lucene.net全文检索(一)相关概念及示例
相关概念
站内搜索
站内搜索通俗来讲是一个网站或商城的“大门口”,一般在形式上包括两个要件:搜索入口和搜索结果页面,但在其后台架构上是比较复杂的,其核心要件包括:中文分词技术、页面抓取技术、建立索引、对搜索结果排序以及对搜索关键词的统计、分析、关联、推荐等。
比较常见的就是电商网站中首页的搜索框,它可以根据关键词(分词)、分类、商品简介、详情等搜索商品信息,可以根据相关度、价格、销量做排序。


全文检索
全文检索是将对站内的网页、文档内容进行分词,然后形成索引,再通过关键词查询匹配索引库中的索引,从而得到索引结果,最后将索引页内容展现给用户。
Lucene.Net
Lucene.net是Lucene的.net移植版本,用C#编写,它完成了全文检索的功能——预先把数据拆分成原子(字/词),保存到磁盘中;查询时把关键字也拆分成原子(字/词),再根据(字/词)进行匹配,返回结果。
Nuget安装“Lucene.Net”和“Lucene.Net.Analysis.PanGu”(盘古分词,一个第三方的分词器)
lucene.net七大对象
1、Analysis
分词器,负责把字符串拆分成原子,包含了标准分词,直接空格拆分。项目中用的是盘古中文分词。

2、Document
数据结构,定义存储数据的格式

3、Index:索引的读写类

4、QueryParser:查询解析器,负责解析查询语句

5、Search:负责各种查询类,命令解析后得到就是查询类

6、Store:索引存储类,负责文件夹等等

7、Util:常见工具类库
git地址:https://github.com/apache/lucenenet/releases/tag/Lucene.Net_3_0_3_RC2_final
索引库-写示例
List<Commodity> commodityList = GetList();//获取数据源
FSDirectory directory = FSDirectory.Open(StaticConstant.TestIndexPath);//文件夹
//经过分词以后把内容写入到硬盘
//PanGuAnalyzer 盘古分词;中华人民共和国,从后往前匹配,匹配到和词典一样的词,就保存起来;建议大家去看看盘古分词的官网;词典是可以我们手动去维护;
//城会玩---网络流行词--默认没有,盘古分词,可以由我们自己把这些词给添加进去;
using (IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED))//索引写入器
{
foreach (Commodity commdity in commodityList)
{
for (int k = 0; k < 10; k++)
{
Document doc = new Document();//一条数据
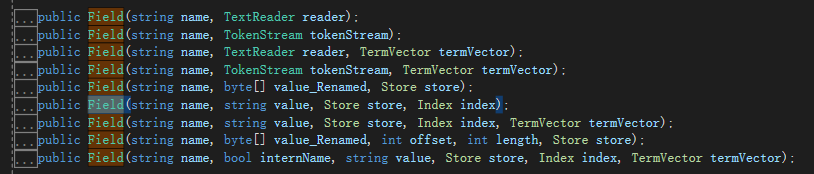
doc.Add(new Field("id", commdity.Id.ToString(), Field.Store.NO, Field.Index.NOT_ANALYZED));//一个字段 列名 值 是否保存值 是否分词
doc.Add(new Field("title", commdity.Title, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("url", commdity.Url, Field.Store.NO, Field.Index.NOT_ANALYZED));
doc.Add(new Field("imageurl", commdity.ImageUrl, Field.Store.NO, Field.Index.NOT_ANALYZED));
doc.Add(new Field("content", "this is lucene working,powerful tool " + k, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new NumericField("price", Field.Store.YES, true).SetDoubleValue((double)(commdity.Price + k)));
//doc.Add(new NumericField("time", Field.Store.YES, true).SetLongValue(DateTime.Now.ToFileTimeUtc()));
doc.Add(new NumericField("time", Field.Store.YES, true).SetIntValue(int.Parse(DateTime.Now.ToString("yyyyMMdd")) + k));
writer.AddDocument(doc);//写进去
}
}
writer.Optimize();//优化 就是合并
}



