机器学习-随机梯度下降(Stochastic gradient descent)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

项目合作联系QQ:231469242
http://scikit-learn.org/stable/modules/sgd.html
Stochastic Gradient Descent (SGD) is a simple yet very efficient approach to discriminative learning of linear classifiers under convex loss functions such as (linear) Support Vector Machines and Logistic Regression. Even though SGD has been around in the machine learning community for a long time, it has received a considerable amount of attention just recently in the context of large-scale learning.
SGD has been successfully applied to large-scale and sparse machine learning problems often encountered in text classification and natural language processing. Given that the data is sparse, the classifiers in this module easily scale to problems with more than 10^5 training examples and more than 10^5 features.
The advantages of Stochastic Gradient Descent are:
- Efficiency.
- Ease of implementation (lots of opportunities for code tuning).
The disadvantages of Stochastic Gradient Descent include:
- SGD requires a number of hyperparameters such as the regularization parameter and the number of iterations.
- SGD is sensitive to feature scaling.
随机梯度下降(SGD)是一种简单但非常有效的方法,用于在线性分类器下的线性分类器的判别学习,如(线性)支持向量机和Logistic回归。虽然SGD长期以来一直在机器学习社区中出现,但最近在大规模学习的背景下它已经受到了相当多的关注。
SGD已成功应用于文本分类和自然语言处理中经常遇到的大规模稀疏机器学习问题。鉴于数据稀疏,此模块中的分类器很容易扩展到超过10 ^ 5个训练样例和超过10 ^ 5个特征的问题。
随机梯度下降的优点是:
效率。
易于实现(许多代码调优的机会)。
随机梯度下降的缺点包括:
SGD需要许多超参数,例如正则化参数和迭代次数。
SGD对功能扩展很敏感。
python脚本
from sklearn.linear_model import SGDClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = SGDClassifier(loss="hinge", penalty="l2")
clf.fit(X, y)
梯度下降(GD)是最小化风险函数、损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正。
下面的h(x)是要拟合的函数,J(theta)损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的记录条数,i是参数的个数。

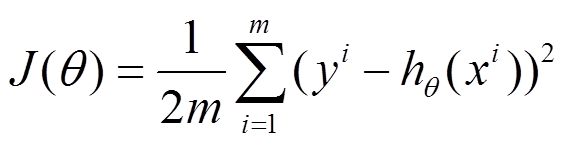
1、批量梯度下降的求解思路如下:
(1)将J(theta)对theta求偏导,得到每个theta对应的的梯度

(2)由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta

(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度!!所以,这就引入了另外一种方法,随机梯度下降。
2、随机梯度下降的求解思路如下:
(1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:

(2)每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta

(3)随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
3、对于上面的linear regression问题,与批量梯度下降对比,随机梯度下降求解的会是最优解吗?
(1)批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小。
(2)随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
4、梯度下降用来求最优解,哪些问题可以求得全局最优?哪些问题可能局部最优解?
对于上面的linear regression问题,最优化问题对theta的分布是unimodal,即从图形上面看只有一个peak,所以梯度下降最终求得的是全局最优解。然而对于multimodal的问题,因为存在多个peak值,很有可能梯度下降的最终结果是局部最优。
5、随机梯度和批量梯度的实现差别
以前一篇博文中NMF实现为例,列出两者的实现差别(注:其实对应Python的代码要直观的多,以后要练习多写python!)
// 随机梯度下降,更新参数
public void updatePQ_stochastic(double alpha, double beta) {
for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rij : Ri) {
// eij=Rij.weight-PQ for updating P and Q
double PQ = 0;
for (int k = 0; k < K; k++) {
PQ += P[i][k] * Q[k][Rij.dim];
}
double eij = Rij.weight - PQ; // update Pik and Qkj
for (int k = 0; k < K; k++) {
double oldPik = P[i][k];
P[i][k] += alpha
* (2 * eij * Q[k][Rij.dim] - beta * P[i][k]);
Q[k][Rij.dim] += alpha
* (2 * eij * oldPik - beta * Q[k][Rij.dim]);
}
}
}
} // 批量梯度下降,更新参数
public void updatePQ_batch(double alpha, double beta) { for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature(); for (Feature Rij : Ri) {
// Rij.error=Rij.weight-PQ for updating P and Q
double PQ = 0;
for (int k = 0; k < K; k++) {
PQ += P[i][k] * Q[k][Rij.dim];
}
Rij.error = Rij.weight - PQ;
}
} for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rij : Ri) {
for (int k = 0; k < K; k++) {
// 对参数更新的累积项
double eq_sum = 0;
double ep_sum = 0; for (int ki = 0; ki < M; ki++) {// 固定k和j之后,对所有i项加和
ArrayList<Feature> tmp = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rj : tmp) {
if (Rj.dim == Rij.dim)
ep_sum += P[ki][k] * Rj.error;
}
}
for (Feature Rj : Ri) {// 固定k和i之后,对多有j项加和
eq_sum += Rj.error * Q[k][Rj.dim];
} // 对参数更新
P[i][k] += alpha * (2 * eq_sum - beta * P[i][k]);
Q[k][Rij.dim] += alpha * (2 * ep_sum - beta * Q[k][Rij.dim]);
}
}
}
}
转https://www.cnblogs.com/sirius-swu/p/6932583.html

