Python链表操作(实现)
Python链表操作
在Python开发的面试中,我们经常会遇到关于链表操作的问题。链表作为一个非常经典的无序列表结构,也是一个开发工程师必须掌握的数据结构之一。在本文中,我将针对链表本身的数据结构特点,以及链表的一些常见操作给大家做一个深入浅出的讲解,希望本文的读者能够掌握链表的操作。
1. 什么是链表?
简单地说,链表是一种无序的列表。你可以把链表里面的数据看成是随机排列的,元素之间并没有固定的先后顺序。所以,既然是无序的,那么我们就无法像操作list对象一样简单地用index来去定位和操作里面的元素,如下图所示:
 图1
图1
那么针对这种情况,我们怎么才能找到里面的各个元素呢?
其实,在链表里面的每个元素其实是一种叫Node的节点对象,每个Node会保存两个信息,一个是这个节点的值value,另一个是这个节点对应的下一个节点的引用next。这样,节点与节点之间其实就形成了一种链式结构,就像一根铁链一样,一环扣一环,这也是链表这个名字的由来。有了这样的链式结构,只要给我们一个起点,我们就能沿着起点一个节点一个节点地找到所有的节点,这就是链表整个数据结构的核心。
2. 如何实现链表?
前面已经讲过,链表结构的关键是Node节点对象,所以要实现链表之前,我们需要先定义Node节点对象。每个节点中保存着当前节点的数据value,以及当前节点的下一个节点的引用next,所以我们可以这样来定义一个Node对象:
class Node:
def __init__(self, data):
self.data = data # 保存当前节点的值
self.next = None # 保存当前节点中下一个节点的引用
为了能够获取和设置Node里面的信息,我们还需要定义几个方法,代码如下:
def __init__(self, data):
self.data = data
self.next = None
# 获取node里面的数据
def getData(self):
return self.data
# 获取下一个节点的引用
def getNext(self):
return self.next
# 设置node里面的数据
def setData(self, newdata):
self.data = newdata
# 设置下一个节点的引用
def setNext(self, newnext):
self.next = newnext
这些方法用于存取Node里面的数据,方便在链表结构里面去使用。
Node对象定义好之后,接下来我们就可以开始定义链表对象了。我们这里讲的是单向链表,所以英文成为Single Link List。定义链表时,最主要的是定义好链表的头(head),因为之前我们说过,我们只要找到了链表的头,就能够沿着这个头找到其他所有的node。所以,链表的初始定义很简单,我们只要定义一个head属性即可,代码如下:
class MySingleLinkList():
def __init__(self):
# 定义链表的头结点
self.head = None
这里大家要注意一点,链表对象本身是不包含任何节点Node对象的,相反,它只包含对链接结构中第一个节点的单个引用(self.head),这个head实际上永远会指向链表中的第一个节点。如果head为None,实际上意味着这是一个空的链表。链表LinkList对象和Node对象从定义上是独立的,互相并不包含对方。这个基本思想很重要,只要大家记住这个基本原则,那么我们就可以开始接着实现链表中的其他方法。
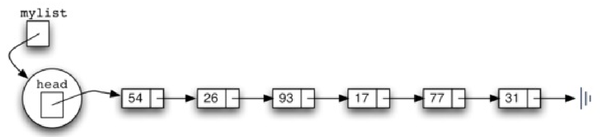 图2
图2
一般来说,一个链表中应该包含的基本操作主要有以下几个:
- 判断链表是否为空 isEmpty()
def isEmpty(self):
'''
判断head指向的节点是否为None,如果head指向None,说明该链表为空
'''
return self.head == None
- 获取链表的长度 size()
获取链表的长度的关键是要遍历这个链表,并对节点数进行计数。遍历链表是链表操作中会被频繁使用到的基本操作,像链表节点的查询、删除等操作都会涉及到链表的遍历。我们之前说过,遍历链表时,我们必须先找到链表的head节点,从链表的头部开始不断地查找每个节点的next节点,最终直到某一个节点的next指向None,就说明遍历完成了。
def size(self):
current = self.head # 将链表的头节点赋值给current,代表当前节点
count = 0
while current != None:
count += 1
current = current.getNext() # 计数后,不断把下一个节点的引用赋值给当前节点,这样我们就能不断向后面的节点移动
return count
- 向链表中增加一个节点 add()
向链表中增加一个节点的时候,我们要考虑两个问题。第一个问题是,新加入的节点该加到哪里?大家可以想一想,链表是一个无序结构,其实把新的节点加到哪里对链表本身来说是无所谓的。但加入到链表的不同位置,对于我们的代码操作难度是有区别的。因为我们之前定义的链表结构始终只保持对第一个节点的引用,所以从这个角度来看,最简单的方法就是把新的节点加入到链表的头部,使新节点成为链表的第一个节点,然后以前的节点依次后移。第二个问题是,加入新节点的时候,要进行哪些操作?实际上要加入一个新的节点,需要两个步骤。首先需要把之前的head节点赋值给新节点的下一个节点,也就是新节点的next,然后再把新节点赋值给head节点,让它成为新的head(如图3所示)。
