Storm 集群的搭建及其Java编程进行简单统计计算
一、Storm集群构建
编写storm 与 zookeeper的yml文件
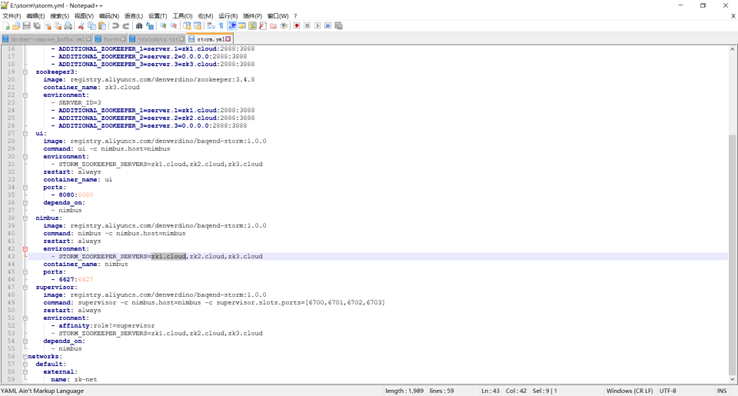
storm yml文件的编写
具体如下:
version: '2'
services:
zookeeper1:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk1.cloud
environment:
- SERVER_ID=1
- ADDITIONAL_ZOOKEEPER_1=server.1=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper2:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk2.cloud
environment:
- SERVER_ID=2
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper3:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk3.cloud
environment:
- SERVER_ID=3
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=0.0.0.0:2888:3888
ui:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: ui -c nimbus.host=nimbus
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
restart: always
container_name: ui
ports:
- 8080:8080
depends_on:
- nimbus
nimbus:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: nimbus -c nimbus.host=nimbus
restart: always
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
container_name: nimbus
ports:
- 6627:6627
supervisor:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: supervisor -c nimbus.host=nimbus -c supervisor.slots.ports=[6700,6701,6702,6703]
restart: always
environment:
