使用pmml实现跨平台部署机器学习模型
一、概述
对于由Python训练的机器学习模型,通常有pickle和pmml两种部署方式,pickle方式用于在python环境中的部署,pmml方式用于跨平台(如Java环境)的部署,本文叙述的是pmml的跨平台部署方式。
PMML(Predictive Model Markup Language,预测模型标记语言)是一种基于XML描述来存储机器学习模型的标准语言。如,对在Python环境中由sklearn训练得到的模型,通过sklearn2pmml模块可将它完整地保存为一个pmml格式的文件,再在其他平台(如java)中加载该文件进行使用,从而实现模型的跨平台部署。
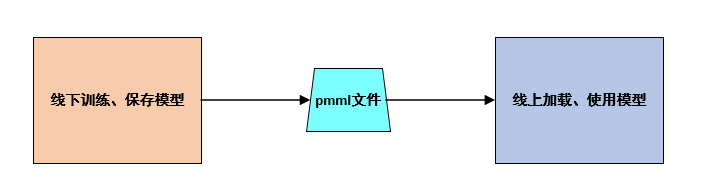
二、实现步骤
1.训练环境中安装生成pmml文件的工具。
如在Python环境中安装sklearn2pmml模块(pip install sklearn2pmml)。
2.训练模型。
3.将模型保存为pmml文件。
4.部署环境中导入依赖的工具包。
如在Java环境中导入pmml-evaluator、pmml-evaluator-extension(特殊情况下另加)、jaxb-core、jaxb-api、jaxb-impl等jar包。
5.开发应用,加载、使用模型。
注:对sklearn2pmml生成的pmml模型文件,在java中加载使用时,需将文件中的命名空间属性xmlns=".../PMML-4_4"改为xmlns=".../PMML-4_3",以适应低版本的jar包对它的解析。
三、示例
在python中使用sklearn训练一个线性回归模型,并在java环境中部署使用。
工具:PyCharm-2017、Python-39、sklearn2pmml-0.76.1;IntelliJ IDEA-2018、jdk-14.0.2。
1.训练数据集training_data.csv
2.训练、保存模型
import sklearn2pmml as pmml
from sklearn2pmml import PMMLPipeline
from sklearn import linear_model as lm
import os
import pandas as pd
def save_model(data, model_path):
pipeline = PMMLPipeline([("regression", lm.LinearRegression())]) #定义模型,放入pipeline管道
pipeline.fit(data[["x"]], data["y"]) #训练模型,由数据中第一行的名称确定自变量和因变量
pmml.sklearn2pmml(pipeline, model_path, with_repr=True) #保存模型
if __name__ == "__main__":
data = pd.read_csv("training_data.csv")
model_path = model_path = os.path.dirname(os.path.abspath(__file__)) + "/my_example_model.pmml"
save_model(data, model_path)
print("模型保存完成。")
3.将pmml文件的xmlns属性修改为PMML-4_3

4.java程序中加载、使用模型
(1)创建maven项目,将pmml模型文件拷贝至项目根目录下。
(2)加入依赖包
<dependencies>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>1.4.15</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>javax.xml</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.1</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.2.11</version>
</dependency>
</dependencies>
(3)java程序加载模型完成预测
public class MLPmmlDeploy {
public static void main(String[] args) {
String model_path = "./my_example_model.pmml"; //模型路径
int x = 20; //测试的自变量值
Evaluator model = loadModel(model_path); //加载模型
Object r = predict(model, x); //预测
Double result = Double.parseDouble(r.toString());
System.out.println("预测的结果为:" + result);
}
private static Evaluator loadModel(String model_path){
PMML pmml = new PMML(); //定义PMML对象
InputStream inputStream; //定义输入流
try {
inputStream = new FileInputStream(model_path); //输入流接到磁盘上的模型文件
pmml = PMMLUtil.unmarshal(inputStream); //将输入流解析为PMML对象
}catch (Exception e){
e.printStackTrace();
}
ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance(); //实例化一个模型构造工厂
Evaluator evaluator = modelEvaluatorFactory.newModelEvaluator(pmml); //将PMML对象构造为Evaluator模型对象
return evaluator;
}
private static Object predict(Evaluator evaluator, int x){
Map<String, Integer> data = new HashMap<String, Integer>(); //定义测试数据Map,存入各元自变量
data.put("x", x); //键"x"为自变量的名称,应与训练数据中的自变量名称一致
List<InputField> inputFieldList = evaluator.getInputFields(); //得到模型各元自变量的属性列表
Map<FieldName, FieldValue> arguments = new LinkedHashMap<FieldName, FieldValue>();
for (InputField inputField : inputFieldList) { //遍历各元自变量的属性列表
FieldName inputFieldName = inputField.getName();
Object rawValue = data.get(inputFieldName.getValue()); //取出该元变量的值
FieldValue inputFieldValue = inputField.prepare(rawValue); //将值加入该元自变量属性中
arguments.put(inputFieldName, inputFieldValue); //变量名和变量值的对加入LinkedHashMap
}
Map<FieldName, ?> results = evaluator.evaluate(arguments); //进行预测
List<TargetField> targetFieldList = evaluator.getTargetFields(); //得到模型各元因变量的属性列表
FieldName targetFieldName = targetFieldList.get(0).getName(); //第一元因变量名称
Object targetFieldValue = results.get(targetFieldName); //由因变量名称得到值
return targetFieldValue;
}
}

示例下载:
https://download.csdn.net/download/Albert201605/45645889
End.
