UFLDL深度学习笔记 (四)用于分类的深度网络
UFLDL深度学习笔记 (四)用于分类的深度网络
1. 主要思路
本文要讨论的“UFLDL 建立分类用深度网络”基本原理基于前2节的softmax回归和 无监督特征学习,区别在于使用更“深”的神经网络,也即网络中包含更多的隐藏层,我们知道前一篇“无监督特征学习”只有一层隐藏层。原文深度网络概览不仅给出了深度网络优势的一种解释,还总结了几点训练深度网络的困难之处,并解释了逐层贪婪训练方法的过程。关于深度网络优势的表述非常好,贴在这里。
使用深度网络最主要的优势在于,它能以更加紧凑简洁的方式来表达比浅层网络大得多的函数集合。正式点说,我们可以找到一些函数,这些函数可以用\(k\)层网络简洁地表达出来(这里的简洁是指隐层单元的数目只需与输入单元数目呈多项式关系)。但是对于一个只有\(k-1\)层的网络而言,除非它使用与输入单元数目呈指数关系的隐层单元数目,否则不能简洁表达这些函数。
逐层训练法的思路表述如下:
逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。在每一步中,我们把已经训练好的前\(k-1\) 层固定,然后增加第\(k\)层(也就是将我们已经训练好的前\(k-1\) 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器,我们会在后边的章节中给出细节)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差).
深度网络相比于前一篇“无监督特征学习”增加了隐藏层数,带来局部极值 梯度弥散问题,解决的办法就是将网络作为一个整体用有监督学习对权重参数进行微调:fine-tune 。值得注意的是,开始微调时,两隐藏层与softmax分类输出层的权重$W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}; \theta $不是用随机参数赋值的,而是用稀疏自编码学习获得的,和 无监督特征学习的做法相同。
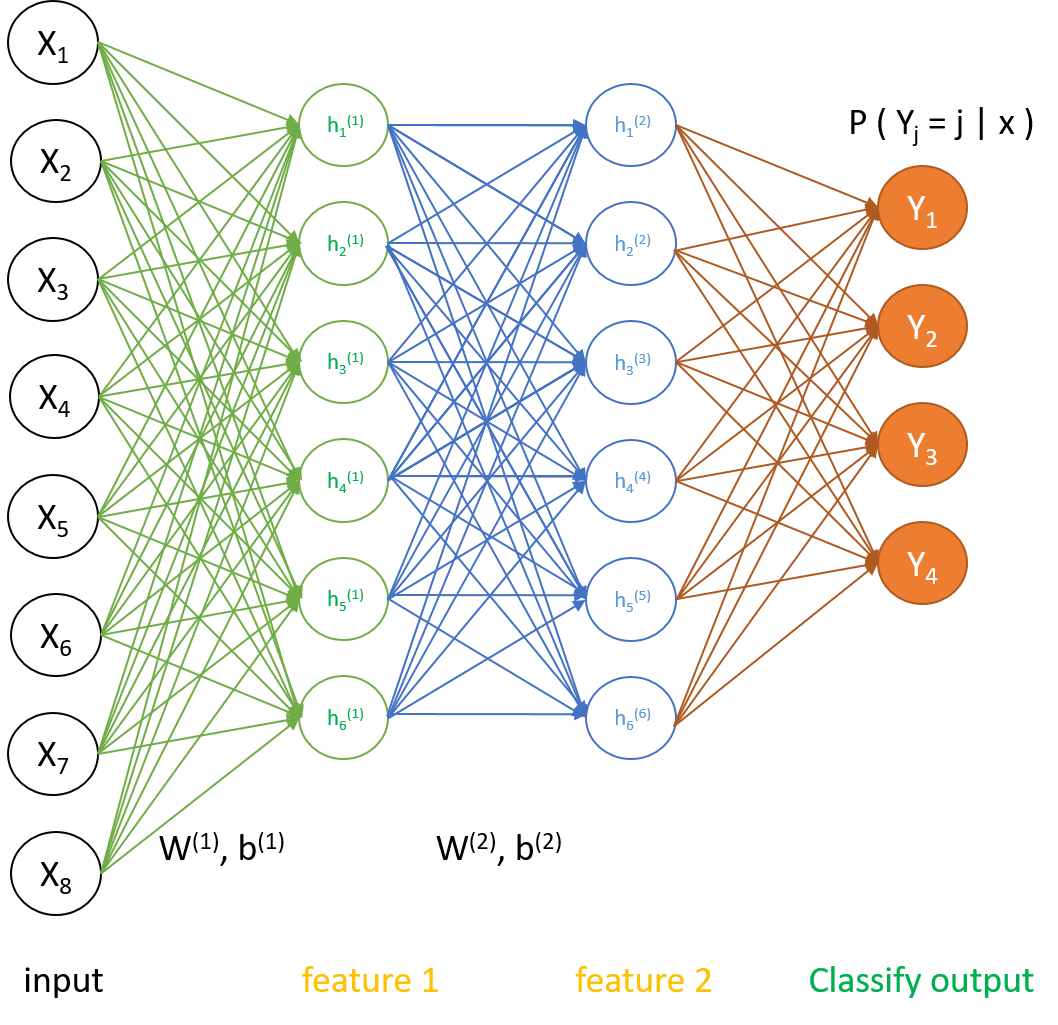
2. 训练步骤与公式推导
- 把有标签数据分为两部分\(X_{train},X_{test}\),先对一份原始数据\(X_{train}\)做无监督的稀疏自编码训练,获得输入层到第一隐藏层的最优化权值参数\(W^{(1)}, b^{(1)}\)
- 将\(X_{train}\)前向传播通过第一隐藏层得到\(feature1\), 以此为输入训练第二隐藏层,得到最优化权值参数\(W^{(2)}, b^{(2)}\);