- affinity:role!=supervisor
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
depends_on:
- nimbus
networks:
default:
external:
name: zk-net
拉取Storm搭建需要的镜像,这里我选择镜像版本为 zookeeper:3.4.8 storm:1.0.0
键入命令:
docker pull zookeeper:3.4.8 docker pull storm:1.0.0
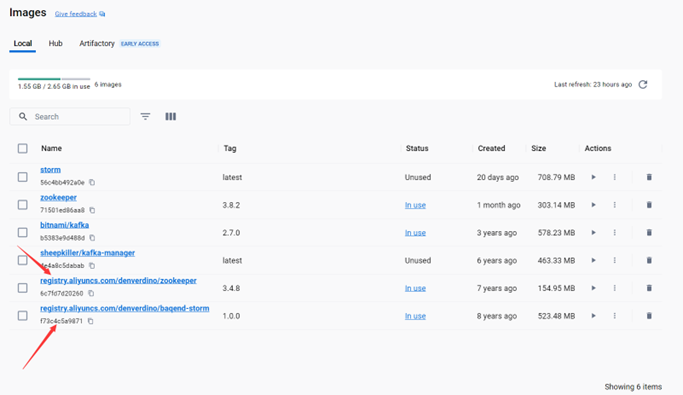
storm镜像 获取
使用docker-compose 构建集群
在power shell中执行以下命令:
docker-compose -f storm.yml up -d
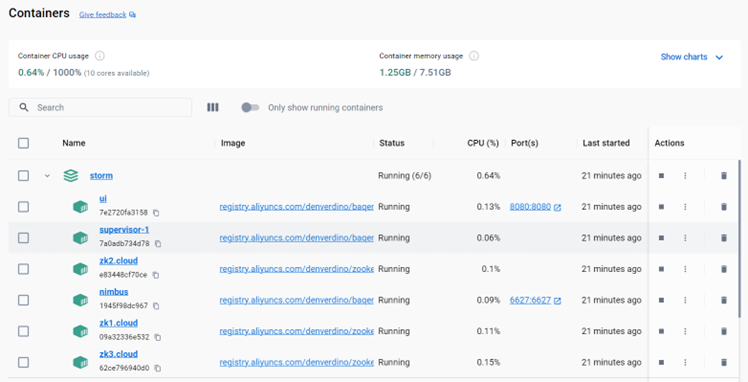
docker-compose 构建集群
在浏览器中打开localhost:8080 可以看到storm集群的详细情况
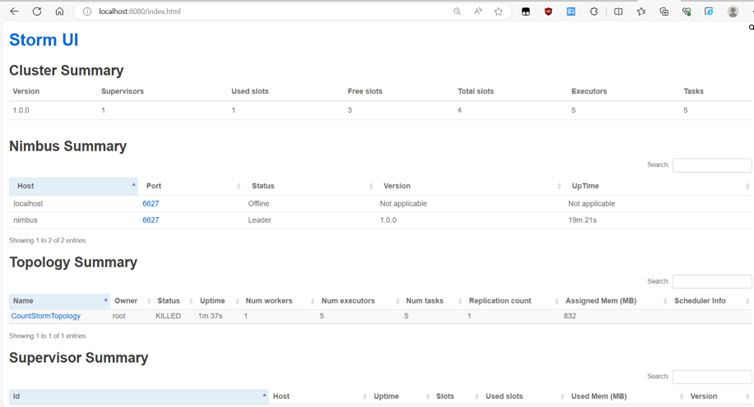
storm UI 展示
二、Storm统计任务
统计股票交易情况交易量和交易总金额 (数据文件存储在csv文件中)
编写DataSourceSpout类
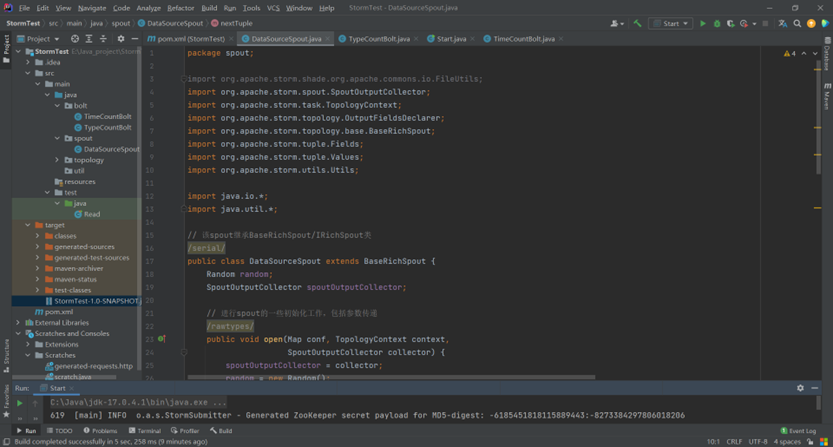
DataSourceSpout类
编写bolt类
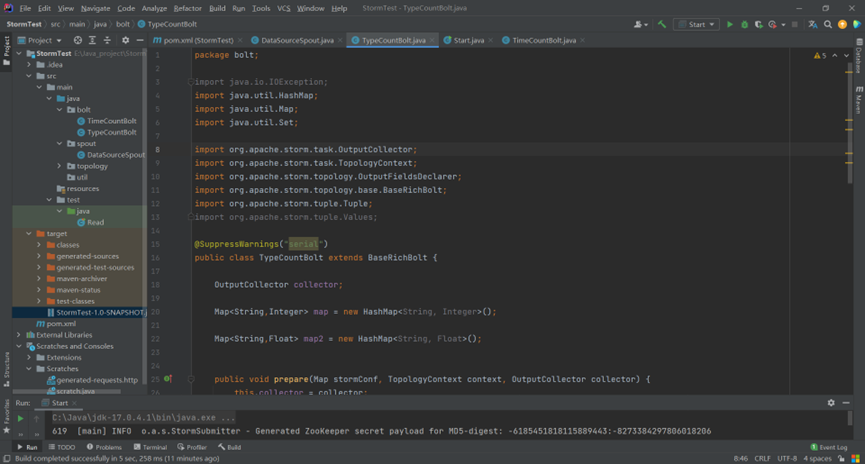
编写topology类
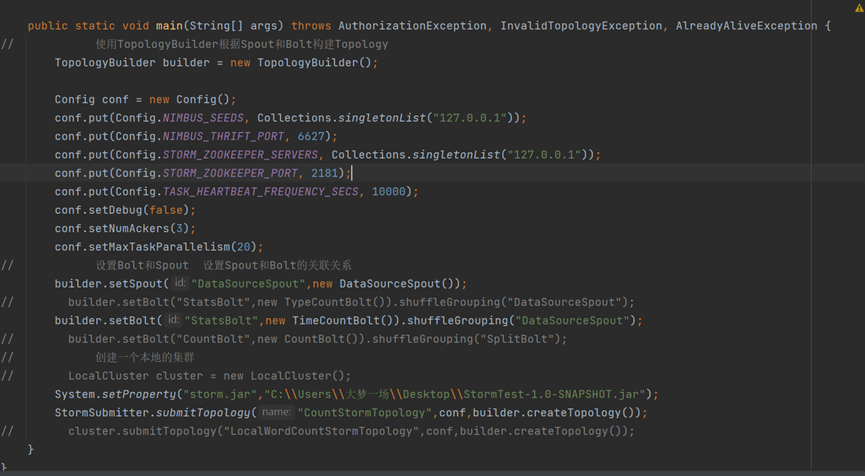
需要注意的是 Storm Java API 下有本地模型和远端模式
在本地模式下的调试不依赖于集群环境,可以进行简单的调试
如果需要使用生产模式,则需要将
1、 编写和自身业务相关的spout和bolt类,并将其打包成一个jar包
2、将上述的jar包放到客户端代码能读到的任何位置,
3、使用如下方式定义一个拓扑(Topology)
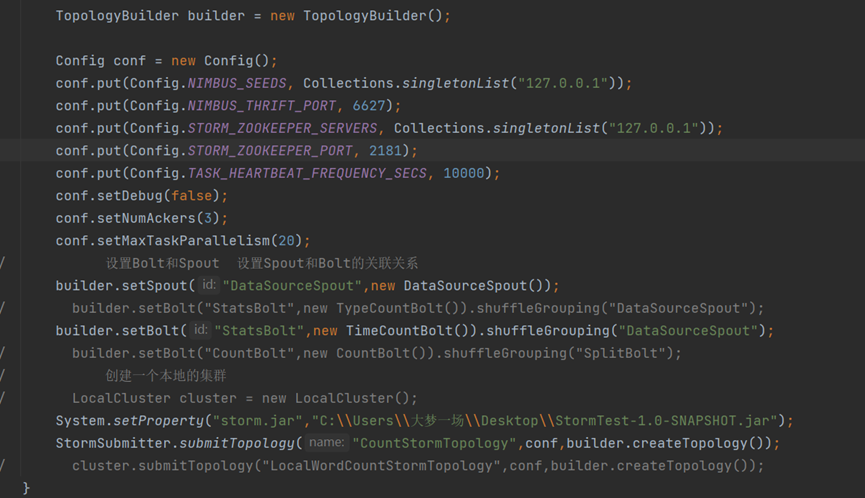
演示结果:
本地模式下的调试:
正在执行:
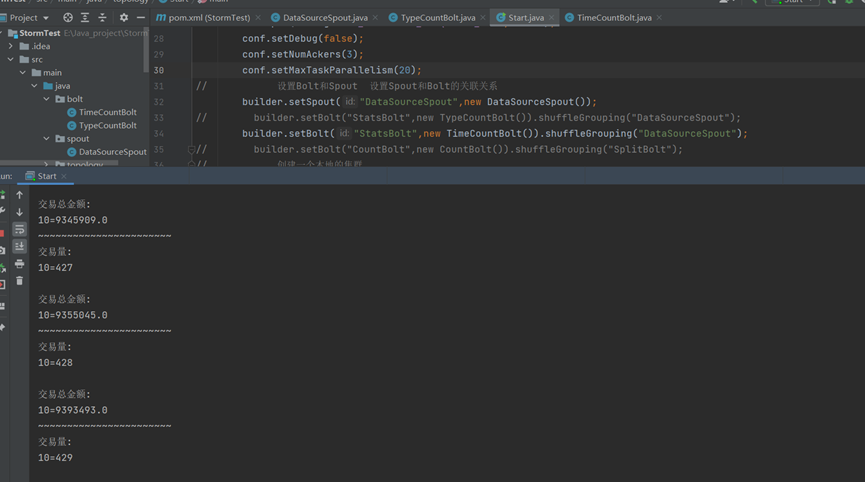
根据24小时
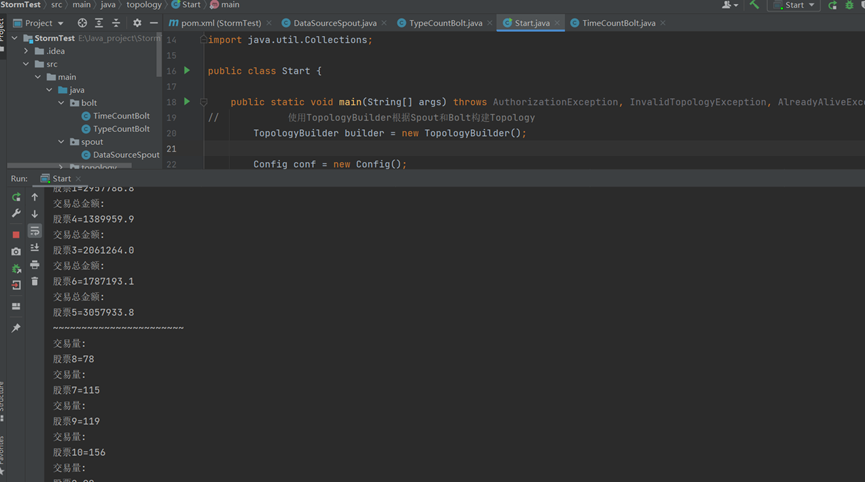
根据股票种类
生产模式:

向集群提交topology
三、核心计算bolt的代码
1.统计不同类型的股票交易量和交易总金额:
package bolt;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
@SuppressWarnings("serial")
