使用Jsoup和htmlunit爬取动态网页
在对http://zkgg.tjtalents.com.cn/newzxxx.jsp这个网页爬取内容时,如果只使用Jsoup进行解析的话,起内部的a href标签内容无法获取到。


但是实际上通过
Document doc = Jsoup.connect(url).get();
获取到的文档只是newzxxx.jsp中respose的内容。
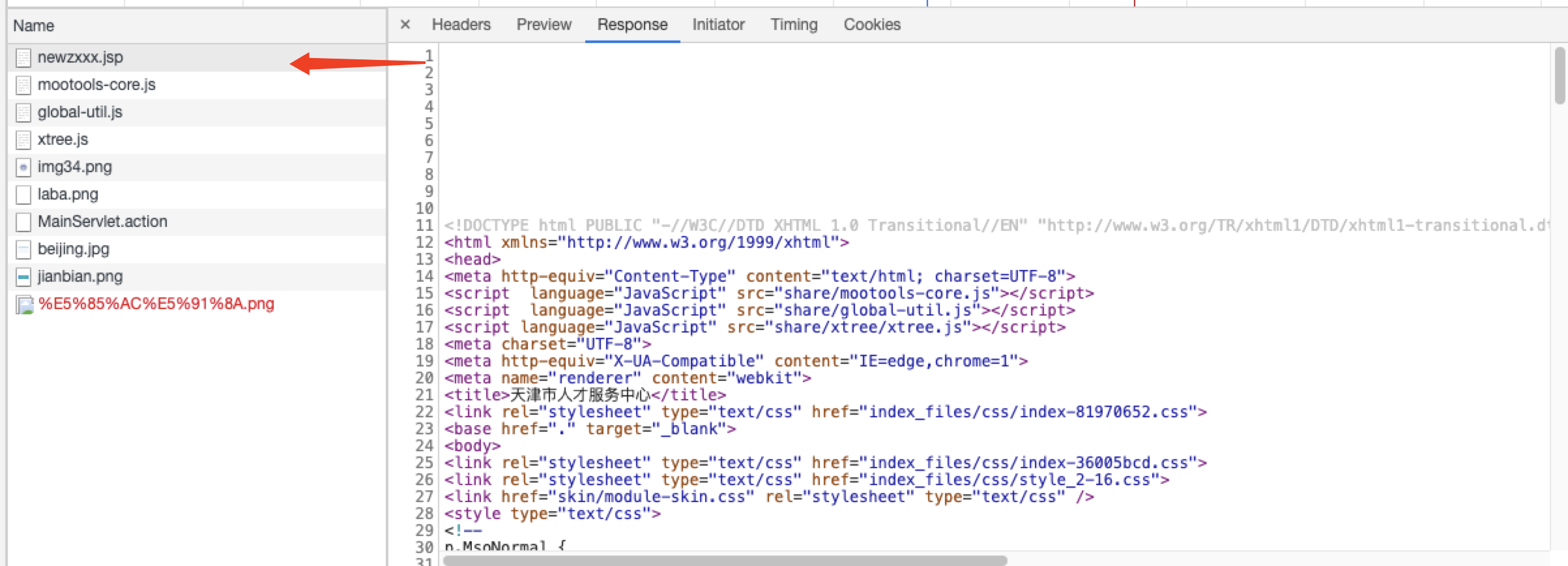
实际我们想要的内容通过js加载得到的。
function query(){
$("formzx").fid.value = "C09.01.01.05";
$("formzx").set('send',{
url: 'MainServlet.action',
onRequest: function(){
},
//成功的回调函数
onSuccess: function(responseText){
$('listspan').innerHTML = responseText;
},
//失败的回调函数. 404. 500. 以及返回JSON串success为false时执行
onFailure: function(responseText){
$('listspan').innerHTML = responseText;
}
});
$("formzx").send();
}
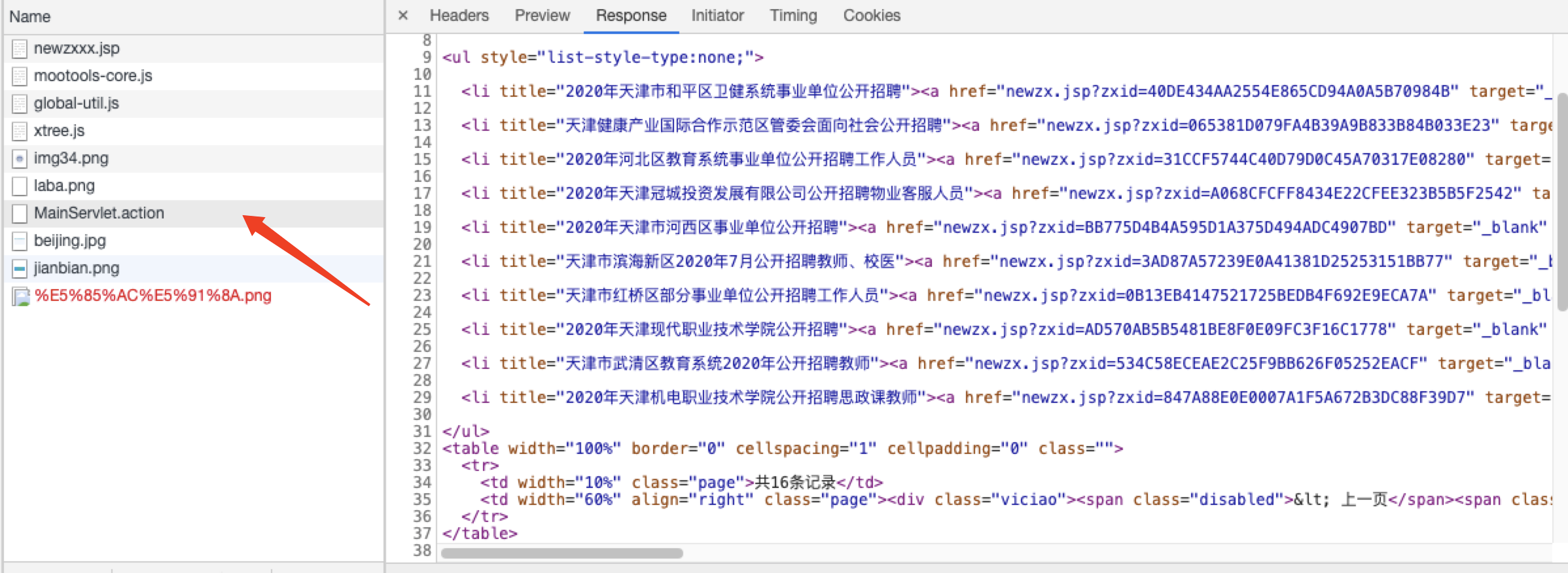