参考
- https://www.freesion.com/article/4628411548/
- https://www.cnblogs.com/pinard/p/9220199.html
- https://www.cnblogs.com/moonlightpoet/p/5533313.html
使用pmml实现跨平台部署机器学习模型的更多相关文章
- 使用pmml跨平台部署机器学习模型Demo——房价预测
基于房价数据,在python中训练得到一个线性回归的模型,在JavaWeb中加载模型完成房价预测的功能. 一. 训练.保存模型 工具:PyCharm-2017.Python-39.sklearn2 ...
- 使用Flask部署机器学习模型
Introduction A lot of Machine Learning (ML) projects, amateur and professional, start with an aplomb ...
- 用PMML实现机器学习模型的跨平台上线
在机器学习用于产品的时候,我们经常会遇到跨平台的问题.比如我们用Python基于一系列的机器学习库训练了一个模型,但是有时候其他的产品和项目想把这个模型集成进去,但是这些产品很多只支持某些特定的生产环 ...
- 用PMML实现python机器学习模型的跨平台上线
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- 使用ML.NET + ASP.NET Core + Docker + Azure Container Instances部署.NET机器学习模型
本文将使用ML.NET创建机器学习分类模型,通过ASP.NET Core Web API公开它,将其打包到Docker容器中,并通过Azure Container Instances将其部署到云中. ...
- tensorflow机器学习模型的跨平台上线
在用PMML实现机器学习模型的跨平台上线中,我们讨论了使用PMML文件来实现跨平台模型上线的方法,这个方法当然也适用于tensorflow生成的模型,但是由于tensorflow模型往往较大,使用无法 ...
- Kubernetes入门(四)——如何在Kubernetes中部署一个可对外服务的Tensorflow机器学习模型
机器学习模型常用Docker部署,而如何对Docker部署的模型进行管理呢?工业界的解决方案是使用Kubernetes来管理.编排容器.Kubernetes的理论知识不是本文讨论的重点,这里不再赘述, ...
- 基于FastAPI和Docker的机器学习模型部署快速上手
针对前文所述 机器学习模型部署摘要 中docker+fastapi部署机器学习的一个完整示例 outline fastapi简单示例 基于文件内容检测的机器学习&fastapi 在docker ...
- 为你的机器学习模型创建API服务
1. 什么是API 当调包侠们训练好一个模型后,下一步要做的就是与业务开发组同学们进行代码对接,以便这些‘AI大脑’们可以顺利的被使用.然而往往要面临不同编程语言的挑战,例如很常见的是调包侠们用Pyt ...
随机推荐
- 通俗易懂,Layui前端框架!
前言 layui 是一款采用自身模块规范编写的前端 UI 框架,遵循原生 HTML/CSS/JS 的书写与组织形式,门槛极低,拿来即用.其外在极简,却又不失饱满的内在,体积轻盈,组件丰盈,从核心代 ...
- SpringBoot之网站的登陆注册逻辑
网站的登录注册实现逻辑 该文章主要是为了整理之前学习项目中的知识点,并进行一定程度的理解. 技术列表: SpringBoot MySQL redis JWT 用户登录逻辑: 首先打开前端登录页面,F1 ...
- 洛谷5024 保卫王国 (动态dp)
qwq非正解. 但是能跑过. 1e5 log方还是很稳的啊 首先,考虑最普通的\(dp\) 令\(dp1[x][0]表示不选这个点,dp1[x][1]表示选这个点的最大最小花费\) 那么 \(dp1[ ...
- AES解密尾部出现乱码问题
说明 在使用AES解密的时候我发现解密出来的字符串尾部一直都有乱码 解决方案 尾部字符串的ascii码就是删除位索引 具体代码: cryptor = AES.new('AES_KEY'.encode( ...
- FastAPI 学习之路(三十二)创建数据库
在大型的web开发中,我们肯定会用到数据库操作,那么FastAPI也支持数据库的开发,你可以用 PostgreSQL MySQL SQLite Oracle 等 本文用SQLite为例.我们看下在fa ...
- 【UE4 C++】简单获取名称、状态、时间、帧数、路径与FPaths
基于UKismetSystemLibrary 获取各类名称 // Returns the actual object name. UFUNCTION(BlueprintPure, Category = ...
- 2021.9.22考试总结[NOIP模拟59]
T1 柱状图 关于每个点可以作出两条斜率绝对值为\(1\)的直线. 将绝对值拆开,对在\(i\)左边的点\(j\),\(h_i-i=h_j-j\),右边则是把减号换成加号. 把每个点位置为横坐标,高度 ...
- 利用Ambari平台安装与部署Hadoop
* 本篇是利用Ambari平台安装与部署Hadoop,如果需要原生部署Hadoop,请点击以下地址: https://www.cnblogs.com/live41/p/15467263.html 一. ...
- Linux Shell Here Document
Here Document 是一种有特殊用处的代码块,他使用IO重定向的形式记录了一段临时的文本或交互命令,并且把这些文本或命令 依次的传递给一个程序或一个命令,作为他运行时的标准输入. Here d ...
- fd定时器--timerfd学习
定时器 可以用系统定时器信号SIGALARM 最近工作需要于是又发现了一个新玩意timerfd配合epoll使用. man 手册看一下 TIMERFD_CREATE(2) Linux Programm ...