- 将\(feature1\)前向传播通过第二隐藏层得到\(feature2\), 以此为输入训练softmax输出层,得到最优化权值参数\(\theta\);
- 用\(W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}; \theta\)作为初始化参数,以\(X_{train}\)为输入,用后向传播原理给出整个网络的代价函数与梯度,在已知分类标签情况下微调权重参数,得到最优化参数\(W_{optim}^{(1)}, b_{optim}^{(1)}; W_{optim}^{(2)}, b_{optim}^{(2)}; \theta_{optim}\)。
- 用上述参数对测试集\(X_{test}\)进行分类,计算出分类准确率。
可以看出需要使用新公式的地方在于第4步,深度网络的代价函数的梯度,这里仍然运用最基础的梯度后向传播原理,从softmax回归推导中我们知道输出层权重\(\theta\)梯度为
\]
矩阵化表达为:
\]
使用稀疏自编码 中相同的方法,推导残差后向传导形式,即可得到代价函数对\(W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}\)的梯度,
由于softma输出并没有用\(sigmoid\)函数,则激活值对输出值的偏导为1,输出层\(n_l=4\)
\]
运用后向传导原理,第三层(第二隐藏层)的残差为
\]
根据梯度与残差矩阵的关系可得:
\]
同理可求出
\]
这样我们就得到了代价函数对\(W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}; \theta\)的梯度矩阵。可以看到softmax是个特例外,多层隐藏层形式统一,这样便于代码循环实现,这里对两层隐藏层的推导只是为了便于理解。
3. 代码实现
根据前面的步骤描述,复用原来的系数自编码模块外,我们要增加fine tune的全局代价函数对权重的梯度,实现代码为stackedAECost.m,详见https://github.com/codgeek/deeplearning
function [ cost, grad ] = stackedAECost(theta, inputSize, hiddenSize, ...
numClasses, netconfig, ...
lambda, data, labels,~)
% stackedAECost: Takes a trained softmaxTheta and a training data set with labels,
% and returns cost and gradient using a stacked autoencoder model. Used for
% finetuning.
