【UV统计】海量数据统计的前世今生
背景
在互联网公司中,每个项目都需要数据统计、分析,便于项目组利用详细数据研究项目的整体情况,进行下一步的调整。在数据统计中,UV统计是最常见的,也是最普遍的。有的场景要求实时性很高,有点场景要求准确性很高,有的场景比较在意计算过程中的内存。不同的场景使用不同的算法,下面我们从0到1简单介绍下UV统计领域。
什么是UV统计
假设我们的场景是商家这边上架一系列水果,然后需要统计出一共上架几种水果。具体如下所示:
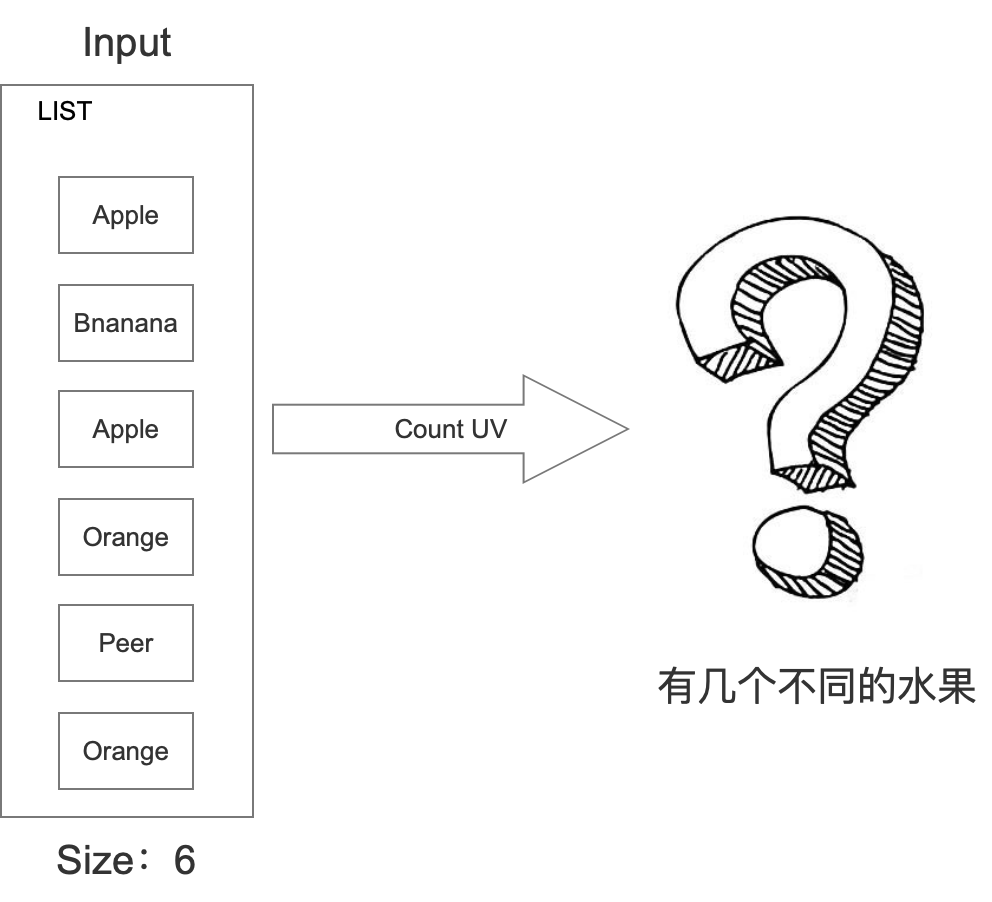
针对这个问题,我们想到的最简单的方式就是利用STL中的set处理。
SET
上架一个水果的时候,也同时在set中插入。最后需要统计的时候,直接计算set中一共有几个水果即可。具体如下所示:
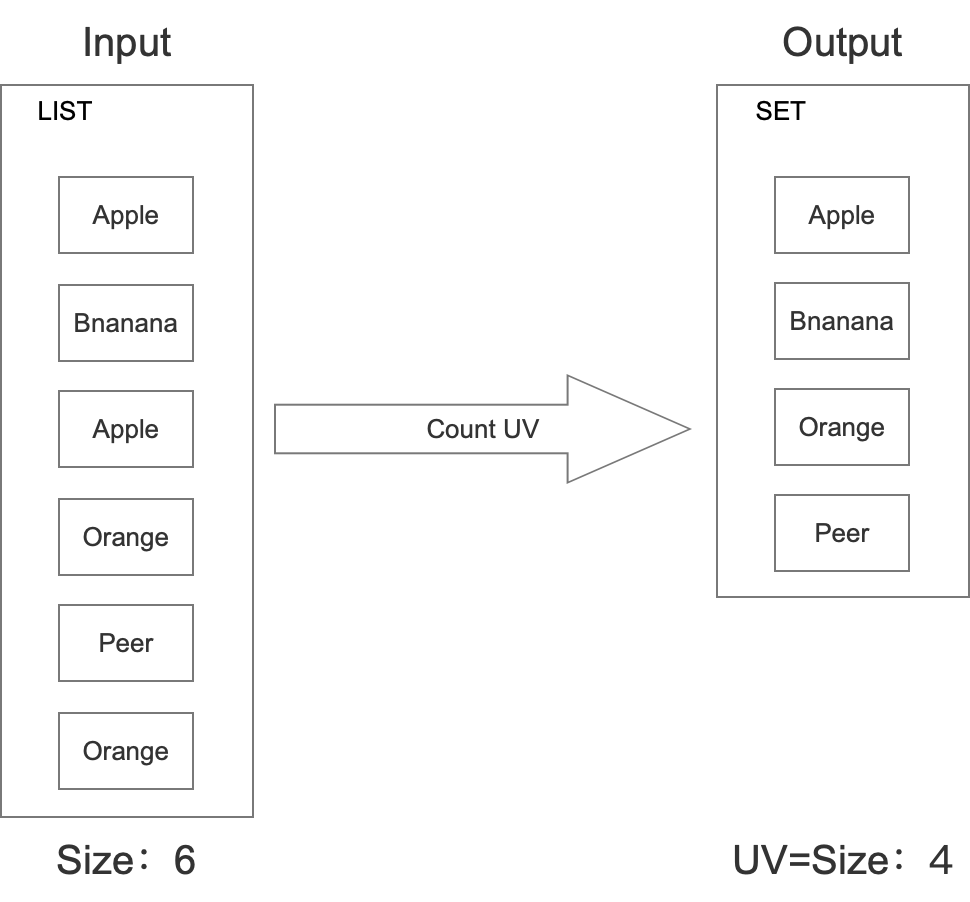
这种方式准确率是绝对准确的,但是这种方式耗费的内存是很大的。
假设每个水果需要 K 字节,那么如果有 M 个水果,一共需要 K * M 字节。那么我们能不能缩小这里的内存呢?
稍微损失一点准确率换取内存?具体见下面HashMap的方式
HASHMAP
这种算法在上架一个水果的时候,只需要在特定的位置置1即可,而不需要存储这个位置上究竟是何种水果。然后在统计的时候,只需要统计hashmap里面有多少个1即可。具体如下所示:
具体如下所示:
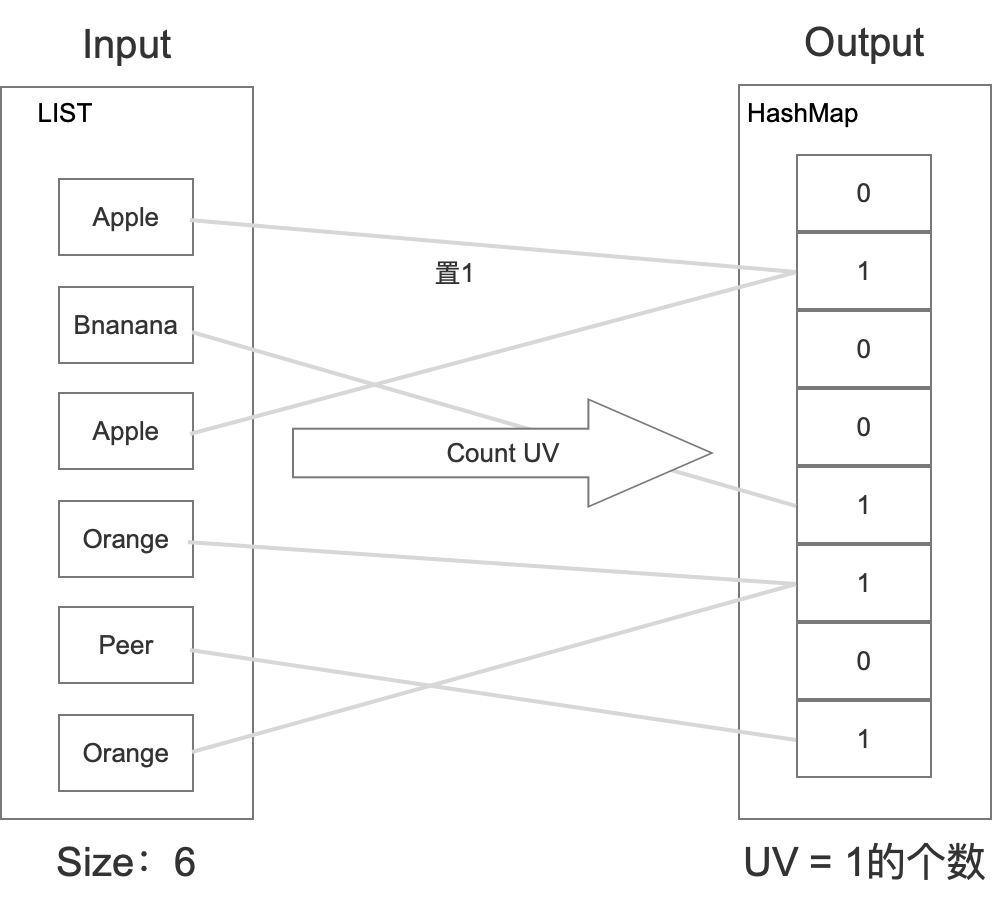
那么如果有M个水果,这里其实只需要 M / 8 字节,相比set的方式内存直接缩小到1/8。当然Hash肯定会有冲突的,所以这里肯定有一定准确率的损失。
但是如果涉及到海量数据的UV统计,这里的内存还是很大的。
能否用上统计学进一步缩小内存呢?具体见下面的Linear Count的方式。
Linear Count
这种算法在上架一个水果的时候,完全跟hashmap一致,在相应位置置1。
然后在统计的时候,利用统计学的方式,根据hashmap中零的个数给出一个估算值。具体如下所示:
假设M为哈希桶长度,那么每次上架水果,每个桶被选中的概率为:
$$\frac{1}{M}$$
然后在上架N个元素后,某个桶为0的概率为:
$$(1-\frac{1}{M}) ^N$$
所以在上架n个元素后,哈希桶中零的个数期望为:
$$ZeroNum=\sum_{i=1}^M (1-\frac{1}{M}) ^N = M (1-\frac{1}{M}) ^N= M ((1+\frac{1}{-M}){-M}){-\frac{N}{M}}) \approx Me^{- \frac{N}{M}}$$
所以最终:
$$
N = UV = -M ln(\frac{ZeroNum}{M})
$$
所以Linear Count算法中,只需统计下hashmap中零的个数,然后代入上式即可。
