使用Jsoup和htmlunit爬取动态网页
在对http://zkgg.tjtalents.com.cn/newzxxx.jsp这个网页爬取内容时,如果只使用Jsoup进行解析的话,起内部的a href标签内容无法获取到。


但是实际上通过
Document doc = Jsoup.connect(url).get();
获取到的文档只是newzxxx.jsp中respose的内容。
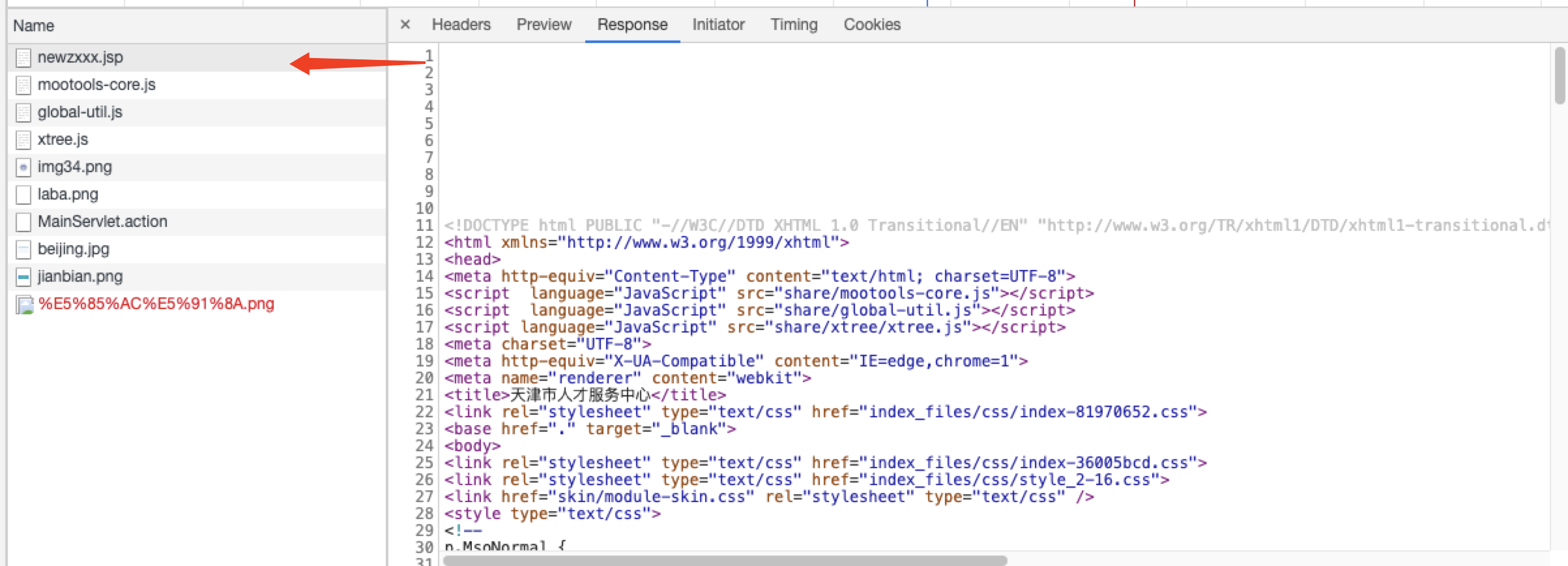
实际我们想要的内容通过js加载得到的。
function query(){
$("formzx").fid.value = "C09.01.01.05";
$("formzx").set('send',{
url: 'MainServlet.action',
onRequest: function(){
},
//成功的回调函数
onSuccess: function(responseText){
$('listspan').innerHTML = responseText;
},
//失败的回调函数. 404. 500. 以及返回JSON串success为false时执行
onFailure: function(responseText){
$('listspan').innerHTML = responseText;
}
});
$("formzx").send();
}
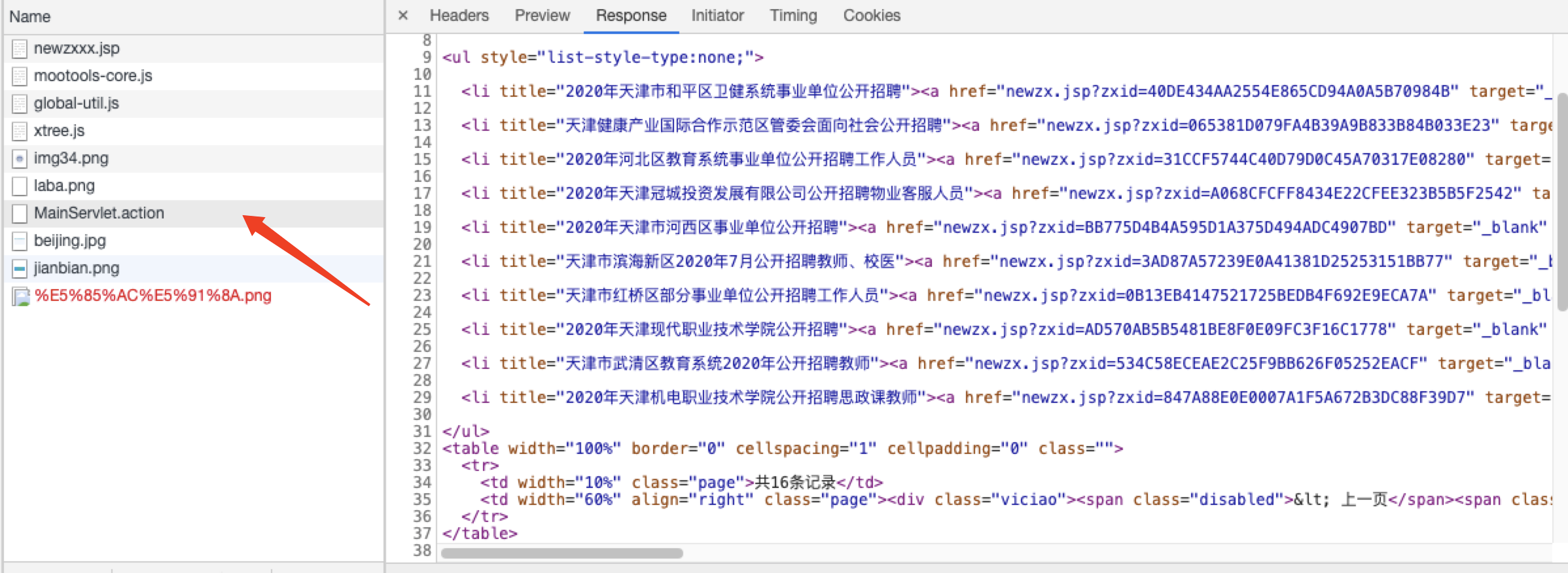