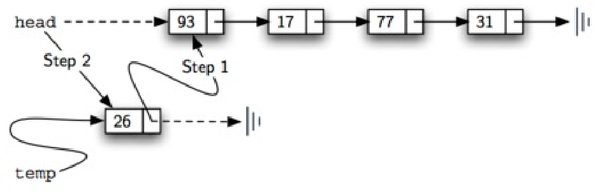 图3
图3
def add(self, val):
temp = Node(val)
temp.next = self.head # 将原来的开始节点设置为新开始节点的下一节点
self.head = temp # 将新加入节点设置为现在的第一个节点
必须要注意temp.next = self.head和self.head=temp这两个语句的先后顺序,如果把self.head=temp写在前面,则会使得head原来指向的下一个节点的信息全部丢失,这并不是我们想要的结果(如图4所示)。
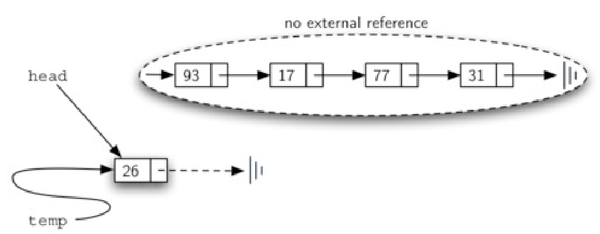 图4
图4
- 查找指定节点是否在链表中 search()
要实现查找算法,必然也是要遍历链表的,我们可以设置一个布尔变量作为是否查找到目标元素的标志,然后通过遍历链表中的每个元素,判断该元素的值是否等于要查找的值,如果是,则将布尔值设置为True,最后返回该布尔值即可。代码如下:
def search(self, item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
- 移除指定节点 remove()
移除指定节点也是在链表中一个常见的操作,在移除指定节点时,除了要先遍历链表找到指定元素外,还需要对这个即将被移除的节点做一些处理,以确保剩下的节点能够正常工作。在我们找到要被移除的节点时,按照之前写过的遍历方法我们知道,current应该是指向要被移除的节点。可问题是怎么才能移除掉该节点呢?为了能够移除节点,我们需要修改上一个节点中的链接,以便使其直接指向当前将被移除节点的下一个节点,使没有任何其他节点指向这个被移除的节点,以达到移除节点的目的。但这里有个问题,就是当我们循环链表到当前节点时,没法回退回去操作当前节点的前一个节点。所以,为了解决这个问题,在遍历链表时,除了需要记录当前指向的节点current外,还需要设置一个变量来记录当前节点的上一个节点previous,每次循环时,如果当前节点不是要被移除的节点,那么就将当前节点的值赋值给previous,而将下一个节点的引用赋值给当前节点,以达到向前移动的目的。同时,在找到了将被移除的节点后,我们会把found设置为true,停止遍历。
另外,在删除节点时,可能会有三种情况:
(1)被移除的节点就是链表中的开始节点,这时previous一定是None值,我们只需要将current.next赋值给head即可。
(2)被移除的节点是链表中最后的节点。
(3)被移除的节点是普通节点(即不是第一个也不是最后一个节点)。
其中第(2)(3)种情况并不需要特殊处理,直接设置previous的next为current的next即可。
def remove(self, item):
current = self.head
previous = None
found = False
# 判断指定值是否存在于链表中
if not self.search(item):
return
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
- 获取链表中所有节点的值 getAllData()
获取链表中的所有节点的值方便我们随时查看链表中究竟有哪些值。由于链表并不像普通的list一样可以直接打印出来看,所以一般我们需要借助于遍历链表把链表中的每个节点的值取出来放到一个列表中,然后再打印这个列表,从而取得链表中所有节点值的目的。
def getAllData(self): # 得到链表中所有的值
data = []
current = self.head
while current:
data.append(current.getData())
current = current.getNext()
return data
这些就是我们在链表中常用的操作方法及对应的代码实现,接下来我们可以尝试来操作并测试一下我们写的这些方法对不对。
linkList = MySingleLinkList()
for i in range(10, 50, 5):
linkList.add(i)
print(linkList.size()) # output: 8
print(linkList.getAllData()) # output: [45, 40, 35, 30, 25, 20, 15, 10]
linkList.remove(25)
print(linkList.getAllData()) # output: [45, 40, 35, 30, 20, 15, 10]
linkList.search(25) # output: False
linkList.isEmpyt() # output: False
以上就是我们在面试中经常遇到的python算法中的链表的定义和常见操作
Python链表操作(实现)的更多相关文章
- Python面试常考点之深入浅出链表操作
Python面试常考点之深入浅出链表操作 在Python开发的面试中,我们经常会遇到关于链表操作的问题.链表作为一个非常经典的无序列表结构,也是一个开发工程师必须掌握的数据结构之一.在本文中,我将针对 ...
