SVM中的软间隔最大化与硬间隔最大化
参考文献:https://blog.csdn.net/Dominic_S/article/details/83002153
1.硬间隔最大化


对于以上的KKT条件可以看出,对于任意的训练样本总有ai=0或者yif(xi) - 1=0即yif(xi) = 1
1)当ai=0时,代入最终的模型可得:f(x)=b,样本对模型没有贡献
2)当ai>0时,则必有yif(xi) = 1,注意这个表达式,代表的是所对应的样本刚好位于最大间隔边界上,是一个支持向量,这就引出一个SVM的重要性质:训练完成后,大部分的训练样本都不需要保留,最终的模型仅与支持向量有关。
2.软间隔最大化
如果数据加入了少数噪声点,而模型为了迁就这几个噪声点改变决策平面,即使让数据仍然线性可分,但是边际会大大缩小,这样模型的准确率虽然提高了,但是泛化误差却升高了,这也是得不偿失的。
或者有一些数据,线性不可分,或者说线性可分状况下训练准确率不能达到100%,即无法让训练误差为0。
此时此刻,我们需要让决策边界能够忍受一小部分训练误差,而不能单纯地寻求最大边际了。因为边际越大被分错的样本也就会越多,因此我们需要找出一个”最大边际“与”被分错的样本数量“之间的平衡,引入一个松弛系数ζ。
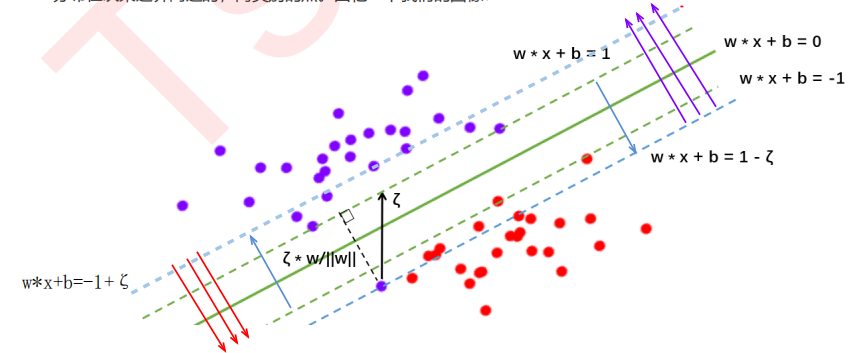
在硬间隔中:决策平面是绿色实线,约束条件是要保证两类样本点分别位于两条绿色虚线的两侧,所有样本点都被正确分类。
在软间隔中:决策平面是绿色实线,约束条件变为蓝色虚线,且红色样本点在红色箭头一侧即可,紫色样本点在紫色箭头一侧即可。
由于ζ是松弛量,即偏离绿色虚线的函数距离(绿色虚线到决策平面的距离为1),松弛量越大,表示样本点离绿色虚线越远,如果松弛量大于1,那么表示样本越过决策平面,即允许该样本点被分错。模型允许分类错误的样本数越多,模型精确性越低。因此需要对所有样本的松弛量之和进行控制,因此将所有样本量之和加入目标函数。
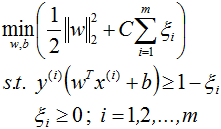
C表示的是在目标函数中松弛量的权重,C越大表示最小化时更多的考虑最小化ζ,即允许模型错分的样本越少,C值的给定需要调参。
同硬间隔最大化SVM,构造软间隔最大化的约束问题对应的Lagrange函数如下:
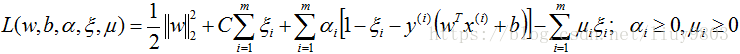
优化目标函数为: 
对偶问题为: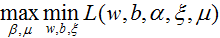

带入对偶函数得:
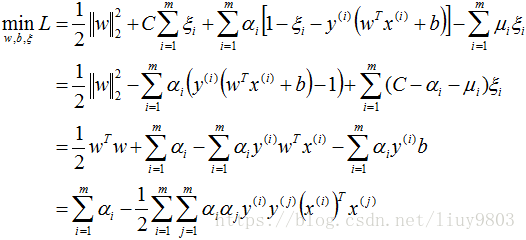
再对上式求α的极大值,即得对偶问题:
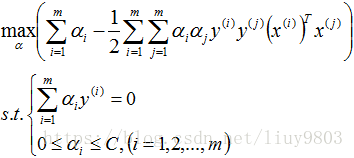
此处的约束条件由上面求导的2、3式可得。
软间隔SVM的KKT条件:
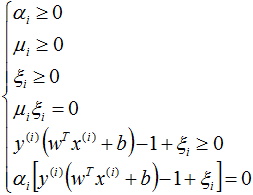
