【爬虫】python requests模拟登录知乎
需求:模拟登录知乎,因为知乎首页需要登录才可以查看,所以想爬知乎上的内容首先需要登录,那么问题来了,怎么用python进行模拟登录以及会遇到哪些问题?
前期准备:
环境:ubuntu,python2.7
需要的包:requests包、正则表达式包
安装requests:pip install requests,关于requests的介绍可以看官方介绍:http://cn.python-requests.org/zh_CN/latest/user/quickstart.html , 以及 http://cuiqingcai.com/2556.html 讲的也很好,简单明了
requests包其实是代替了urllib2,并且提供了大量简洁好用的方法调用。
注意:通过Chrome Devtool可以看到知乎登录的URL是:https//www.zhihu.com/login/email,使用邮箱进行登录。
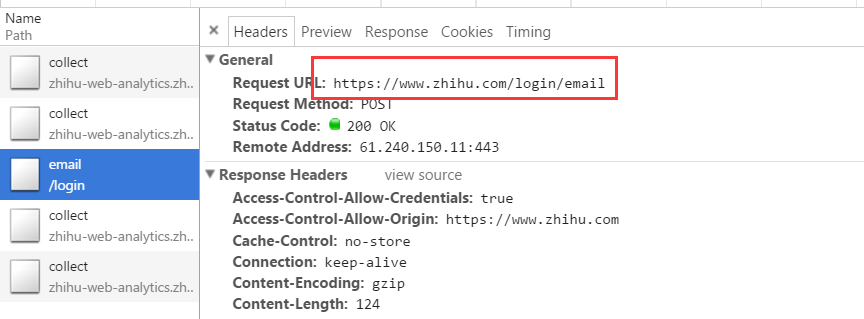
登录的方式为POST,需要的参数有四个分别是:_xsrf、password、remember_me和email,除了第一个都很好理解,那么第一个参数是什么?
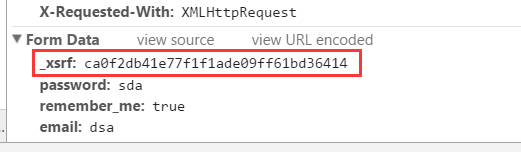
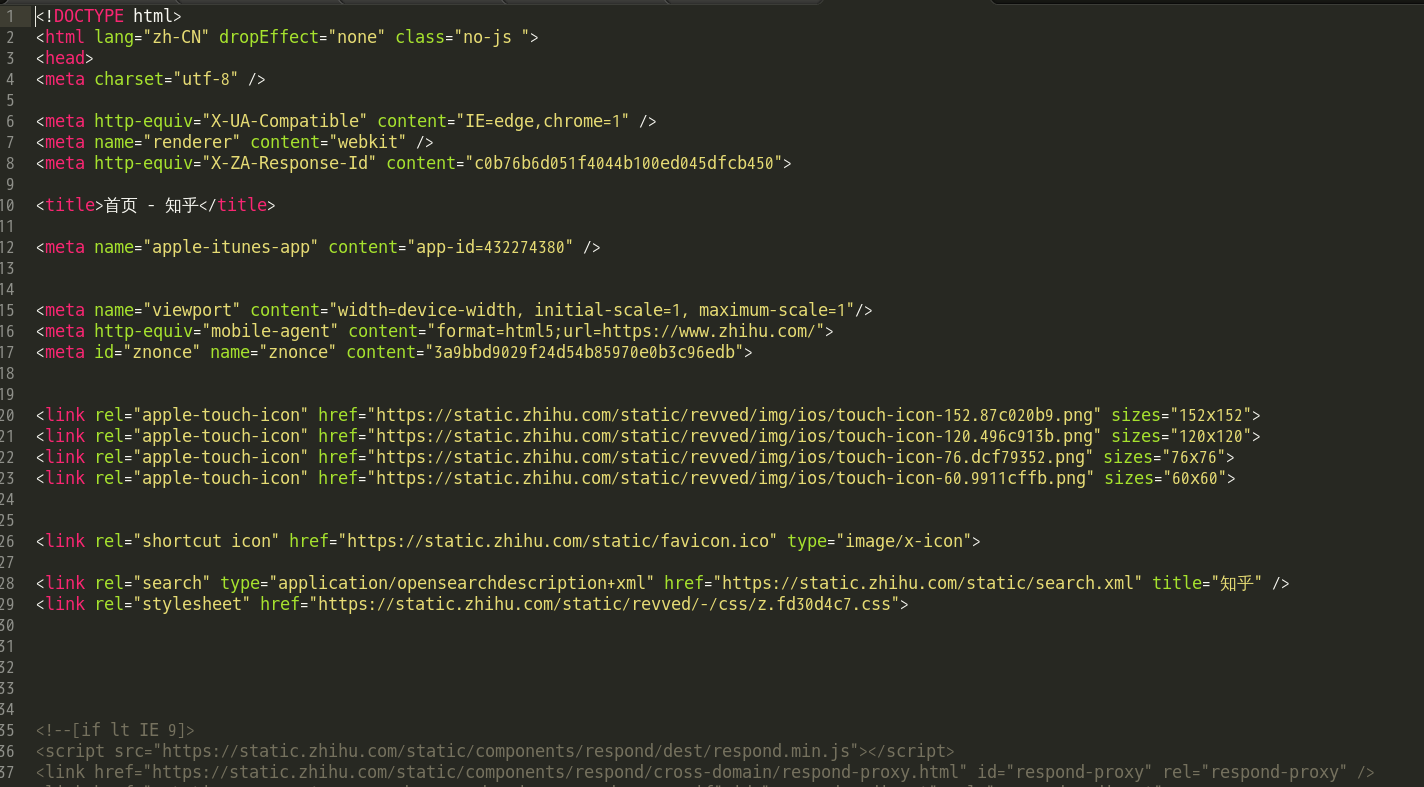
XSRF为跨站请求伪造(Cross-site request forgery),通过搜集资料,在大神的博客里找到有相应资料,http://cuiqingcai.com/2076.html ,说的也很清楚,有兴趣可以查看。这个参数目的就是为了防范XSRF攻击而设置的一个hash值,每次访问主页都会生成这样一个唯一的字符串。那么怎么获取这个参数的值,经过对知乎首页(https://www.zhihu.com)的代码查看可以看到有一个隐藏的标签:

那么就好解决了,直接在爬下来的网页内容中用正则表达式去匹配就OK了。
代码:
import requests
import re def getContent(url):
#使用requests.get获取知乎首页的内容
r = requests.get(url)
#request.get().content是爬到的网页的全部内容
return r.content
#获取_xsrf标签的值
def getXSRF(url):
#获取知乎首页的内容
content = getContent(url)
#正则表达式的匹配模式
pattern = re.compile('.*?<input type="hidden" name="_xsrf" value="(.*?)"/>.*?')
#re.findall查找所有匹配的字符串
match = re.findall(pattern, content)