- Python链表的实现与使用(单向链表与双向链表)
参考[易百教程]用Python实现链表及其功能 """ python链表的基本操作:节点.链表.增删改查 """ import sys cl ...
- Python中操作mysql的pymysql模块详解
Python中操作mysql的pymysql模块详解 前言 pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而后者不支持 ...
- JAVA 链表操作:循环链表
主要分析示例: 一.循环链表简述 二.单链表循环链表 三.双链表循环链表 一.循环链表简述 循环链表即链表形成了一个循环的结构,尾节点不再指向NULL,而是指向头节点HEAD,此时判定链表的结束是尾节 ...
- Python 字符串操作
Python 字符串操作(string替换.删除.截取.复制.连接.比较.查找.包含.大小写转换.分割等) 去空格及特殊符号 s.strip() .lstrip() .rstrip(',') 复制字符 ...
- Python目录操作
Python目录操作 os和os.path模块os.listdir(dirname):列出dirname下的目录和文件os.getcwd():获得当前工作目录os.curdir:返回但前目录('.') ...
- Python基础篇【第2篇】: Python文件操作
Python文件操作 在Python中一个文件,就是一个操作对象,通过不同属性即可对文件进行各种操作.Python中提供了许多的内置函数和方法能够对文件进行基本操作. Python对文件的操作概括来说 ...
- Python list 操作
创建列表sample_list = ['a',1,('a','b')] Python 列表操作sample_list = ['a','b',0,1,3] 得到列表中的某一个值value_start = ...
- 单链表操作B 分类: 链表 2015-06-07 12:42 15人阅读 评论(0) 收藏
数据结构上机测试2-2:单链表操作B TimeLimit: 1000ms Memory limit: 65536K 题目描述 按照数据输入的相反顺序(逆位序)建立一个单链表,并将单链表中重复的元素删除 ...
随机推荐
- Python基础之集合set
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型), 但是集合本身是不可哈希的(所以集合做不了字典的键)的. 以下是集合最重要的两点: (1)去重,把一个列表变成集合,就自动去重了. ...
- Java线程间如何通信(五)
1.简述 线程是操作系统中独立的个体,但这些个体如果不经过特殊的处理就不能称为一个整体. 使线程之间进行通信后,在大大提高CPU利用率的同时还会使开发人员对各个线程任务在处理的过程中进行有效的把控. ...
- 记一次antlr错误:ANTLR Tool version 4.5.3 used for code generation does not match the current runtime version 4.7.2ANTLR
场景:重构spark 2.1版本的sql语法.因此 需要使用antlr: 前期准备:idea安装了antlr插件(antlr的4.7.2版本) 因此在maven工程中添加了antlr的依赖: < ...
- elasticsearch利用head插件
restful接口使用方法 RESTful接口URL的格式: http://localhost:9200///[] 其中index.type是必须提供的. id是可选的,不提供es会自动生成. ind ...
- Linux设备驱动程序 之 自旋锁
概念 自旋锁可以再不能休眠的代码中使用,比如中断处理例程:在正确使用的情况下,自旋锁通常可以提供比信号量更高的性能: 一个自旋锁是一个互斥设备,它只能由两个值,锁定和解锁:通常实现为某个整数值中的单个 ...
- KERNEL_SECURITY_CHECK_FAILURE
出现错误提示重装系统可以解决问题,但不需要重装系统.win8错误提示:KERNEL_SECURITY_CHECK_FAILURE提示对应错误代码:0x00000139 (0x00000003, 0x8 ...
- Django中三种方式写form表单
除了在html中自己手写form表单外,django还可以通过 继承django.forms.Form 或django.forms.ModelForm两个类来自动生成form表单,下面依次利用三种方式 ...
- mybatis之动态SQL操作之查询
1) 查询条件不确定,需要根据情况产生SQL语法,这种情况叫动态SQL /** * 持久层 * @author AdminTC */ public class StudentDao { /** * ...
- document.onselectstart=function(){return false;} 引起的拖动问题
在网页中拖动时,会引起某些文字或一些内容被选中,导致网页中蓝蓝的一片,视觉效果很差,所以我加了个1.document.onselectstart=function(){return false;}或者 ...
- win10自定义右键新建文件
新建.reg文件,如添加py文件 Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\.py\ShellNew] "NullFil ...