Stochastic Gradient Descent收敛判断及收敛速度的控制
要判断Stochastic Gradient Descent是否收敛,可以像Batch Gradient Descent一样打印出iteration的次数和Cost的函数关系图,然后判断曲线是否呈现下降且区域某一个下限值的状态。由于训练样本m值很大,而对于每个样本,都会更新一次θ向量(权重向量),因此可以在每次更新θ向量前,计算当时状况下的cost值,然后每1000次迭代后,计算一次average cost的值。然后打印出iteration和cost之间的关系。
1、不同曲线图代表的含义及应对策略
可能会看到的曲线图有如下几种:
情况1

这样的曲线说明算法已经收敛。
如果我们使用小一点的学习率α,那么可能最终会训练到比较好的θ向量(红色线)

但是小的学习率也意味着更长的训练时间。
情况2
如果我们不是1000次迭代计算并打印一次,而是5000次迭代后才计算并打印一次。那么曲线可能会更加平滑一些(绿色线)。

情况3
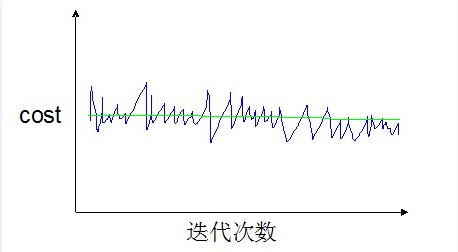
如果我们得到的曲线(1000次迭代并打印)是波动很剧烈,并且没有显示任何下降趋势,如下图:

那么有两种可能,一噪声太剧烈而无法看出算法收敛的趋势;二算法没有收敛。
这种情况下,我们可以调整打印的步长(比如5000次迭代才计算并打印一次),那么可能会得到两种不同的曲线(如下两幅图所示)。
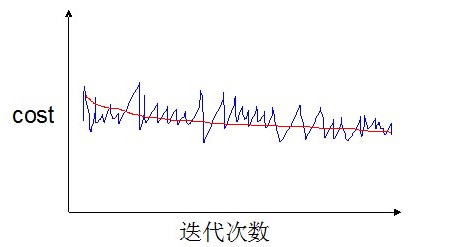
如果得到得是类似这条红色的曲线,那么说明算法已经收敛或已经表现出收敛的趋势了。如果得到的是如下图所示的绿色的线,说明算法没有收敛。
情况4
还有一种情况,就是曲线不但没有呈现下降的趋势,反而出现了上升的趋势,如下图:
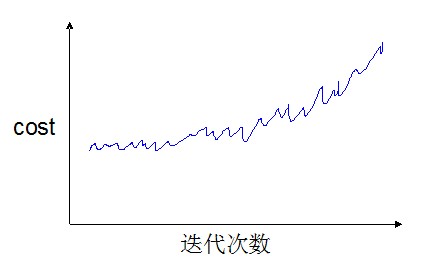
这说明学习率α设置得过大,需要调小学习率。
2、学习率的设置
当学习率比较小的时候,可以训练出更优的权重向量。但是较小的学习率也意味着更长的训练时间,而且如果是非凸问题则还有可能会陷入局部解中。那么,如果使用动态递减的学习率(即在学习开始之初,学习率较大,然后根据迭代次数的增加,学习率逐渐减小)也许会好一些。这样我们可以用一个式子来按照迭代次数调整学习率,例如:

常量1和常量2的目的是为了保证学习率在一个正常的范围内(不至于当循环次数很高或很低时,学习率会变得过大或过小)。
通过调整学习率(手工或如上式自动调整),就可以控制算法收敛的速度。
Reference:
Andrew Ng Stochastic Gradient Descent Convergence (12 min)
Stochastic Gradient Descent收敛判断及收敛速度的控制的更多相关文章
- Stochastic Gradient Descent
一.从Multinomial Logistic模型说起 1.Multinomial Logistic 令为维输入向量; 为输出label;(一共k类); 为模型参数向量: Multinomial Lo ...
- Stochastic Gradient Descent 随机梯度下降法-R实现
随机梯度下降法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 批量梯度下降法在权值更新前对所有样本汇总 ...
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 基于baseline、svd和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.3部分内容(其余部分会陆续补充上来).koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长.考虑到写文章目 ...
- 基于baseline和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.1 部分内容(其余部分会陆续补充上来). koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长.考虑到写文 ...
- Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法.其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动.通过柯 ...
- 随机梯度下降法(Stochastic gradient descent, SGD)
BGD(Batch gradient descent)批量梯度下降法:每次迭代使用所有的样本(样本量小) Mold 一直在更新 SGD(Stochastic gradientdescent)随机 ...
随机推荐
- CString与UTF8互转代码
这个代码网上很多,留在这里做个备份. static std::string ConvertCStringToUTF8( CString strValue ) { std::wstring wbuffe ...
- Generating phar.phar chmod: cannot access `ext/phar/phar.phar': No such file or directory make: [ext/phar/phar.phar] Error 1 (ignored)
make install出现了cp: cannot stat `ext/phar/phar.phar': No such file or directory 于是我又: cd ext/phar/ls ...
- isset、empty、var==null、is_null、var===null详细理解
//isset: 判断变量是否被初始化 //它并不会判断变量是否为空,并且可能用来判断数组中元素是否被定义 //听说在数组用isset与array_key_exists高出4倍 $a = " ...
- android自动化测试--appium运行的坑问题及解决方法
问题 1. error: Failed to start an Appium session, err was: Error: Requested a new session but one was ...
- 轻量级桌面 openbox + tint2 + conky + stalonetray + pcmanfm + xcompmgr
openbox+tint2+pnmixer+conky=轻量级archlinux桌面环境设置备忘 缘起 机器上的Ubuntu 12.04有一段时间没有使用了,最近在用的时候发现频繁死机的情况,开始以为 ...
- [转]GFS架构分析
Google文件系统(Google File System,GFS)是构建在廉价的服务器之上的大型分布式系统.它将服务器故障视为正常现象,通过软件的方式自动容错,在保证系统可靠性和可用性的同时,大大减 ...
- VirtualBox虚拟机增加CentOS根目录容量 LVM扩容
对于目前的网络开发者来说,比较好的搭档就是Win7+VirtualBox+CentOS的组合,既可以发挥Linux强大的网络服务功能,也可以有效的隔离各项服务拖慢系统,影响系统的运行,对于新手来说可以 ...
- 【JavaScript】浅析ajax的使用
目录结构: contents structure [+] Ajax简介 Ajax的工作原理 Ajax的使用步骤 使用原生的js代码 使用JQuery代码 JQuery中常用的Ajax函数 $.ajax ...
- logstash_output_mongodb插件用途及安装详解
安装详情参见:http://mojijs.com/2017/03/222639/index.html http://www.jianshu.com/p/8516e51e105d
- table中background背景图片自动拉伸
<table background="login/image/jiaozhouwan.jpg" style="background-size: 100% 100% ...