xsrf = match[0]
#返回_xsrf的值
return xsrf #登录的主方法
def login(baseurl,email,password):
#post需要的表单数据,类型为字典
login_data = {
'_xsrf': getXSRF(baseurl),
'password': password,
'remember_me': 'true',
'email': email,
}
#设置头信息
headers_base = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4,zh-TW;q=0.2',
'Connection': 'keep-alive',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.130 Safari/537.36',
'Referer': 'http://www.zhihu.com/',
}
#使用seesion登录,这样的好处是可以在接下来的访问中可以保留登录信息
session = requests.session()
#登录的URL
baseurl += "/login/email"
#requests 的session登录,以post方式,参数分别为url、headers、data
content = session.post(baseurl, headers = headers_base, data = login_data)
#成功登录后输出为 {"r":0,
#"msg": "\u767b\u9646\u6210\u529f"
#}
print content.text
#再次使用session以get去访问知乎首页,一定要设置verify = False,否则会访问失败
s = session.get("http://www.zhihu.com", verify = False)
print s.text.encode('utf-8')
#把爬下来的知乎首页写到文本中
f = open('zhihu.txt', 'w')
f.write(s.text.encode('utf-8'))
url = "http://www.zhihu.com"
#进行登录,将星号替换成你的知乎登录邮箱和密码即可
login(url,"******@***.com","************")
最后,就成功把知乎首页的内容抓取下来了!下一步可以进行分析和筛选了。
【爬虫】python requests模拟登录知乎的更多相关文章
- Python requests模拟登录
Python requests模拟登录 #!/usr/bin/env python # encoding: UTF-8 import json import requests # 跟urllib,ur ...
