scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表:
scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy01.html
scrapy爬虫学习系列二:scrapy简单爬虫样例学习: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy02.html
scrapy爬虫学习系列三:scrapy部署到scrapyhub上: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_004_scrapyhub.html
scrapy爬虫学习系列四:portia的学习入门: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_010_scrapy04.html
scrapy爬虫学习系列五:图片的抓取和下载: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_011_scrapy05.html
scrapy爬虫学习系列六:官方文档的学习: https://github.com/zhaojiedi1992/My_Study_Scrapy
1.scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
官方简介地址:https://docs.scrapy.org/en/latest/topics/architecture.html
中文的简介地址:http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html 这个版本才旧了,不建议看了(英文的是1.4的, 这个是0.24)
1.1 scrapy基础架构
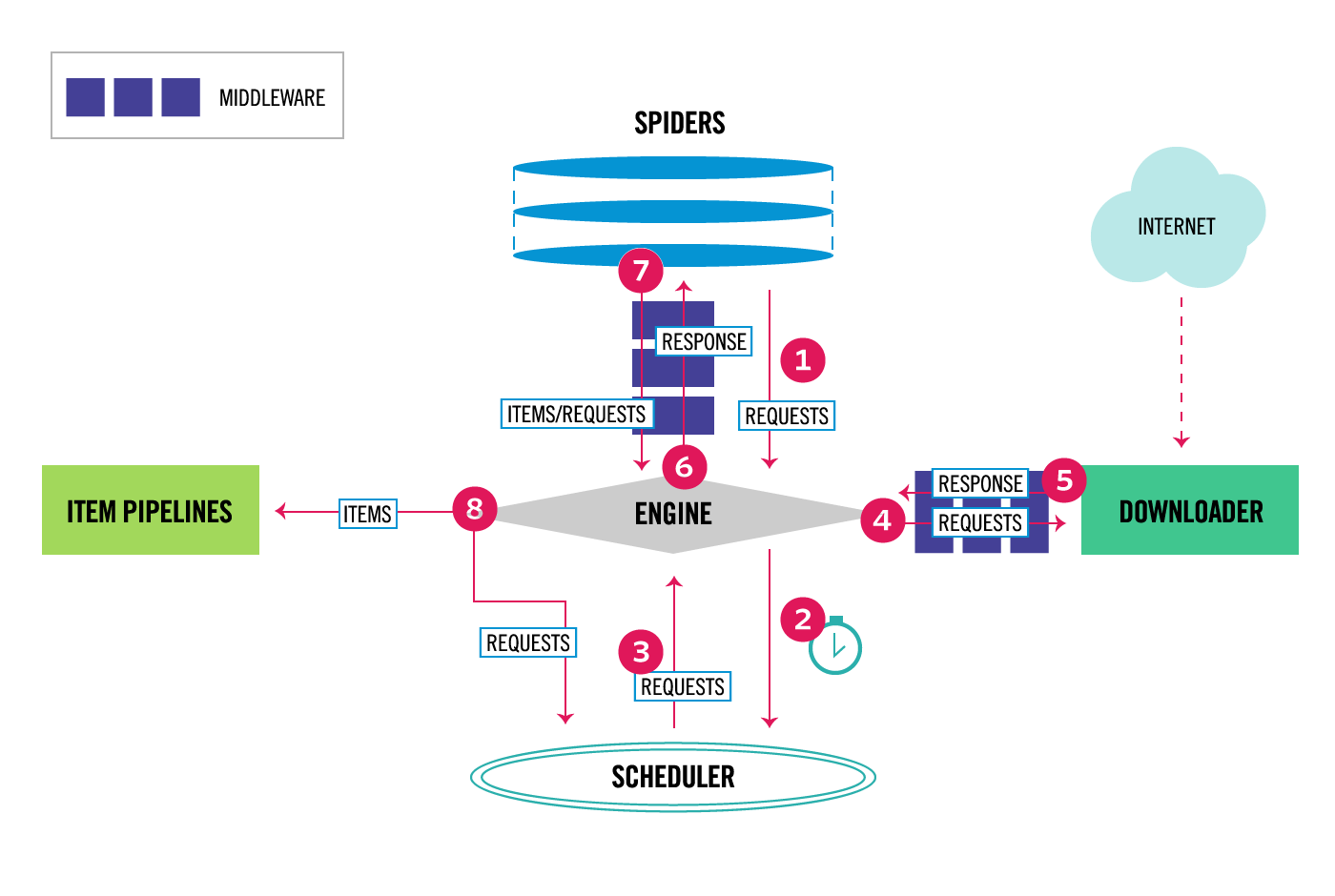
1.2 各个组件简介
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
1.3数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
2.环境准备(主要是在window下)
安装指南:https://docs.scrapy.org/en/latest/intro/install.html
中文的安装指南:http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html
2.1 安装python版本
可以从https://www.anaconda.com/download/下载一个python,省了后期各种麻烦。
2.2 安装scrapy
使用conda安装
conda install -c conda-forge scrapy
或者使用pip安装
pip install Scrapy
如果网络不好, 可以参考下这个地址: https://www.cnblogs.com/microman/p/6107879.html
2.3 下载为win32
从http://sourceforge.net/projects/pywin32/ 选择和python版本和操作系统对应的版本下载安装。
官方描述了为何需要win32 :You need to install pywin32 because of this Twisted bug.
