python 爬取全本免费小说网的小说
这几天朋友说想看电子书,但是只能在网上看,不能下载到本地后看,问我有啥办法?我找了好几个小说网址看了下,你只能直接在网上看,要下载txt要冲钱买会员,而且还不能在浏览器上直接复制粘贴。之后我就想到python的爬虫不就可以爬取后下载吗?
码源下载:
https://github.com/feiquan123/GetEBook/
思路:
首先,选择网址:http://www.yznnw.com/files/article/html/1/1129/index.html 这个是全本免费小说网上《龙血战神》的网址:

F12,分析网页元素,可以看到,在此页的 .zjlist4 li a 下存放了所有章节的URL,首先我们要获取这些url放在一个数组里。然后循环遍历下载
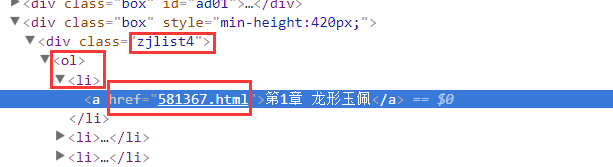
有了这些网址后开始分析具体的每一章:
书名:

章节名:

内容:

下一章:

有了这些信息我们就可以开始爬取了(其实这里可以不爬取下一章的,主要我之前的思路是:下载小说的第一章后,返回小说的下一章,之后不断递归直到最后一页,这么做后下载速度慢,不能并发,还有就是一直递归占用资源大,一直请求服务器会断开连接,导致失败)
所以我换成了这种思路:就是先获取所有的章节的网页连接,再用线程(你也可以用进程)开始下载,果然速度上升了好多,
但是,仔细分析后发现,其实有些章节是作者的感言啥的,这些是不用下载的,而真正的章节的标题一定含有:****章*****,所以要用正则排除掉(这个要具体分析,不一定每个作者的感言标题都是这样的,不过直接使用此程序也可以,这样也没啥)


