RDD中的所有元素进行聚合操作。第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推。 |
|
collect |
将RDD中所有元素获取到本地客户端; |
|
count |
获取RDD元素总数。 |
|
take(n) |
获取RDD中前n个元素。 |
|
saveAsTextFile |
将RDD元素保存到文件中,对每个元素调用toString方法 |
|
countByKey |
对每个key对应的值进行count计数。 |
|
foreach |
遍历RDD中的每个元素。 |
6、transformation和action1的更多相关文章
- (七)Transformation和action详解-Java&Python版Spark
Transformation和action详解 视频教程: 1.优酷 2.YouTube 什么是算子 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作. 算子分类: 具体: 1.Value ...
- 线性分式变换(linear fractional transformation)
线性分式变换(linear fractional transformation)的名称来源于其定义的形式:(ax+b)/(cx+d),其中分子分母是线性的,然后最外层是一个分式形式,所以叫做这个名字, ...
- OLE DB Command transformation 用法
OLE DB Command transformation component 能够引用参数,逐行调用sqlcommand,This transformation is typically used ...
- OpenCASCADE General Transformation
OpenCASCADE General Transformation eryar@163.com Abstract. OpenCASCADE provides a general transforma ...
- Informatica Lookup Transformation组件的Connect 与Unconnected类型用法
Informatica Lookup Transformation组件的Connect 与Unconnected类型用法及区别:下面是通一个Lookup在不同Mapping中的使用: 1. Conne ...
- Data Transformation / Learning with Counts
机器学习中离散特征的处理方法 Updated: August 25, 2016 Learning with counts is an efficient way to create a compact ...
- VS非web项目使用Transformation配置文件
Web项目中的Transformation使用起来非常方便,特别是本地与服务器情况不一致时调试下以及webdeploy的配合使用. 步骤: 1. 在项目中新建App.Debug.Config及App. ...
- SAP SLT (Landscape Transformation) 企业定制培训
No. Item Remark 1 SAP SLT概述 SAP Landscape Transformation Overview 2 SAP SLT 安装与配置<1> for abap ...
- Scalaz(55)- scalaz-stream: fs2-基础介绍,fs2 stream transformation
fs2是scalaz-stream的最新版本,沿用了scalaz-stream被动式(pull model)数据流原理但采用了全新的实现方法.fs2比较scalaz-stream而言具备了:更精简的基 ...
随机推荐
- Redis 如何与数据库事务保持一致
考虑一个问题,redis 如何 与 数据库保持一致性的问题. 举栗子:如果我们在开发过程中遇到这样的一种情况,我们删除 redis中token 的同时 也需要修改数据库中 储存的 token 的状态为 ...
- Consul基本使用
原文: Consul基本使用 date: 2019-05-13 17:01:37 前言 官网介绍Consul是一个分布式服务网格(Service Mesh)解决方案... 而我目前的理解是提供了分布式 ...
- 笔记 - C#从头开始构建编译器 - 1
视频与PR:https://github.com/terrajobst/minsk/blob/master/docs/episode-01.md 作者是 Immo Landwerth(https:// ...
- Lucid Dream
Lucid Dream 作者:Lo Stigmergy链接:https://www.zhihu.com/question/21260829/answer/35733194 清醒状态下时意识和潜意识基本 ...
- vue-cli项目开发运行时内存暴涨卡死电脑
最近开发一个vue项目时遇到电脑卡死问题,突然间系统就非常卡,然后卡着卡着就死机了,鼠标也动不了了,只能冷启动.而且因为是突然卡死,没来得及打开任务管理器. 最开始以为是硬盘的问题,但是在卡死几次后, ...
- 开始Swift学习之路
Swift出来好几个月了,除了同事分享点知识外,对swift还真没有去关心过.GitHub上整理的学习Swift资料还是很不错的,目前也推出了电子书和PDF格式. Swift的语法和我们平常开发的语言 ...
- 记录--linux下mysql数据库问题
本次主要记录一下linux下mysql数据库的一些问题,也是之前经常用到的知识,这里简单总结一些问题,方便自己以后的回顾.原来一直使用的是阿里云的RDS数据库mysql版,主要是因为上次阿里云做活动可 ...
- 微信小程序 之wxml保留小数点后两位数的方法及转化为字符串的方法
原理:wxml中不能直接使用较高级的js语法,如‘.toFixed’,‘toString()’,但可以通过引入wxs模块实现效果 1.新建`filter.wxs` var filters = { ...
- c# 定制Equals()
- 小知识——c++关于指针的理解
参考文章: 简介: 指针可以简化c++编程,在一些任务中没有指针是无法完成的(动态内存分配) 使用 & 可以获得变量在内存中的地址: eg: #include <iostream> ...