所以这种情况我们可以使用htmlunit来模拟浏览器,并且等待js加载完毕后,再读取整个页面。
public String getPageWaitJS (String url) throws IOException {
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(3*1000);
String pageXml = page.asXml(); //以xml的形式获取响应文本
return pageXml;
}
这样的话就能够获取全部的html页面,之后再使用Jsoup来对页面进行解析即可,这里就不放上Jsoup的代码了。
使用Jsoup和htmlunit爬取动态网页的更多相关文章
- R语言爬取动态网页之环境准备
在R实现pm2.5地图数据展示文章中,使用rvest包实现了静态页面的数据抓取,然而rvest只能抓取静态网页,而诸如ajax异步加载的动态网页结构无能为力.在R语言中,爬取这类网页可以使用RSele ...
- Jsoup配合 htmlunit 爬取异步加载的网页
加入 jsoup 和 htmlunit 的依赖 <dependency> <groupId>org.jsoup</groupId> <artifactId&g ...
- 记录几个爬取动态网页时的问题(下拉框,旧的元素无法获取,获取的源代码和f12看到的不一致,爬取延迟)
更新.....这个动态网页其实直接抓取ajax请求就可以了,很简单,我之前想复杂了,虽然也实现了,但是效率极低,不过没关系,就当作是对Selenium的一次学习吧 1.最近在爬取一个动态网页,其中为了 ...