详细信息可以看看官方网页:https://docs.scrapy.org/en/latest/faq.html#scrapy-crashes-with-importerror-no-module-named-win32api
2.4提示c++ build(可选)
请安装cmd终端的提示,去指定的网址提示去下载build exe安装程序,安装后重新启动下,我们使用的python是cpython,所以依赖c的环境,如果你的电脑安装有vs2015,vs2017
这些c的环境都是有的。这里就可以不用安装了。
如果提示有这个信息。 error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
如果twisted无法安装,建议去这个地方https://pypi.python.org/pypi/Twisted/下载,自行安装。然后去安装scrapy。
2.5 配置环境变量
将你的python.exe 所在的目录和子目录Scripts目录都添加到PATH环境变量中去。
比如C:\Python2.7\;C:\Python2.7\Scripts\;
2.6 测试python 和scrapy
C:\Users\Administrator>python
Python 3.6. |Anaconda custom (-bit)| (default, May , ::) [MSC v. bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>>
2.7 ipython 或者bpython的安装
ipython和bpython都是python的解析器,在cmd终端下提供
ipython的安装相对简单,使用如下命令即可安装
C:\Users\Administrator>conda install ipython
或者
C:\Users\Administrator>pip install ipython
如果你是在linux下编译安装ipython可以参考下我的另一篇博客:http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_001.html
bpython的安装有点问题:
可以参看我的另一篇博客:http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_006_bpython.html
环境准备好了。 那我们就可以开始scrapy的入门学习了。
2.8开发环境
我这里使用pycharm 软件去开发python, 当然小伙伴们也是可以使用其他的开发环境, 我这里推荐下打开也可以试试vs code 去搭建python开发环境。
scrapy爬虫学习系列一:scrapy爬虫环境的准备的更多相关文章
- scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
随机推荐
- Spring源码Gradle
Microsoft Windows [版本 10.0.17134.590](c) 2018 Microsoft Corporation.保留所有权利. D:\Workspaces\idea\sprin ...
- textarea--去掉空格的办法
我在初次用到textarea多行文本框时,遇到的问题是:默认出现了两行空格,如图: 代码是(错误的写法): 最后才发现,原来是: textarea标签是需要写在同一行,不能换行,正确的写法:
- 发现一款适合php网站的管理软件——kodexplorer,能取代ftp
今天偶然看到可以利用可道云来管理网站的文件.可道云不需要数据库,因此搭建非常简单.搭建的方法也很简单.传统的 WordPress 站点的文件管理,通常是是通过 FTP 或者服务器面板自带的文件管理器来 ...
- vue项目使用webpack构建的本地服务环境,在手机上访问调试
使用vue脚手架构建的项目,一般在本地localhost运行,配合浏览器的模拟调试工具开发. 如果想看真机环境,又不想build到线上. webpack能配置电脑本地内网环境指向公网访问的! 1.打开 ...
- 手动安装OpenCV下的IPP加速库
写在前面 安装opencv的时候,往往会卡在这里: IPPICV: Download: ippicv_2019_lnx_intel64_general_20180723.tgz 其实就是墙的原因,然后 ...
- java发送短信验证码
业务: 手机端点击发送验证码,请求发送到java服务器端,由java调用第三方平台(我们使用的是榛子云短信http://smsow.zhenzikj.com)的短信接口,生成验证码并发送. SDK下载 ...
- 长沙学院APP之校园模块设计
一.简单回顾 在上次的scrum冲刺中,我将整个长沙学院的APP做了一个基本的架构设计以及框架设计,确定好了APP的功能结构以及实现时所要达到的效果,并且做了一个简单的用户登录界面,由于所学知识有限, ...
- AI应用开发实战
AI应用开发实战 出发点 目前,人工智能在语音.文字.图像的识别与解析领域带来了跨越式的发展,各种框架.算法如雨后春笋一般,互联网上随处可见与机器学习有关的学习资源,各大mooc平台.博客.公开课都推 ...
- Python学到什么程度就可以去找工作?掌握这4点足够了!
大家在学习Python的时候,有人会问“Python要学到什么程度才能出去找工作”,对于在Python培训机构学习Python的同学来说这都不是问题,因为按照Python课程大纲来,一般都不会有什么问 ...
- [Swift]LeetCode342. 4的幂 | Power of Four
Given an integer (signed 32 bits), write a function to check whether it is a power of 4. Example 1: ...