索引库——读示例
FSDirectory dir = FSDirectory.Open(StaticConstant.TestIndexPath);
IndexSearcher searcher = new IndexSearcher(dir);//查找器
{ FuzzyQuery query = new FuzzyQuery(new Term("title", "高中政治"));
//TermQuery query = new TermQuery(new Term("title", "周年"));//包含
TopDocs docs = searcher.Search(query, null, 10000);//找到的数据
foreach (ScoreDoc sd in docs.ScoreDocs)
{
Document doc = searcher.Doc(sd.Doc);
Console.WriteLine("***************************************");
Console.WriteLine(string.Format("id={0}", doc.Get("id")));
Console.WriteLine(string.Format("title={0}", doc.Get("title")));
Console.WriteLine(string.Format("time={0}", doc.Get("time")));
Console.WriteLine(string.Format("price={0}", doc.Get("price")));
Console.WriteLine(string.Format("content={0}", doc.Get("content")));
}
Console.WriteLine("1一共命中了{0}个", docs.TotalHits);
} QueryParser parser = new QueryParser(Version.LUCENE_30, "title", new PanGuAnalyzer());//解析器
{
// string keyword = "高中政治人教新课标选修生活中的法律常识";
string keyword = "高中政治 人 教 新课 标 选修 生活 中的 法律常识";
{
Query query = parser.Parse(keyword);
TopDocs docs = searcher.Search(query, null, 10000);//找到的数据 int i = 0;
foreach (ScoreDoc sd in docs.ScoreDocs)
{
if (i++ < 1000)
{
Document doc = searcher.Doc(sd.Doc);
Console.WriteLine("***************************************");
Console.WriteLine(string.Format("id={0}", doc.Get("id")));
Console.WriteLine(string.Format("title={0}", doc.Get("title")));
Console.WriteLine(string.Format("time={0}", doc.Get("time")));
Console.WriteLine(string.Format("price={0}", doc.Get("price")));
}
}
Console.WriteLine($"一共命中{docs.TotalHits}");
}
{
Query query = parser.Parse(keyword);
NumericRangeFilter<int> timeFilter = NumericRangeFilter.NewIntRange("time", 20090101, 20201231, true, true);//过滤
SortField sortPrice = new SortField("price", SortField.DOUBLE, false);//false::降序
SortField sortTime = new SortField("time", SortField.INT, true);//true:升序
Sort sort = new Sort(sortTime, sortPrice);//排序 哪个前哪个后 TopDocs docs = searcher.Search(query, timeFilter, 10000, sort);//找到的数据 //可以做什么?就可以分页查询!
int i = 0;
foreach (ScoreDoc sd in docs.ScoreDocs)
{
if (i++ < 1000)
{
Document doc = searcher.Doc(sd.Doc);
Console.WriteLine("***************************************");
Console.WriteLine(string.Format("id={0}", doc.Get("id")));
Console.WriteLine(string.Format("title={0}", doc.Get("title")));
Console.WriteLine(string.Format("time={0}", doc.Get("time")));
Console.WriteLine(string.Format("price={0}", doc.Get("price")));
}
}
Console.WriteLine("3一共命中了{0}个", docs.TotalHits);
}
}




多线程写入索引库示例
try
{
logger.Debug(string.Format("{0} BuildIndex开始",DateTime.Now)); List<Task> taskList = new List<Task>();
TaskFactory taskFactory = new TaskFactory();
CTS = new CancellationTokenSource();
//30个表 30个线程 不用折腾,一线程一表 平均分配
//30个表 18个线程 1到12号2个表 13到18是一个表? 错的!前12个线程活儿多,后面的活少
//自己去想想,怎么样可以做,随便配置线程数量,但是可以均匀分配任务?
for (int i = 1; i < 31; i++)
{
IndexBuilderPerThread thread = new IndexBuilderPerThread(i, i.ToString("000"), CTS);
PathSuffixList.Add(i.ToString("000"));
taskList.Add(taskFactory.StartNew(thread.Process));//开启一个线程 里面创建索引
}
taskList.Add(taskFactory.ContinueWhenAll(taskList.ToArray(), MergeIndex));
Task.WaitAll(taskList.ToArray());
logger.Debug(string.Format("BuildIndex{0}", CTS.IsCancellationRequested ? "失败" : "成功"));
}
catch (Exception ex)
{
logger.Error("BuildIndex出现异常", ex);
}
finally
{
logger.Debug(string.Format("{0} BuildIndex结束", DateTime.Now));
}
private static void MergeIndex(Task[] tasks)
{
try
{
if (CTS.IsCancellationRequested) return;
ILuceneBulid builder = new LuceneBulid();
builder.MergeIndex(PathSuffixList.ToArray());
}
catch (Exception ex)
{
CTS.Cancel();
logger.Error("MergeIndex出现异常", ex);
}
}
///<summary>
/// 将索引合并到上级目录
/// </summary>
/// <param name="sourceDir">子文件夹名</param>
public void MergeIndex(string[] childDirs)
{
Console.WriteLine("MergeIndex Start");
IndexWriter writer = null;
try
{
if (childDirs == null || childDirs.Length == 0) return;
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
string rootPath = StaticConstant.IndexPath;
DirectoryInfo dirInfo = Directory.CreateDirectory(rootPath);
LuceneIO.Directory directory = LuceneIO.FSDirectory.Open(dirInfo);
writer = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);//删除原有的
LuceneIO.Directory[] dirNo = childDirs.Select(dir => LuceneIO.FSDirectory.Open(Directory.CreateDirectory(string.Format("{0}\\{1}", rootPath, dir)))).ToArray();
writer.MergeFactor = 100;//控制多个segment合并的频率,默认10
writer.UseCompoundFile = true;//创建符合文件 减少索引文件数量
writer.AddIndexesNoOptimize(dirNo);
}
finally
{
if (writer != null)
{
writer.Optimize();
writer.Close();
}
Console.WriteLine("MergeIndex End");
}
}