public class TypeCountBolt extends BaseRichBolt {
OutputCollector collector;
Map<String,Integer> map = new HashMap<String, Integer>();
Map<String,Float> map2 = new HashMap<String, Float>();
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] data = line.split(",");
Integer count = map.get(data[2]);
Float total_amount = map2.get(data[2]);
if(count==null){
count = 0;
}
if(total_amount==null){
total_amount = 0.0f;
}
count++;
total_amount+=Float.parseFloat(data[3]) * Integer.parseInt(data[4]);
map.put(data[2],count);
map2.put(data[2],total_amount);
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~");
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
for(Map.Entry<String,Integer> entry :entrySet){
System.out.println("交易量:");
System.out.println(entry);
}
System.out.println();
Set<Map.Entry<String,Float>> entrySet2 = map2.entrySet();
for(Map.Entry<String,Float> entry :entrySet2){
System.out.println("交易总金额:");
System.out.println(entry);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
2. 统计不同每个小时的交易量和交易总金额
package bolt;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class TimeCountBolt extends BaseRichBolt {
OutputCollector collector;
Map<Integer,Integer> map = new HashMap<Integer, Integer>();
Map<Integer,Float> map2 = new HashMap<Integer, Float>();
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] data = line.split(",");
Date date = new Date();
SimpleDateFormat dateFormat= new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
try {
date = dateFormat.parse(data[0]);
} catch (ParseException e) {
e.printStackTrace();
}
Integer count = map.get(date.getHours());
Float total_amount = map2.get(date.getHours());
if(count==null){
count = 0;
}
if(total_amount==null){
total_amount = 0.0f;
}
count++;
total_amount+=Float.parseFloat(data[3]) * Integer.parseInt(data[4]);
map.put(date.getHours(),count);
map2.put(date.getHours(),total_amount);
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~");
Set<Map.Entry<Integer,Integer>> entrySet = map.entrySet();
for(Map.Entry<Integer,Integer> entry :entrySet){
System.out.println("交易量:");
System.out.println(entry);
}
System.out.println();
Set<Map.Entry<Integer,Float>> entrySet2 = map2.entrySet();
for(Map.Entry<Integer,Float> entry :entrySet2){
System.out.println("交易总金额:");
System.out.println(entry);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
Storm 集群的搭建及其Java编程进行简单统计计算的更多相关文章
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 系列(四)—— Storm 集群环境搭建
一.集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus ...