- Python爬虫初学(三)—— 模拟登录知乎
模拟登录知乎 这几天在研究模拟登录, 以知乎 - 与世界分享你的知识.经验和见解为例.实现过程遇到不少疑问,借鉴了知乎xchaoinfo的代码,万分感激! 知乎登录分为邮箱登录和手机登录两种方式,通过 ...
- Python爬虫入门(基础实战)—— 模拟登录知乎
模拟登录知乎 这几天在研究模拟登录, 以知乎 - 与世界分享你的知识.经验和见解为例.实现过程遇到不少疑问,借鉴了知乎xchaoinfo的代码,万分感激! 知乎登录分为邮箱登录和手机登录两种方式,通过 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 2020.10.20 利用POST请求模拟登录知乎
前两天学习了Python的requests模块的相关内容,对于用GET和PSOT请求访问网页以抓取需要的内容有了初步的了解,想要再从一些复杂的网站积累些经验.最开始我采用最简单的get(url)方法想 ...
- requests_模拟登录知乎
如何登录知乎? 首先要分析,进行知乎验证的时候,知乎服务器需要我们提交什么数据,提交的地址.先进行几次登录尝试,通过浏览器中network中查看数据流得知,模拟登录知乎需要提供5个数据,分别是_xsr ...
- 用python实现模拟登录人人网
用python实现模拟登录人人网 字数4068 阅读1762 评论19 喜欢46 我决定从头说起.懂的人可以快速略过前面理论看最后几张图. web基础知识 从OSI参考模型(从低到高:物理层,数据链路 ...
- 利用scrapy模拟登录知乎
闲来无事,写一个模拟登录知乎的小demo. 分析网页发现:登录需要的手机号,密码,_xsrf参数,验证码 实现思路: 1.获取验证码 2.获取_xsrf 参数 3.携带参数,请求登录 验证码url : ...
- 使用Python+Selenium模拟登录QQ空间
使用Python+Selenium模拟登录QQ空间爬QQ空间之类的页面时大多需要进行登录,研究QQ登录规则的话,得分析大量Javascript的加密解密,这绝对能掉好几斤头发.而现在有了seleniu ...
随机推荐
- Item 6 消除过期的对象引用
过期对象引用没有清理掉,会导致内存泄漏.对于没有用到的对象引用,可以置空,这是一种做法.而最好的做法是,把保存对象引用的变量清理掉,多用局部变量. 什么是内存泄漏? 在Java中,对象的内存空间回 ...
- 【BZOJ4819】【SDOI2017】新生舞会 [费用流][分数规划]
新生舞会 Time Limit: 10 Sec Memory Limit: 128 MB[Submit][Status][Discuss] Description 学校组织了一次新生舞会,Cathy ...
- 网络知识===wireshark抓包,三次握手分析
TCP需要三次握手建立连接: 网上的三次握手讲解的太复杂抽象,尝试着使用wireshark抓包分析,得到如下数据: 整个过程分析如下: step1 client给server发送:[SYN] Seq ...
- rhel-server srpms iso
http://ftp.redhat.com/pub/redhat/linux/enterprise/7Server/en/ ftp://ftp.pslib.cz/pub/linux/redhat-cz ...
- x64dbg
https://x64dbg.com/ https://github.com/x64dbg/x64dbg https://sourceforge.net/projects/x64dbg/files/s ...
- 流程控制--if条件
/* if ....else .... */ [root@localhost test1]# vim .py //ADD #!/usr/bin/python >: print 'hello py ...
- mongodb实现批量修改数据
var rds = db.REGIPATIENTREC.find({mzh:{$lt:"0"},usrOrg:"石景山中西医结合医院"}); var show ...
- 全国省市区数据SQL - 省市区
转载:https://www.cnblogs.com/flywind/p/6036801.html
- LeetCode218. The Skyline Problem
https://leetcode.com/problems/the-skyline-problem/description/ A city's skyline is the outer contour ...
- Restful Framework (二)
目录 一.认证 二.权限 三.限制访问频率 四.总结 一.认证(补充的一个点) 回到顶部 认证请求头 #!/usr/bin/env python # -*- coding:utf-8 -*- from ...