这种算法在N很小的时候,准确率是很高的,但是N很大的时候,它的准确率急剧下降。
针对海量数据的情况,LogLog Count的算法更加鲁棒
LogLog Count
这种算法跟上面几种都不同,上架水果的时候,在相应桶里面记录的是二进制数后面最长的连续零个数。然后统计的时候,利用统计学的方式,根据存储中最长连续后缀零个数,得出一个估计值。具体如下所示:
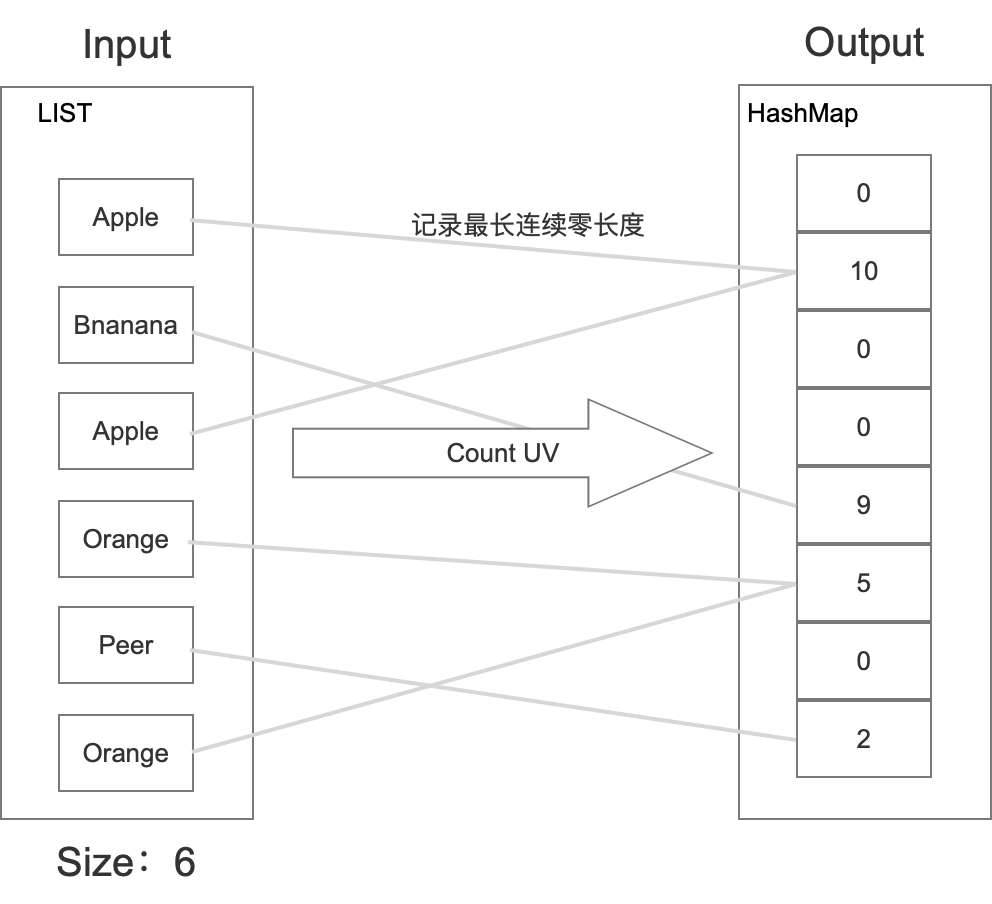
它的原理如下:


这里如果只使用一个桶来估计的话,它的误差是很大,需要用分桶平均的方式来减少它的误差。
分桶平均
既然这里利用了分桶来减少误差,那么这里统计的时候就必须合起来,这里有4种方式:
- 算术平均:$$UV=\frac{\sum_{j=1}^mUV_j} { m}$$
- 几何平均:$$UV=\sqrt[m]{UV_1...UVm}$$
- 调和平均:$$UV=\frac{m}{\sum_{j=1}mUV_j{-1}}$$
- 中位数:$$UV=mediam {UV_1,...,UV_m}$$
LogLog Count利用的是算术平均的方式,所以最终估计值为:
$$UV=2{\frac{\sum_{j=1}m{UV_j}}{m}}$$
这种算法对于基数大的情况下准确率挺高的,但是基数小的情况下准确率很低。
HyperLogLog Count