所以这种情况我们可以使用htmlunit来模拟浏览器,并且等待js加载完毕后,再读取整个页面。
public String getPageWaitJS (String url) throws IOException {
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(3*1000);
String pageXml = page.asXml(); //以xml的形式获取响应文本
return pageXml;
}
这样的话就能够获取全部的html页面,之后再使用Jsoup来对页面进行解析即可,这里就不放上Jsoup的代码了。
使用Jsoup和htmlunit爬取动态网页的更多相关文章
- R语言爬取动态网页之环境准备
在R实现pm2.5地图数据展示文章中,使用rvest包实现了静态页面的数据抓取,然而rvest只能抓取静态网页,而诸如ajax异步加载的动态网页结构无能为力.在R语言中,爬取这类网页可以使用RSele ...
- Jsoup配合 htmlunit 爬取异步加载的网页
加入 jsoup 和 htmlunit 的依赖 <dependency> <groupId>org.jsoup</groupId> <artifactId&g ...
- 记录几个爬取动态网页时的问题(下拉框,旧的元素无法获取,获取的源代码和f12看到的不一致,爬取延迟)
更新.....这个动态网页其实直接抓取ajax请求就可以了,很简单,我之前想复杂了,虽然也实现了,但是效率极低,不过没关系,就当作是对Selenium的一次学习吧 1.最近在爬取一个动态网页,其中为了 ...