代码如下:
#coding:utf-
import urllib
import urllib.request
import multiprocessing
from bs4 import BeautifulSoup
import re
import os
import time def get_pages(url):
soup=""
try:
# 创建请求日志文件夹
if 'Log' not in os.listdir('.'):
os.mkdir(r".\Log") # 请求当前章节页面 params为请求参数
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
content = response.read()
data = content.decode('gbk')
# soup转换
soup = BeautifulSoup(data, "html.parser") except Exception as e:
print(url+" 请求错误\n")
with open(r".\Log\req_error.txt",'a',encoding='utf-8') as f:
f.write(url+" 请求错误\n")
f.close()
return soup # 通过章节的url下载内容,并返回下一页的url
def get_ChartTxt(url,title,num):
soup=get_pages(url) # 获取章节名称
subtitle = soup.select('#htmltimu')[].text
# 判断是否有感言
if re.search(r'.*?章', subtitle) is None:
return
# 获取章节文本
content = soup.select('#htmlContent')[].text
# 按照指定格式替换章节内容,运用正则表达式
content = re.sub(r'\(.*?\)', '', content)
content = re.sub(r'\r\n', '', content)
content = re.sub(r'\n+', '\n', content)
content = re.sub(r'<.*?>+', '', content) # 单独写入这一章
try:
with open(r'.\%s\%s %s.txt' % (title, num,subtitle), 'w', encoding='utf-8') as f:
f.write(subtitle + content)
f.close()
print(num,subtitle, '下载成功') except Exception as e:
print(subtitle, '下载失败',url)
errorPath='.\Error\%s'%(title)
# 创建错误文件夹
try :
os.makedirs(errorPath)
except Exception as e:
pass
#写入错误文件
with open("%s\error_url.txt"%(errorPath),'a',encoding='utf-8') as f:
f.write(subtitle+"下载失败 "+url+'\n')
f.close()
return # 通过首页获得该小说的所有章节链接后下载这本书
def thread_getOneBook(indexUrl):
soup = get_pages(indexUrl)
# 获取书名
title = soup.select('#htmldhshuming')[].text
# 根据书名创建文件夹
if title not in os.listdir('.'):
os.mkdir(r".\%s" % (title))
print(title, "文件夹创建成功———————————————————") # 加载此进程开始的时间
print('下载 %s 的PID:%s...' % (title, os.getpid()))
start = time.time() # 获取这本书的所有章节
charts_url = []
# 提取出书的每章节不变的url
indexUrl = re.sub(r'index.html', '', indexUrl)
charts = soup.select(".zjlist4 li a")
for i in charts:
# print(j+i.attrs['href'])
charts_url.append(indexUrl + i.attrs['href']) # 创建下载这本书的进程
p = multiprocessing.Pool()
#自己在下载的文件前加上编号,防止有的文章有上,中,下三卷导致有3个第一章
num=
for i in charts_url:
p.apply_async(get_ChartTxt, args=(i,title,num))
num+=
print('等待 %s 所有的章节被加载......' % (title))
p.close()
p.join()
end = time.time()
print('下载 %s 完成,运行时间 %0.2f s.' % (title, (end - start)))
print('开始生成 %s ................' %title )
sort_allCharts(r'.',"%s.txt"%title)
return # 创建下载多本书书的进程
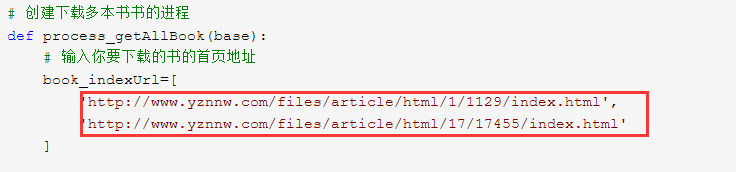
def process_getAllBook(base):
# 输入你要下载的书的首页地址
print('主程序的PID:%s' % os.getpid())
book_indexUrl=[
'http://www.yznnw.com/files/article/html/1/1129/index.html',
'http://www.yznnw.com/files/article/html/29/29931/index.html',
'http://www.yznnw.com/files/article/html/0/868/index.html'
]
print("-------------------开始下载-------------------")
p = []
for i in book_indexUrl:
p.append(multiprocessing.Process(target=thread_getOneBook, args=(i,)))
print("等待所有的主进程加载完成........")
for i in p:
i.start()
for i in p:
i.join()
print("-------------------全部下载完成-------------------") return
#合成一本书
def sort_allCharts(path,filename):
lists=os.listdir(path)
# 对文件排序
# lists=sorted(lists,key=lambda i:int(re.match(r'(\d+)',i).group()))
lists.sort(key=lambda i:int(re.match(r'(\d+)',i).group()))
# 删除旧的书
if os.path.exists(filename):
os.remove(filename)
print('旧的 %s 已经被删除'%filename)
# 创建新书
with open(r'.\%s'%(filename),'a',encoding='utf-8') as f:
for i in lists:
with open(r'%s\%s' % (path, i), 'r', encoding='utf-8') as temp:
f.writelines(temp.readlines())
temp.close()
f.close()
print('新的 %s 已经被创建在当前目录 %s '%(filename,os.path.abspath(filename))) return if __name__=="__main__":
# # 主页
base = 'http://www.yznnw.com'
# 下载指定的书
process_getAllBook(base)
#如果下载完出现卡的话,请单独执行如下命令
# sort_allCharts(r'.\龙血战神',"龙血战神.txt")
如果要下载其他书的话,找到书的首页,添加到如下位置:
找书的首页URL,随便点开一章,删除后面的***.html,后回车,就是这本书的首页URL。

运行结果:




请求URL失败的网页放在,Log\req_error.txt中
爬取失败的章节存放在这本书的目录下的error_url.txt中
之后,你可以使用电子书生成器,生成就好,也可以在跟目录下看到相应的总的小说:
这个是我爬了3本书的结果,爬完后程序卡了,只能结束掉,单独执行最后一条命令了。。。。。。。。
手机端打开,目录也正确