这种算法跟LogLog Count 类似,有个区别点就是它在求均值的时候利用了调和平均数,而不是算术平均数。这里最终估计值为:
$$UV=mm(\sum_{j=1}m{2{-M_j}})^{-1}$$
然后它还引入了分段误差修正。
误差修正

具体可以看我github上的代码:HyperLogLog
总结
| 准确率 | 内存 | 耗时 | |
|---|---|---|---|
| Set | 绝对准确 | K * M | O(Mlog(M)) |
| HashMap | 很高 | M/8 | O(M) |
| Linear Count | 基数小高,基数大低 | M/8 | O(M/8) |
| LogLog Count | 基数小低,基数大高 | ||
| HyperLogLog Count | 高 |
【UV统计】海量数据统计的前世今生的更多相关文章
- Redis 实战篇:巧用Bitmap 实现亿级海量数据统计
在移动应用的业务场景中,我们需要保存这样的信息:一个 key 关联了一个数据集合. 常见的场景如下: 给一个 userId ,判断用户登陆状态: 显示用户某个月的签到次数和首次签到时间: 两亿用户最近 ...
- Hexo博客添加SEO-评论系统-阅读统计-站长统计
原文地址:→传送门 写在前面 在五月出捣腾了一把个人博客,但是刚开始只做了一些基础设置,套路也没摸清,基础安装篇请看hexo从零开始到搭建完整,里面讲到了基础工具的安装及blog项目的文件夹含义,以及 ...