- python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了? 浏览器请求数据方式:浏览器向服务器的api(例 ...
- 爬虫(三)通过Selenium + Headless Chrome爬取动态网页
一.Selenium Selenium是一个用于Web应用程序测试的工具,它可以在各种浏览器中运行,包括Chrome,Safari,Firefox 等主流界面式浏览器. 我们可以直接用pip inst ...
- 利用selenium并使用gevent爬取动态网页数据
首先要下载相应的库 gevent协程库:pip install gevent selenium模拟浏览器访问库:pip install selenium selenium库相应驱动配置 https: ...
- 爬取动态网页:Selenium
参考:http://blog.csdn.net/wgyscsf/article/details/53454910 概述 在爬虫过程中,一般情况下都是直接解析html源码进行分析解析即可.但是,有一种情 ...
- python爬取动态网页2,从JavaScript文件读取内容
import requests import json head = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) ...
- phantomjs+selenium实现爬取动态网址
之前使用 selenium + firefox驱动浏览器来实现爬取动态网址,但是firefox经常更新,更新后时常会导致webdriver启动不来,所以改用phantomjs+selenium来改善一 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
随机推荐
- 力扣24(java&python)-两两交换链表中的节点(中等)
题目: 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点.你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换) 示例 1: 输入:head = [1,2,3,4] 输出:[ ...
- HarmonyOS NEXT应用开发—自定义视图实现Tab效果
介绍 本示例介绍使用Text.List等组件,添加点击事件onclick,动画,animationTo实现自定义Tab效果. 效果预览图 使用说明 点击页签进行切换,选中态页签字体放大加粗,颜色由灰变 ...
- 龙蜥开源内核追踪利器 Surftrace:协议包解析效率提升 10 倍! | 龙蜥技术
简介:如何将网络报文与内核协议栈清晰关联起来精准追踪到关注的报文行进路径呢? 文/系统运维 SIG Surftrace 是由系统运维 SIG 推出的一个 ftrace 封装器和开发编译平台,让用 ...
- 即学即会 Serverless | 初识 Serverless
简介:Serverless 架构被越来越多的业务所采纳,成为其技术选型,大多数开发者已经跨越对 Serverless 概念了解,切实向落地实践出发.本文带大家一探究竟,为什么说 Serverless ...
- 深入解读 Flink SQL 1.13
简介: Apache Flink 社区 5 月 22 日北京站 Meetup 分享内容整理,深入解读 Flink SQL 1.13 中 5 个 FLIP 的实用更新和重要改进. 本文由社区志愿者陈政羽 ...
- 技术干货 | Native 页面下如何实现导航栏的定制化开发?
简介: 通过不同实际场景的描述,供大家参考完成 Native 页面的定制化开发. 很多 mPaaS Coder 在接入 H5 容器后都会对容器的导航栏进行深度定制,本文旨在通过不同实际场景的描述 ...
- [Go] Colly 使用 POST 提交 application/x-www-form-urlencoded 示范
Colly 提供了 Post 和 PostRaw 方法,它们的参数类型不一样,需要注意. 目标地址接受指定的 Content-Type,可以通过设置 request Header. 局部代码: // ...
- python+requests爬取B站视频保存到本地
import os import datetime from django.test import TestCase # Create your tests here. import requests ...
- EasyRepro与测试自动化( 一) 概览
EasyRepro是一个框架,允许在特定的Dynamics 365组织上执行自动化UI测试.你可以使用它来自动化冒烟测试.回归测试和负载测试等.该框架是由开源项目Selenium构建的,Seleniu ...
- SpringBoot3.1.5对应新版本SpringCloud开发(2)-Eureka的负载均衡
Eureka的负载均衡 负载均衡原理 负载均衡流程 老版本流程介绍 当order-servic发起的请求进入Ribbon后会被LoadBalancerInterceptor负载均衡拦截器拦截,拦截器获 ...