python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中
我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后迎刃而解了。这个程序非常的简单,程序的大概就是先获取网页的源代码,然后在网页的源代码中提取每个章节的url,获取之后,在通过每个url去获取文章的内容,在进行提取内容,然后就是保存到本地,一TXT的文件类型保存。
大概是这样
1:获取网页源代码
2:获取每章的url
3:获取每章的内容
4:下载保存文件中
1、首先就是先安装第三方库requests,这个库,打开cmd,输入pip install requests回车就可以了,等待安装。然后测试
2、然后就可以编写程序了,首先获取网页源代码,也可以在浏览器查看和这个进行对比。
s = requests.Session()
url = 'https://www.xxbiquge.com/2_2634/' # 这里可以进行更改你想要爬取小说的url
html = s.get(url)
html.encoding = 'utf-8'
print(html.text) #获取网页源代码
运行后显示网页源代码

按F12查看
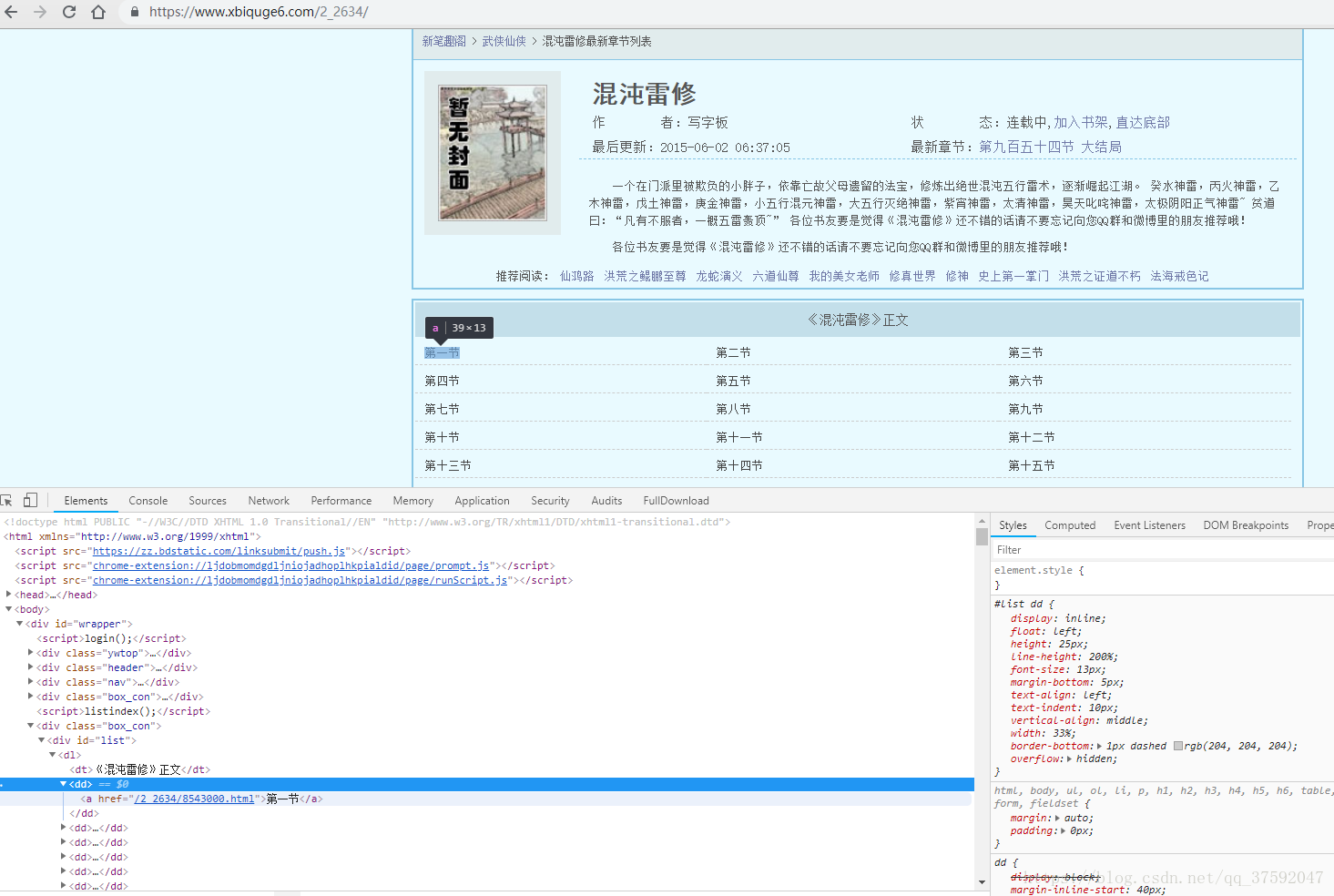
这样就说明这是对的
3、然后进行获取网页源代码中的每章url,进行提取
caption_title_1 = re.findall(r'<a href="(/2_2634/.*?\.html)">.*?</a>',html.text)
print(caption_title_1)