微信扫二维码,免费学习更多python资源

机器学习-随机梯度下降(Stochastic gradient descent)的更多相关文章
- 随机梯度下降 Stochastic gradient descent
梯度下降法先随机给出参数的一组值,然后更新参数,使每次更新后的结构都能够让损失函数变小,最终达到最小即可. 在梯度下降法中,目标函数其实可以看做是参数的函数,因为给出了样本输入和输出值后,目标函数就只 ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 梯度下降(Gradient Descent)
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 梯度下降(Gradient Descent)相关概念
梯度,直观理解: 梯度: 运算的对像是纯量,运算出来的结果会是向量在一个标量场中, 梯度的计算结果会是"在每个位置都算出一个向量,而这个向量的方向会是在任何一点上从其周围(极接近的周围,学过 ...
- ML:梯度下降(Gradient Descent)
现在我们有了假设函数和评价假设准确性的方法,现在我们需要确定假设函数中的参数了,这就是梯度下降(gradient descent)的用武之地. 梯度下降算法 不断重复以下步骤,直到收敛(repeat ...
- 机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
- python机器学习——随机梯度下降
上一篇我们实现了使用梯度下降法的自适应线性神经元,这个方法会使用所有的训练样本来对权重向量进行更新,也可以称之为批量梯度下降(batch gradient descent).假设现在我们数据集中拥有大 ...
- 多变量线性回归时使用梯度下降(Gradient Descent)求最小值的注意事项
梯度下降是回归问题中求cost function最小值的有效方法,对大数据量的训练集而言,其效果要 好于非迭代的normal equation方法. 在将其用于多变量回归时,有两个问题要注意,否则会导 ...
随机推荐
- Qt QLineEdit
//lineEdit显示文字 QLineEdit *lineEdit = new QLineEdit(widget); lineEdit->setObjectName(QString()); l ...
- git 回退版本
回滚到指定的版本 git reset --hard e377f60e28c8b84158 强制提交 git push -f origin master
- Snowflake Snow Snowflakes POJ - 3349 Hash
题意:一个雪花有六个角 给出N个雪花 判断有没有相同的(可以随意旋转) 参考:https://blog.csdn.net/alongela/article/details/8245005 注意:参考 ...
- BZOJ5210 最大连通子块和 【树链剖分】【堆】【动态DP】
题目分析: 解决了上次提到的<切树游戏>后,这道题就是一道模板题. 注意我们需要用堆维护子重链的最大值.这样不会使得复杂度变坏,因为每个重链我们只考虑一个点. 时间复杂度$O(nlog^2 ...
- 洛谷P1119灾后重建
题目 做一个替我们首先要明确一下数据范围,n<=200,说明n^3的算法是可以过得,而且这个题很明显是一个图论题, 所以我们很容易想到这个题可以用folyd, 但是我在做这个题的时候因为没有深刻 ...
- 洛谷P3602 Koishi Loves Segments(贪心,multiset)
洛谷题目传送门 贪心小水题. 把线段按左端点从小到大排序,限制点也是从小到大排序,然后一起扫一遍. 对于每一个限制点实时维护覆盖它的所有线段,如果超过限制,则贪心地把右端点最大的线段永远删去,不计入答 ...
- 多项式细节梳理&模板(多项式)
基础 很久以前的多项式总结 现在的码风又变了... FFT和NTT的板子 typedef complex<double> C; const double PI=acos(-1); void ...
- HAOI2016 简要题解
「HAOI2016」食物链 题意 现在给你 \(n\) 个物种和 \(m\) 条能量流动关系,求其中的食物链条数. \(1 \leq n \leq 100000, 0 \leq m \leq 2000 ...
- centos7安装sonarqube6.7 代码质量管理平台
应用介绍:SonarQube是一个用于代码质量管理的开源平台,用于管理源代码的质量通过插件形式: 可以支持包括java,C#,C/C++,PL/SQL,Cobol,JavaScrip,Groov ...
- bootstrap 栅栏系统
媒体查询 /* 超小屏幕(手机,小于 768px) */ /* 没有任何媒体查询相关的代码,因为这在 Bootstrap 中是默认的(还记得 Bootstrap 是移动设备优先的吗?) */ /* 小 ...