% theta: trained weights from the autoencoder
% visibleSize: the number of input units
% hiddenSize: the number of hidden units *at the 2nd layer*
% numClasses: the number of categories
% netconfig: the network configuration of the stack
% lambda: the weight regularization penalty
% data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example.
% labels: A vector containing labels, where labels(i) is the label for the
% i-th training example
% We first extract the part which compute the softmax gradient
softmaxTheta = reshape(theta(1:hiddenSize*numClasses), numClasses, hiddenSize);
% Extract out the "stack"
stack = params2stack(theta(hiddenSize*numClasses+1:end), netconfig);
% You will need to compute the following gradients
softmaxThetaGrad = zeros(size(softmaxTheta));
stackgrad = cell(size(stack));
numStack = numel(stack);
for d = 1:numStack
stackgrad{d}.w = zeros(size(stack{d}.w));
stackgrad{d}.b = zeros(size(stack{d}.b));
end
cost = 0; % You need to compute this
% You might find these variables useful
M = size(data, 2);
groundTruth = full(sparse(labels, 1:M, 1));
% forward propagation
activeStack = cell(numStack+1, 1);% first element is input data
activeStack{1} = data;
for d = 2:numStack+1
activeStack{d} = sigmoid((stack{d-1}.w)*activeStack{d-1} + repmat(stack{d-1}.b, 1, M));
end
z = softmaxTheta*activeStack{numStack+1};% softmaxTheta:numClasse×hiddenSize. Z:numClasses×numCases
z = z - max(max(z)); % avoid overflow while keep p unchanged.
za = exp(z); % matrix product: numClasses×numCases
p = za./repmat(sum(za,1),numClasses,1); % normalize the probbility aganist numClasses. numClasses×numCases
cost = -mean(sum(groundTruth.*log(p), 1)) + sum(sum(softmaxTheta.*softmaxTheta)).*(lambda/2);
% back propagation
softmaxThetaGrad = -(groundTruth - p)*(activeStack{numStack+1}')./M + softmaxTheta.*lambda; % numClasses×inputSize
lastLayerDelta = -(groundTruth - p);%各层残差delta定义是J对各层z的偏导数,不是激活值a, 输出层残差delta是▽J/▽z,没有1/a(i,j) 这个系数
lastLayerDelta = (softmaxTheta')*lastLayerDelta.*(activeStack{numStack+1}.*(1-activeStack{numStack+1})); % res of softmax input layer
for d = numel(stack):-1:1
stackgrad{d}.w = (activeStack{d}*lastLayerDelta')'./M;
stackgrad{d}.b = mean(lastLayerDelta, 2);
lastLayerDelta = ((stack{d}.w)')*lastLayerDelta.*(activeStack{d}.*(1-activeStack{d}));
end
%% Roll gradient vector
grad = [softmaxThetaGrad(:) ; stack2params(stackgrad)];
end
function sigm = sigmoid(x)
sigm = 1 ./ (1 + exp(-x));
end
4.图示与结果
数据集仍然来自Yann Lecun的笔迹数据库。

设定与练习说明相同的参数,输入层包含784个节点,第一、第二隐藏层都是196个节点,输出层10个节点。运行代码主文件stackAEExercise.m 可以看到预测准确率达到97.77%。满足练习的标准结果。
我们来比较一下微调前后隐藏层学习到的特征有什么变化。
| 逐层贪心训练 | 微调后 | |
|---|---|---|
| 第一隐层 |  |
 |
| 第二隐层 |  |
 |
| softmax输出层 |  |
 |
类似稀疏自编码对边缘的学习,上图的第一隐藏层特征可理解为笔记钩旋弧线特征,第二隐藏层就难以理解为直观的含义了,深层网络不一定每一层都能对应到人脑对事物的一层理解上,此外微调后似乎是增加了干扰,也期待大牛们能解释一下这些变化!
UFLDL深度学习笔记 (四)用于分类的深度网络的更多相关文章
- 吴恩达深度学习笔记(八) —— ResNets残差网络
(很好的博客:残差网络ResNet笔记) 主要内容: 一.深层神经网络的优点和缺陷 二.残差网络的引入 三.残差网络的可行性 四.identity block 和 convolutional bloc ...