lucene.net全文检索(一)相关概念及示例的更多相关文章
- lucene解决全文检索word2003,word2007的办法
在上一篇文章中 ,lucene只能全文检索word2003,无法检索2007,并且只能加载部分内容,无法加载全文内容.为解决此问题,找到了如下方法 POI 读取word (word 2003 和 wo ...
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- lucene教程--全文检索技术
1 Lucene 示例代码 https://blog.csdn.net/qzqanzc/article/details/80916430 2 Lucene 实例教程(一)初识L ...
- Lucene的全文检索学习
Lucene的官方网站(Apache的顶级项目):http://lucene.apache.org/ 1.什么是Lucene? Lucene 是 apache 软件基金会的一个子项目,由 Doug C ...
- 黑马_10 Lucene:全文检索
10 Lucene:01.全文检索基本介绍 10 Lucene:02.创建索引库和查询索引 10 Lucene:03.中文分析器 10 Lucene:04.索引库维护CURD
- 基于Lucene的全文检索实践
由于项目的需要,使用到了全文检索技术,这里将前段时间所做的工作进行一个实践总结,方便以后查阅.在实际的工作中,需要灵活的使用lucene里面的查询技术,以达到满足业务要求与搜索性能提升的目的. 一.全 ...
- Lucene.net 全文检索 盘古分词
lucene.net + 盘古分词 引用: 1.Lucene.Net.dll 2.PanGu.Lucene.Analyzer.dll 3.PanGu.HighLight.dll 4.PanGu.dll ...
- Lucene.net 全文检索数据库
#define Search using Lucene.Net.Analysis; using Lucene.Net.Analysis.Tokenattributes; using Lucene.Ne ...
- Lucene.net 全文检索文件
using Lucene.Net.Analysis; using Lucene.Net.Analysis.Tokenattributes; using Lucene.Net.Documents; us ...
- Lucene实现全文检索的流程
[索引和搜索流程图] 对要索引的原始内容进行索引构建一个索引库,索引过程包括:确定原始内容即要搜索的内容->采集文档->创建文档->分析文档->索引文档. 从索引库中搜索内容, ...
随机推荐
- [ABC261C] NewFolder(1)
Problem Statement For two strings $A$ and $B$, let $A+B$ denote the concatenation of $A$ and $B$ in ...
- 使用动画曲线编辑器打造炫酷的3D可视化ACE
前言 在制作3D可视化看板时,除了精细的模型结构外,炫酷的动画效果也是必不可少的.无论是复杂的还是简单的动画效果,要实现100%的自然平滑都是具有挑战性的工作.这涉及到物理引擎的计算和对动画效果的数学 ...
- 安装华企盾DSC防泄密系统huawei Intel的电脑,加载驱动失败
解决方法:从控制面板-[启用或关闭Windows功能]里面把[Hyper-V的功能]关闭 重启电脑再开启之后可以加密驱动则可以加载成功
- Pulsar3.0新功能介绍
在上一篇文章 Pulsar3.0 升级指北讲了关于升级 Pulsar 集群的关键步骤与灾难恢复,本次主要分享一些 Pulsar3.0 的新功能与可能带来的一些问题. 升级后所遇到的问题 先来个欲扬先抑 ...
- Pikachu漏洞靶场 RCE(远程命令执行/代码执行)
RCE 文章目录 RCE 概述 exec "ping" exec "eval" 概述 RCE(remote command/code execute),远程命令 ...
- CMU DLSys 课程笔记 2 - ML Refresher / Softmax Regression
CMU DLSys 课程笔记 2 - ML Refresher / Softmax Regression 本节 Slides | 本节课程视频 这一节课是对机器学习内容的一个复习,以 Softmax ...
- zabbix常用监控项
https://blog.csdn.net/xkjcf/article/details/78559273?locationNum=10&fps=1 agent.ping #agent是否在线 ...
- Spring Eureka 源码解析
本文将简要分析一下关于 Spring Eureka 相关的一些必要的源代码,对应的版本:Spring Cloud 2021.0.1 @EnableEurekaServer 注解 @EnableEure ...
- 初探 Linux Cgroups:资源控制的奇妙世界
Cgroups 是 linux 内核提供的功能,由于牵涉的概念比较多,所以不太容易理解.本文试图通过简单的描述和 Demo 帮助大家理解 Cgroups . 如果你对云原生技术充满好奇,想要深入了解更 ...
- 一篇文章彻底搞懂TiDB集群各种容量计算方式
背景 TiDB 集群的监控面板里面有两个非常重要.且非常常用的指标,相信用了 TiDB 的都见过: Storage capacity:集群的总容量 Current storage size:集群当前已 ...