版权 作者:feiquan 出处:http://www.cnblogs.com/feiquan/ 版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 大家写文都不容易,请尊重劳动成果~ 这里谢谢大家啦(*/ω\*)
python 爬取全本免费小说网的小说的更多相关文章
- python 爬取全量百度POI
在网上找了很多关于爬取百度POI的文章,但是对“全量”的做法并没有得到最终的解决方案,自己写了一个,但还是不能实现全量POI抓取,能够达到至少50%的信息抓取.注意:这里所指“全量”是能够达到100% ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python 爬取途虎养车 全系车型 轮胎 保养 数据
Python 爬取途虎养车 全系车型 轮胎 保养 数据 2021.7.27 更新 增加标题.发布时间参数 demo文末自行下载,需要完整数据私聊我 2021.2.19 更新 增加大保养数据 2020. ...
- Python学习-使用Python爬取陈奕迅新歌《我们》网易云热门评论
<后来的我们>上映也有好几天了,一直没有去看,前几天还爆出退票的事件,电影的主题曲由陈奕迅所唱,特地找了主题曲<我们>的MV看了一遍,还是那个感觉.那天偶然间看到Python中 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
随机推荐
- [Swift]LeetCode835. 图像重叠 | Image Overlap
Two images A and B are given, represented as binary, square matrices of the same size. (A binary ma ...
- Java常用工具类练习题
1.请根据控制台输入的特定日期格式拆分日期 如:请输入一个日期(格式如:**月**日****年) 经过处理得到:****年**月**日 提示:使用String的方法indexOf.lastIndexO ...
- 小程序自定义pick(日期加时间组合)
最近小程序有个需求要使用日期加时间的pick组件 翻了小程序文档似乎没有符合的 手写一个 新建组件picker.js: Component({ properties: { disabled: { t ...
- 【git】idea /git bash命令 操作分支
1.需求 因为目前要对项目做一些改动,而项目又即将上线,这些新的改动又不需要一起上线,所以这个时候需要在原有的master分支上重新拉出一个分支进行开发. 2.分支操作 打开git bash工具→切换 ...
- qt 布局
说到qt布局,比起之前用的MFC好了许多,而且qt支持qss,可以更好的美化界面.qt提供了几种常见的布局管理 窗体布局,这对客户端程序来说是一个福音,再也不用操心程序界面放大缩小时界面控件怎么变化, ...
- 带着萌新看springboot源码07
[修改]很长时间没看这个,有点弄混淆了.bean后置处理器(BeanPostProcessor)应该是在bean创建实例并且赋值好了之后,调用初始化方法(相当于xml配置中<bean init= ...
- 前端笔记之JavaScript(十一)event&BOM&鼠标/盒子位置&拖拽/滚轮
一.事件对象event 1.1 preventdefault()和returnValue阻止默认事件 通知浏览器不要执行与事件关联的默认动作. preventdefault() 支持Chrome等高 ...
- MySQL 隔离级别
一.事务特性 1.原子性 事务是一个原子操作单元,事务中包含的所有操作要么都做,要么都不做,没有第三种情况. 2.一致性 事务操作前和操作后都必须满足业务规则约束,比如说A向B转账,转账前和转账后AB ...
- C++STL模板库适配器之stack容器
目录 适配器 一丶适配器简介 二丶栈(stack)用法 1.栈的常用方法 适配器 一丶适配器简介 Stl中的适配器,有栈 (stack) 队列 queue 根priority_queue 适配器都是包 ...
- 如何用sysbench做好IO性能测试
sysbench 是一个非常经典的综合性能测试工具,通常都用它来做数据库的性能压测,但也可以用来做CPU,IO的性能测试.而对于IO测试,不是很推荐sysbench,倒不是说它有错误,工具本身没有任何 ...