- python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了? 浏览器请求数据方式:浏览器向服务器的api(例 ...
- 爬虫(三)通过Selenium + Headless Chrome爬取动态网页
一.Selenium Selenium是一个用于Web应用程序测试的工具,它可以在各种浏览器中运行,包括Chrome,Safari,Firefox 等主流界面式浏览器. 我们可以直接用pip inst ...
- 利用selenium并使用gevent爬取动态网页数据
首先要下载相应的库 gevent协程库:pip install gevent selenium模拟浏览器访问库:pip install selenium selenium库相应驱动配置 https: ...
- 爬取动态网页:Selenium
参考:http://blog.csdn.net/wgyscsf/article/details/53454910 概述 在爬虫过程中,一般情况下都是直接解析html源码进行分析解析即可.但是,有一种情 ...
- python爬取动态网页2,从JavaScript文件读取内容
import requests import json head = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) ...
- phantomjs+selenium实现爬取动态网址
之前使用 selenium + firefox驱动浏览器来实现爬取动态网址,但是firefox经常更新,更新后时常会导致webdriver启动不来,所以改用phantomjs+selenium来改善一 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
随机推荐
- Apsara Stack 技术百科 | 边缘场景智能云化,让云无处不在
简介:在过去十年间,随着计算技术的发展和移动互联网的广泛普及,各行业对数据本地计算和智能分析的需求与日俱增,越来越多的应用场景被接入了终端设备,导致终端侧的数据陡然增长,中心节点的处理算力不堪重负. ...
- 连续三年入围 Gartner 容器竞争格局,阿里云容器服务新布局首次公开
简介: 阿里云连续三年国内唯一入围Gartner容器竞争格局,解读业界'顶流'的产品布局. 近日,国际知名信息技术咨询机构Gartner发布2021年容器竞争格局报告,阿里云成为国内唯一连续三年入选的 ...
- 【实践案例】Databricks 数据洞察在美的暖通与楼宇的应用实践
简介: 获取更详细的 Databricks 数据洞察相关信息,可至产品详情页查看:https://www.aliyun.com/product/bigdata/spark 作者 美的暖通与楼宇事业部 ...
- [Go] VsCode 的 Golang 环境设置与代码跳转支持
终端执行: go env -w GO111MODULE=on go env -w GOPROXY=https://goproxy.io,direct WIndows下自定义指定 GOPATH 路径 ...
- [GPT] Linux 如何查看 crontab 的运行记录
要查看crontab的运行记录,可以使用以下命令: $ grep CRON /var/log/syslog 或者 $ tail /var/log/syslog 这将在 /var/log/syslo ...
- python之爬虫基础
1.爬虫概念 其实就是模拟浏览器发送请求获取相应的数据 1.模拟请求 2.获取数据 3.筛选数据 4.保存数据 爬虫仅仅是将浏览器可以访问到的数据通过代码的方式加速访问 用于更加快速的获取数据,提升工 ...
- uiautomator2环境搭建+元素定位(安卓)
一.环境搭建 1.安装uiautomator2 在终端使用pip安装即可 pip install uiautomator2 2.安装adb 可参考:https://www.cnblogs.com/li ...
- Solution Set - 矩阵加速
A[HDU2604]求不含子串010和000的,长为\(n\)的01序列数. B[HDU6470]数列\(\{a_n\}:a_1=1,a_2=2,a_n=a_{n-1}+2a_{n-2}+n^3\), ...
- Solution Set - CDQ分治&整体二分
A[洛谷P2163].给定平面上若干个点,多次询问给定矩形内的点数. B[洛谷P3810].给定若干个三元组,对所有\(k\),求这样三元组的个数:恰有\(k\)个三元组,满足其每个分量都不超过它的相 ...
- ansible系列(22)--ansible的Facts Variables
目录 1 Ansible Facts Variables 1.1 facts的获取方法 1.2 根据主机IP地址生成Redis配置文件 1.3 根据主机CPU核数生成Nginx配置 1.4 根据主机内 ...