- TensorFlow 深度学习笔记 TensorFlow实现与优化深度神经网络
转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到Issue区讨论 官方教程地址 视频/字幕下载 全 ...
- TensorFlow 深度学习笔记 从线性分类器到深度神经网络
转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到Issue区讨论 官方教程地址 视频/字幕下载 L ...
- TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎st ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
UFLDL深度学习笔记 (二)Softmax 回归 本文为学习"UFLDL Softmax回归"的笔记与代码实现,文中略过了对代价函数求偏导的过程,本篇笔记主要补充求偏导步骤的详细 ...
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- UFLDL深度学习笔记 (五)自编码线性解码器
UFLDL深度学习笔记 (五)自编码线性解码器 1. 基本问题 在第一篇 UFLDL深度学习笔记 (一)基本知识与稀疏自编码中讨论了激活函数为\(sigmoid\)函数的系数自编码网络,本文要讨论&q ...
- UFLDL深度学习笔记 (三)无监督特征学习
UFLDL深度学习笔记 (三)无监督特征学习 1. 主题思路 "UFLDL 无监督特征学习"本节全称为自我学习与无监督特征学习,和前一节softmax回归很类似,所以本篇笔记会比较 ...
随机推荐
- VMware开启虚拟化实现CentOS创建KVM
参考: http://blog.csdn.net/liulove_micky/article/details/48343013
- 《Flex 第一步》
//什么是FlexFlex 是一个针对企业级富互联网应用的表示层解决方案.具体地说,Flex是一种应用程序框架.富互联网应用程序,Rich Internet Application,简称RIA,将桌面 ...
- 【spring boot】spring boot 2.0 项目中使用mysql驱动启动创建的mysql数据表,引擎是MyISAM,如何修改启动时创建数据表引擎为【spring boot 2.0】
默认创建数据表使用的引擎是MyISAM 2018-05-14 14:16:37.283 INFO 7328 --- [ restartedMain] org.hibernate.dialect.Dia ...
- IMAP 命令
最近学习了一下IMAP命令,现在也算总结一下学习的东西,先说说IMAP命令,如果你使用的是163.126邮箱,反正是网易家的邮箱,那么这里就有很多坑要踩了,因为网易邮箱的特殊性,由于网易邮箱在中国占有 ...
- [置顶]
Python+Django 复选框选择多个 提交只能保存单个
之前,做表单时使用单选方式,今天修改为复选框方式提交. 问题来了:在选择多个后保存,发现竟然只能最后一个选择. print(request.POST)显示只有最后一个 print(str(reques ...
- UVa221 Urban Elevations
离散化处理.判断建筑可见性比较麻烦.下面采用离散化解决:把所有的x坐标排序去重,在相邻两个x坐标表示的区间中,整个区间要么同时可见,要么同时不可见.如何判断该区间是否可见?具体做法是选取该区间中点坐标 ...
- ISP模块之RAW DATA去噪(二)--BM3D算法
在正式开始本篇文章之前,让我们一起回顾一下CFA图像去噪的一些基本思路与方法.接着我会详细地和大家分享自己学习理解的BM3D算法,操作过程,它的优缺点,最后会给出算法效果图供参考. 在ISP模块里,研 ...
- window命令
查看端口占用命令: 开始--运行--cmd 进入命令提示符 输入netstat -aon 即可看到所有连接的PID 之后在任务管理器中找到这个PID所对应的程序如果任务管理器中没有PID这一项,可以在 ...
- JVM源码分析之FinalReference完全解读
Java对象引用体系除了强引用之外,出于对性能.可扩展性等方面考虑还特地实现了4种其他引用:SoftReference.WeakReference.PhantomReference.FinalRefe ...
- ORACLE截取字符串
每行显示固定字符串,截取字符串 方法一:在循环里面输出 DECLARE l_char VARCHAR2 (3000 ) := 'ORACLEEB电子商务套件SSYSTEMg ...