Storm 系列(四)—— Storm 集群环境搭建
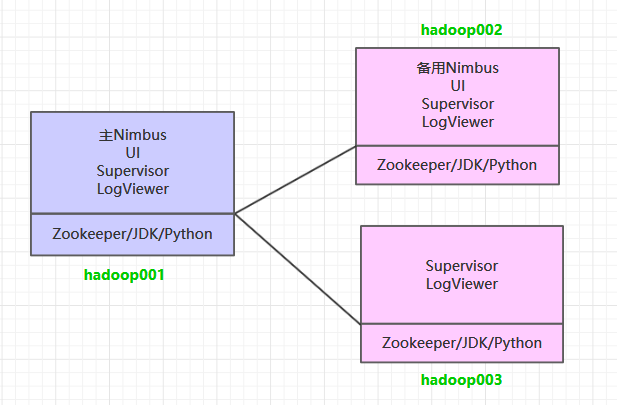
一、集群规划
这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nimbus。
二、前置条件
Storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。同时为了保证高可用,这里我们不采用 Storm 内置的 Zookeeper,而采用外置的 Zookeeper 集群。由于这三个软件在多个框架中都有依赖,其安装步骤单独整理至 :
三、集群搭建
1. 下载并解压
下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
# 解压
tar -zxvf apache-storm-1.2.2.tar.gz
2. 配置环境变量
# vim /etc/profile添加环境变量:
export STORM_HOME=/usr/app/apache-storm-1.2.2
export PATH=$STORM_HOME/bin:$PATH使得配置的环境变量生效:
# source /etc/profile3. 集群配置
修改 ${STORM_HOME}/conf/storm.yaml 文件,配置如下:
# Zookeeper集群的主机列表
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
# Nimbus的节点列表
nimbus.seeds: ["hadoop001","hadoop002"]
# Nimbus和Supervisor需要使用本地磁盘上来存储少量状态(如jar包,配置文件等)
storm.local.dir: "/home/storm"
# workers进程的端口,每个worker进程会使用一个端口来接收消息
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703supervisor.slots.ports 参数用来配置 workers 进程接收消息的端口,默认每个 supervisor 节点上会启动 4 个 worker,当然你也可以按照自己的需要和服务器性能进行设置,假设只想启动 2 个 worker 的话,此处配置 2 个端口即可。
4. 安装包分发
将 Storm 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Storm 的环境变量。
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop002:/usr/app/
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop003:/usr/app/四. 启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start4.2 启动Storm集群
因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,执行下面的命令:
hadoop001 & hadoop002 :
# 启动主节点 nimbus
nohup sh storm nimbus &
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动UI界面 ui
nohup sh storm ui &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &hadoop003 :
hadoop003 上只需要启动 supervisor 服务和 logviewer 服务:
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &4.3 查看集群
使用 jps 查看进程,三台服务器的进程应该分别如下:

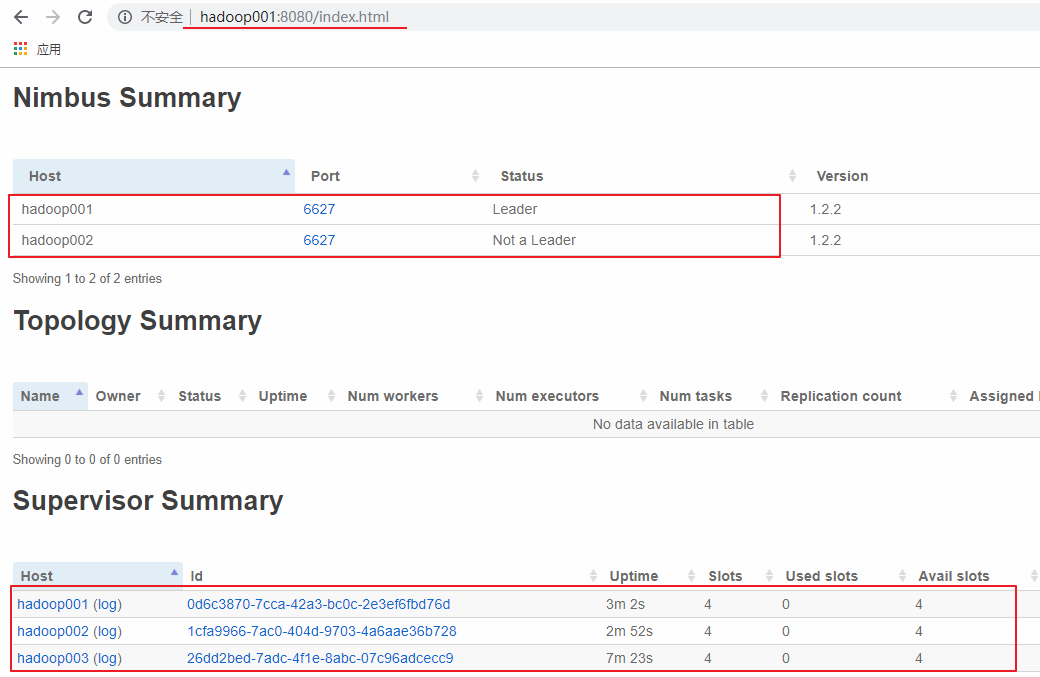
访问 hadoop001 或 hadoop002 的 8080 端口,界面如下。可以看到有一主一备 2 个 Nimbus 和 3 个 Supervisor,并且每个 Supervisor 有四个 slots,即四个可用的 worker 进程,此时代表集群已经搭建成功。