根据KKT条件中的对偶互补条件 αi(yi(wTxi+b)-1+ξi)=0 可知αi>0(即ai≠0)的样本为支持向量,在间隔边界上、间隔边界(yi(w*xi+b)=1)与决策超平面之间、或者在超平面误分一侧的向量都有可能是支持向量,因为软间隔模型中每个样本的αi、ξi不同,而αi、ξi不同的取值,样本就有可能落在不同的区域:
(1)αi<C,则μi>0,ξi=0,支持向量xi恰好落在间隔边界上;
(2)αi=C,则μi=0,则ζ≠0
0<ξi<1,则分类正确,xi在间隔边界与决策超平面之间;
ξi=1,则xi在决策超平面上;
ξi>1,则xi位于决策超平面误分一侧。
求得的每个样本点的α和ζ都不同,因此那条有松弛量的蓝色虚线超平面只是一个抽象概念,是不存在的,因为各个样本的松弛量都不同,C只是对总体样本的松弛量(即误差进行控制)。
支持向量是满足yi(w*xi+b)=1-ζi这个式子的样本,因为每个样本的ζi不同因此支持向量构不成线。间隔边界yi(w*xi+b)=1还在原来的地方。
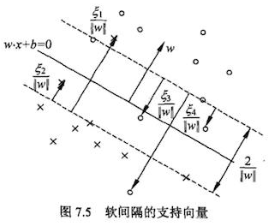
图中箭头所指的样本点都可以是支持向量。
如果给定的惩罚项系数C越小,在模型构建的时候就允许存在越多分类错误的样本,也就是表示此时模型的准确率比较低;如果给定的C越大,表示在模型构建的时候,允许分类错误的样本越少,也就表示此时模型的准确率比较高。
SVM中的软间隔最大化与硬间隔最大化的更多相关文章
- SVM中的间隔最大化
参考链接: 1.https://blog.csdn.net/TaiJi1985/article/details/75087742 2.李航<统计学习方法>7.1节 线性可分支持向量机与硬间 ...
- <老古董>线性支持向量机中的硬间隔(hard margin)和软间隔(soft margin)是什么
_________________________________________________________________________________________________ Th ...
- SVM中为何间隔边界的值为正负1
在WB二面中,问到让讲一下SVM算法. 我回答的时候,直接答道线性分隔面将样本分为正负两类,取平行于线性切割面的两个面作为间隔边界,分别为:wx+b=1和wx+ b = -1. 面试官就问,为什么是正 ...
- linux中的软、硬链接
linux中的软.硬链接 硬链接 硬链接(hard link),如果文件B是文件A的硬链接,则A的inode节点号与B的inode节点号相同,即一个inode节点对应两个不同的文件名,两个文件名指向同 ...
- svm中的数学和算法
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本.非线性及高维模式识别中表现出很多特有的优势,并可以推广应用到函数拟合等其它 ...
- 《机器学习_07_01_svm_硬间隔支持向量机与SMO》
一.简介 支持向量机(svm)的想法与前面介绍的感知机模型类似,找一个超平面将正负样本分开,但svm的想法要更深入了一步,它要求正负样本中离超平面最近的点的距离要尽可能的大,所以svm模型建模可以分为 ...