- 智能ERP收银统计-优惠统计计算规则
1.报表统计->收银统计->优惠统计规则 第三方平台优惠:(堂食订单:支付宝口碑券优惠)+(外卖订单:商家承担优惠) 自平台优惠:(堂食订单:商家后台优 ...
- 使用redis做pv、uv、click统计
redis实时统计 设计思路: 1. 前端smarty插件(smarty_function_murl),将网站所有的连接生成一个urlid,后端根据获取的参数将需要的数据存入redis. 2.后端插件 ...
- 43、内置函数及每日uv、销售额统计案例
一.spark1.5内置函数 在Spark 1.5.x版本,增加了一系列内置函数到DataFrame API中,并且实现了code-generation的优化.与普通的函数不同,DataFrame的函 ...
- 怎么区分PV、IV、UV以及网站统计名词解释(pv、曝光、点击)
PV(Page View)访问量,即页面访问量,每打开一次页面PV计数+1,刷新页面也是. IV(Internet Protocol)访问量指独立IP访问数,计算是以一个独立的IP在一个计算时段内访问 ...
- 海量数据统计topK
有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M.返回频数最高的100个词. 思路: 把这1G的数据一次性全部读入内存是不可能了,可以每次读一行,然后将该词存到 ...
- Oracle11g 统计信息——统计信息自动收集任务
参考文献: Oracle11g 统计信息(一)-----统计信息自动收集任务 背景: 在使用cacti监控oracle数据库IO的时候发现每天晚上10点钟的时候oracle数据库读写明显增加,如下图所 ...
- MySQL查询统计,统计唯一值并分组
做个笔记 SQLyog客户端访问MySQL服务器 统计数据:次数总数, 次数成功率,对象(obj)总数,对象(obj)成功率 要求:按时间排序和分组 sql语句如下: SELECT a.date AS ...
随机推荐
- [PHP安全特性学习]strcmp()函数安全漏洞
简介 PHP函数的安全特性-strcmp() 函数 php-strcmp()函数 PHP strcmp() 函数 strcmp() 函数比较两个字符串. 注释:strcmp() 函数是二进制安全的,且 ...
- kali 系列学习08-安卓逆向
可以轻松把安卓apk的源码逆向出来,逆向有什么用,比如手机apk木马,可以用于追踪黑客,详见 https://cloud.tencent.com/developer/news/179336 用2个工 ...
- jq判断input 复选框有没有选
选中了返回true ,没选中返回false$("input[type='checkbox']").is(':checked'):
- 这个厉害了,ssm框架整合全过程,建议收藏起来好好看看
1.0 环境要求 IDEA MySQL 5.7.19 Tomcat 9 Maven 3.6 1.1 数据库 创建书籍数据库表,包括书籍编号,书籍名称,书籍数量以及书籍描述. CREATE DATABA ...
- 如何使用ABBYY FineReader 识别竖排或反转文本?
ABBYY FineReader 15(Windows系统)OCR文字识别软件拥有强大的OCR识别功能,能够对这些竖排排版的文档进行准确的识别,另外对于一些具有反转颜色(白色字符和黑暗背景的图像)的文 ...
- GIF图保存下来不会动?用Folx的浏览器捕获下载功能试试!
表情包大多是GIF格式的动图,有时候使用浏览器的另存为保存完发现并不能动态播放,怎么办呢?试试Folx提供的浏览器捕获下载功能,就能将各种格式的图片,包括GIF动图的下载链接捕获下来,供进一步下载使用 ...
- Matlab 补充知识
1:disp函数和fprintf函数类似 disp(a) 自动输出a变量的值 disp('dadad') 输出一个字符串 Disp(['a','b','ccc']) 三个字符串连在一起 2:matla ...
- Java基础教程——网络基础知识
参考阅读[中国互联网发展史]:https://zhuanlan.zhihu.com/p/61602252 协议 计算机网络中的通信必须有一些约定,这些约定称为"通信协议". 通信协 ...
- java实验作业1
1 //1已知圆的半径为10,求其周长及面积 2 package calsswork3; 3 4 public class test3_1 { 5 //求周长 6 public static doub ...
- 微信小程序 下拉刷新
<scroll-view class='scroll-view-container' scroll-y="true" bindscrolltolower='scrollToL ...