五、高可用验证
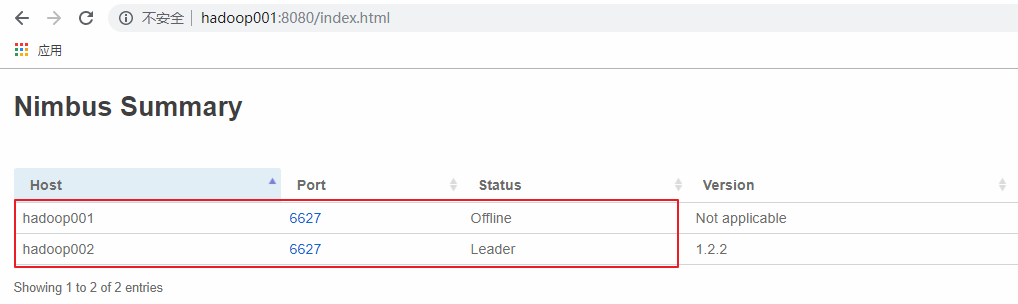
这里手动模拟主 Nimbus 异常的情况,在 hadoop001 上使用 kill 命令杀死 Nimbus 的线程,此时可以看到 hadoop001 上的 Nimbus 已经处于 offline 状态,而 hadoop002 上的 Nimbus 则成为新的 Leader。
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(四)—— Storm 集群环境搭建的更多相关文章
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- ZooKeeper 系列(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 1.2 解压 1.3 配置环境变量 1.4 修改配置 1.5 启动 1. ...
- ZooKeeper系列(二)—— Zookeeper 单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本 Zookeeper,这里我下载的版本 3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- HBase —— 集群环境搭建
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
随机推荐
- 消息中间件-activemq实战之消息持久化(六)
对于activemq消息的持久化我们在第二节的时候就简单介绍过,今天我们详细的来分析一下activemq的持久化过程以及持久化插件.在生产环境中为确保消息的可靠性,我们肯定的面临持久化消息的问题,今天 ...
- Spring入门(七):Spring Profile使用讲解
1. 使用场景 在日常的开发工作中,我们经常需要将程序部署到不同的环境,比如Dev开发环境,QA测试环境,Prod生产环境,这些环境下的一些配置肯定是不一样的,比如数据库配置,Redis配置,Rabb ...
- DFS-深度优先算法解决迷宫问题
/*main.cpp*/#define _CRT_SECURE_NO_WARNINGS #include<iostream> using namespace std; int sr, sc ...
- Cause: java.lang.NumberFormatException: For input string: "D"
异常:Cause: java.lang.NumberFormatException: For input string: "D" 问题回显: 原因分析:'D'只有1位,被认为是ch ...
- vscode 支持 threejs 的智能提示
VSCode Typings and Intellisense: Dummy Learning VS-Code 1 Jun 20, 2016 Updated on Jun 20 2016 for 1. ...
- Hive 系列(一)—— Hive 简介及核心概念
一.简介 Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 ...
- 多线程编程-synchronized
使用取钱的demo来模拟实现线程的同步 package com.iotec.synchronizedTest; import java.io.ObjectInputStream; public cla ...
- pak文件的打包和解包
pak格式的文件 一般游戏有资源 游戏素材会打包放进去 比如游戏语音 游戏多加点语音 多加一些贴图资源 外部文件实现的 素材--->pak文件--->用的时候从文件中取出来 文件的打包 ...
- nginx之location详解
location有定位的意思,根据uri来进行不同的定位,在虚拟主机中是必不可少的,location可以定位网站的不同部分,定位到不同的处理方式上. location匹配分类 精准匹配 一般匹配 正则 ...
- 搭建SFTP服务器,允许一个或多个用户拥有一个或多个目录的rwx权限
1.引言 sftp可以为传输文件提供一种安全的网络的加密方法.sftp 与 ftp 有着几乎一样的语法和功能.SFTP 为 SSH的其中一部分,是一种传输档案至 Blogger 伺服器的安全方式.其实 ...