- SVM中的线性分类器
线性分类器: 首先给出一个非常非常简单的分类问题(线性可分),我们要用一条直线,将下图中黑色的点和白色的点分开,很显然,图上的这条直线就是我们要求的直线之一(可以有无数条这样的直线) 假如说, ...
- 机器学习实战:基于Scikit-Learn和TensorFlow 第5章 支持向量机 学习笔记(硬间隔)
数据挖掘作业,需要实现支持向量机进行分类,记录学习记录 环境:win10,Python 3.7.0 SVM的基本思想:在类别之间拟合可能的最宽的间距,也叫作最大间隔分类 书上提供的源代码绘制了两个图, ...
- word文档巧替换(空行替换、空格替换、软回车替换成硬回车)
一.空行替换 在日常工作中,我们经常从网上下载一些文字材料,往往因空行多使得页数居高不下.一般方法是:在“编辑”菜单中打开“查找和替换”对话框(或按ctrl+H),在“查找内容”中输入“^p^p”“替 ...
随机推荐
- 监控框架 - prometheus
1.关于Prometheus Prometheus是一个根据应用的metrics来进行监控的开源工具.相信很多工程都在使用它来进行监控,有关详细介绍可以查看官网:https://prometheus. ...
- 我罗斯方块最终篇(Interface类)
负责的任务 游戏过场及界面设计 Interface类的基础实现 根据队友需求完善Interface类功能 Interface类的本地测试 辅助队友改良游戏操作 代码要点 我们主要是通过控制台进行界面渲 ...
- 菜鸡的Java笔记 - java 线程常用操作方法
线程常用操作方法 线程的命名操作,线程的休眠,线程的优先级 线程的所有操作方法几乎都在 Thread 类中定义好了 线程的命名和取得 ...
- flume的配置详解
Flume:===================== Flume是一种分布式的.可靠的.可用的服务,可以有效地收集.聚合和移动大量的日志数据. 它有一个基于流数据的简单而灵活的体系结构. 它具有健壮 ...
- OpenStack平台的使用
一.OpenStack平台的使用 使用双节点部署,192.168.16.10为控制节点.192.168.16.20为计算节点. (一).创建镜像 1.在控制节点中找到qcow2镜像 [root@con ...
- netcore项目中IStartupFilter使用
背景: netcore项目中有些服务是在通过中间件来通信的,比如orleans组件.它里面服务和客户端会指定网关和端口,我们只需要开放客户端给外界,服务端关闭端口.相当于去掉host,这样省掉了些指定 ...
- [atAGC004F]Namori
考虑树的情况,将其以任意一点为根建树 对于每一个节点,考虑其要与父亲操作几次才能使子树内均为黑色,这可以用形如$(0/1,x)$的二元组来描述,其中0/1即表示其要求操作时父亲是白色/黑色且要操作$x ...
- Dubbo的反序列化安全问题——kryo和fst
目录 0 前言 1 Dubbo的协议设计 2 Dubbo中的kryo序列化协议触发点 3 Dubbo中的fst序列化协议触发点 3.1 fst复现 3. 2 思路梳理 4 总结 0 前言 本篇是Dub ...
- 第02章_MySQL环境搭建
第02章_MySQL环境搭建 1. MySQL的卸载 步骤1:停止MySQL服务 在卸载之前,先停止MySQL8.0的服务.按键盘上的"Ctrl + Alt + Delete"组合 ...
- Redis | 第5章 Redis 中的持久化技术《Redis设计与实现》
目录 前言 1. RDB 持久化 1.1 RDB 文件的创建与载入 1.2 自动间隔性保存 1.2.1 设置保存条件 1.2.2 dirty 计数器和 lastsave 属性 1.2.3 检查保存条件 ...