由于过多,就剪切了这些,看到这些URL,你可能想问为什么不是完整的,这是因为网页中的本来就不完整,需要进行拼凑得到完整的url
for i in caption_title_1:
caption_title_1 = 'https://www.xxbiquge.com'+i
这样就完成了,就可以得到完整的了
4、下面就是获取章节名,和章节内容
#获取章节名
name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0] # 提取章节名
print(name) file_name.write(name)
file_name.write('\n') # 获取章节内容
chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0] #提取章节内容
chapters = chapters.replace(' ', '') # 后面的是进行数据清洗
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
5、转换字符串和保存文件
# 转换字符串
s = str(chapters)
s_replace = s.replace('<br/>',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)
fiction = pattern.sub(' ',s_replace)
file_name.write(fiction)
file_name.write('\n')
6、完整的代码
import requests
import re s = requests.Session()
url = 'https://www.xxbiquge.com/2_2634/'
html = s.get(url)
html.encoding = 'utf-8' # 获取章节
caption_title_1 = re.findall(r'<a href="(/2_2634/.*?\.html)">.*?</a>',html.text) # 写文件
path = r'C:\Users\Administrator\PycharmProjects\untitled\title.txt' # 这是我存放的位置,你可以进行更改
file_name = open(path,'a',encoding='utf-8') # 循环下载每一张
for i in caption_title_1:
caption_title_1 = 'https://www.xxbiquge.com'+i
# 网页源代码
s1 = requests.Session()
r1 = s1.get(caption_title_1)
r1.encoding = 'utf-8' # 获取章节名
name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0]
print(name) file_name.write(name)
file_name.write('\n') # 获取章节内容
chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0]
chapters = chapters.replace(' ', '')
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
# 转换字符串
s = str(chapters)
s_replace = s.replace('<br/>',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)
fiction = pattern.sub(' ',s_replace)
file_name.write(fiction)
file_name.write('\n') file_name.close()
7、修改你想要爬取小说url后再进行运行,如果出现错误,可能是存放位置出错,可以再保存文件地址修改为你要存放的地址,然后就结束了
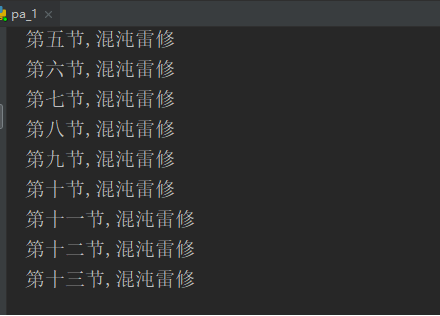

就是爬取的完整的小说,是不是很简单,,希望能对你所帮助
最后送上一点小福利吧
链接:https://pan.baidu.com/s/1sMxwTn7P2lhvzvWRwBjFrQ
提取码:kt2v
链接容易被举报过期,如果失效了就在这里领取吧
python入门学习之Python爬取最新笔趣阁小说的更多相关文章
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url.标题以及摘要. 实例环境:pytho ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- Python入门:全站url爬取
<p>作为一个安全测试人员,面对一个大型网站的时候,手工测试很有可能测试不全,这时候就非常需要一个通用型的网站扫描器.当然能直接扫出漏洞的工具也有很多,但这样你只能算是一个工具使用者,对于 ...
- Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 1. 首先导入相关的模块 import os import requests from ...
- scrapycrawl 爬取笔趣阁小说
前言 第一次发到博客上..不太会排版见谅 最近在看一些爬虫教学的视频,有感而发,大学的时候看盗版小说网站觉得很能赚钱,心想自己也要搞个,正好想爬点小说能不能试试做个网站(网站搭建啥的都不会...) 站 ...
- HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言 首先先介绍一下Jsoup:(摘自官网) jsoup is a Java library for working with real-world HTML. It provides a very ...
随机推荐
- [讲解]prim算法<最小生成树>
最小生成树的方法一般比较常用的就是kruskal和prim算法 一个是按边从小到大加,一个是按点从小到大加,两个方法都是比较常用的,都不是很难... kruskal算法在本文里我就不讲了,本文的重点是 ...
- 2.1.JVM的垃圾回收机制,判断对象是否死亡
因为热爱,所以坚持. 文章下方有本文参考电子书和视频的下载地址哦~ 这节我们主要讲垃圾收集的一些基本概念,先了解垃圾收集是什么.然后触发条件是什么.最后虚拟机如何判断对象是否死亡. 一.前言 我们 ...
- Django-CBV&FBV
django中请求处理方式有2种:FBV 和 CBV 一.FBV FBV(function base views) 就是在视图里使用函数处理请求. urls.py from django.conf.u ...
- jvm的类加载机制总结
类的加载机制分为如下三个阶段:加载,连接,初始化.其中连接又分为三个小阶段:验证,准备,解析. 加载阶段 将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后再堆内创 ...
- lly的数列询问(最小生成树 + 思维)
lly的数列询问 Description 这个问题很简单,lly lly lly给你一些提示,让你试着确定长度为n n n的数列A [1] A [2] ... A [n]的值,但是他想尽一切办法为大家 ...
- Gin框架系列03:换个姿势理解中间件
什么是中间件 中间件,英译middleware,顾名思义,放在中间的物件,那么放在谁中间呢?本来,客户端可以直接请求到服务端接口. 现在,中间件横插一脚,它能在请求到达接口之前拦截请求,做一些特殊处理 ...
- linux系统部署安装过程
1. 虚拟环境安装 1.新建虚拟机 2.虚拟机设置 2.系统历程 1.进入系统引导界面进行配置 引导项说明: 1.安装centos 系统 ...
- 自定义yum仓库
自定义yum仓库 案例4:自定义yum软件仓库 4.1问题 本例要求在CentOS真机上利用RHEL7的光盘镜像文件准 ...
- C++ stringstream(强制类型转换)
#include <iostream>#include <string>#include <sstream>using namespace std;int main ...
- openpyxl 模块 读写Excel
import openpyxl #写到execl中def write_execl(): book=openpyxl.Workbook() sheet=book.active #获取默认sheet # ...