- storm集群环境搭建
1.环境 Java环境 卸载虚机环境中自带的openJdk,安装sun的jdk,配置环境变量 2.安装storm 下载storm安装包 解压到安装目录,配置环境变量 vi /etc/profile # ...
- storm集群快速搭建
sudo mkdir /export/serverssudo chmod -R 777 /exportmkdir /export/servers tar -zxvf apache-storm-1.0. ...
- Storm集群的搭建
storm的环境和hadoop的环境没有任何关系 1.安装Zookeeper集群 2.解压storm 3.修改文件conf/storm.yaml 3.1.配置zookeeper服务器 storm.zo ...
- centos7:storm集群环境搭建
1.安装storm 下载storm安装包 在线下载 wget http://apache.fayea.com/storm/apache-storm-1.1.1/apache-storm-1.1.1.t ...
随机推荐
- TIDB - 分布式数据库
TIDB(一) 重点 TIDB核心 数据存储-RocksDB Raft 协议 选举 数据同步 MVCC 表数据与kv映射关系 索引数据与kv 映射关系 元数据和sql 层计算 PD调度 HTAP 特性 ...
- 《Kali渗透基础》10. 提权、后渗透
@ 目录 1:提权 2:Admin 提权为 System 2.1:at 2.2:sc 2.3:SysInternal Suite 2.4:进程注入提权 3:抓包嗅探 4:键盘记录 5:本地缓存密码 5 ...
- 在线问诊 Python、FastAPI、Neo4j — 创建 饮食节点
目录 饮食数据 创建节点 根据疾病.症状,判断出哪些饮食不能吃,哪些建议多吃 饮食数据 foods_data.csv 建议值用""引起来.避免中间有,号造成误识别 饮食 " ...
- 树莓派3B/3B+的串口使用
树莓派包含两个串口,一个称之为硬件串口(/dev/ttyAMA0),一个称之为mini串口(/dev/ttyS0).硬件串口由硬件实现,有单独的波特率时钟源,性能高.可靠.mini串口时钟源是由CPU ...
- 实验四报告: 熟悉Python字典、集合、字符串的使用
实验目标 本实验的主要目标是熟悉Python中字典.集合.字符串的创建和操作,包括字典的创建.访问.修改和合并,集合的创建.访问以及各种集合运算,以及字符串的创建.格式化和常用操作. 实验要求 通过编 ...
- unity利用Rigibody实现第一人称移动
1. CameraRotation脚本,将它给MainCamera,实现上下视角旋转 using System.Collections; using System.Collections.Generi ...
- python包引用方式总结
本文为博主原创,转载请注明出处: 在Python中,有多种引用包的方式.以下是常见的方式: 1. import语句 import语句是最常见和推荐的引用包的方式.它允许你引入整个包或包中的特定模块/子 ...
- 2023-10-25:用go语言,假如某公司目前推出了N个在售的金融产品(1<=N<=100) 对于张三,用ai表示他购买了ai(0<=ai<=10^4)份额的第i个产品(1<=i<=N) 现给出K(
2023-10-25:用go语言,假如某公司目前推出了N个在售的金融产品(1<=N<=100) 对于张三,用ai表示他购买了ai(0<=ai<=10^4)份额的第i个产品(1& ...
- 2022/7/26 暑期集训 pj组第6次%你赛
个人第3次 又是下午打,旁边那帮 不知好歹的 入门组小孩们又在吵吵... T1 老师是不是放反了? T1 是蓝题诶 理所应当地 跳过 然后就忘了写了,连样例也没打...样例可是有7分诶! 到现在也没写 ...
- 全面掌握胶囊网络:从基础理论到PyTorch实战
本文全面深入地探讨了胶囊网络(Capsule Networks)的原理.构建块.数学模型以及在PyTorch中的实现.通过本文,读者不仅能够理解胶囊网络的基础概念和高级数学原理,还能掌握其在实际问题中 ...