python爬虫爬取B站视频字幕,简单的数据处理(pandas将字幕写入到CSV文件中)
上文,我们爬取到B站视频的字幕:https://www.cnblogs.com/becks/p/14540355.html
这篇,讲讲怎么把爬到的字幕写到CSV文件中,以便用于后面的分析
本文主要用到“pandas”这个库对数据进行处理
import pandas as pd
首先需要对爬取到的内容进行数据提取
comments = [comment.text for comment in results]#从爬取的数据中取出弹幕数据,返回文本内容
执行后如下图
然后生成字典
comments_dict = {'comments': comments}#创建字典,把字幕内容装入字典
处理数据,使数据以表格形式展示
df = pd.DataFrame(comments_dict)#格式化字幕字典,将字幕内容已表格格式显示
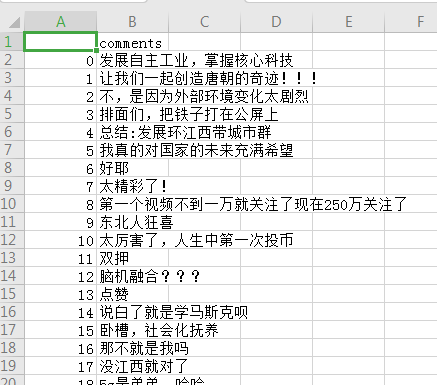
效果如下图

把格式化后的数据,存到CSV文件中
df.to_csv('B站字母.csv', encoding='utf-8-sig')#格式化后的字幕内容写入到CSV文件中
执行后,会在脚本同目录下生成CSV文件,文件内容如下图
全部脚本
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup
import requests
import re
import pandas as pd url = 'http://comment.bilibili.com/309778762.xml'
html = requests.get(url)
html.encoding='utf8' soup = BeautifulSoup(html.text,'lxml')
results = soup.find_all('d') comments = [comment.text for comment in results]#从爬取的数据中取出弹幕数据,返回文本内容
comments_dict = {'comments': comments}#创建字典,把字幕内容装入字典
df = pd.DataFrame(comments_dict)#格式化字幕字典,将字幕内容已表格格式显示
df.to_csv('B站字母.csv', encoding='utf-8-sig')#格式化后的字幕内容写入到CSV文件中
格式化数据“pd.DataFrame”函数的用法可以参考,https://www.cnblogs.com/andrew-address/p/13040035.html
python爬虫爬取B站视频字幕,简单的数据处理(pandas将字幕写入到CSV文件中)的更多相关文章
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- Python 自动爬取B站视频
文件名自定义(文件格式为.py),脚本内容: #!/usr/bin/env python #-*-coding:utf-8-*- import requests import random impor ...
- python爬虫爬取安居客并进行简单数据分析
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 爬取过程一.指定爬取数据二.设置请求头防止反爬三.分析页面并且与网页源码进行比对四.分析页面整理数据 ...
- python爬虫——爬取B站用户在线人数
国庆期间想要统计一下bilibili网站的在线人数变化,写了一个简单的爬虫程序.主要是对https://api.bilibili.com/x/web-interface/online返回的参数进行分析 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
随机推荐
- TCA 复习
HTML中预览PDF 手机端无法识别embed <embed src="***.pdf" id="review" style="width:11 ...
- golang1.23版本之前 Timer Reset方法无法正确使用
golang1.23版本之前 Timer Reset方法无法正确使用 golang1.23 之前 Reset 到底有什么问题 在 golang 的 time.Reset 文档中有这么一句话,为了防止 ...
- GD32F103C8T6看门狗
GD32F10x看门狗 两个看门狗设备(独立看门狗IWDG和窗口看门狗WWDG)可用来检测和解决由软件错误引起的故障: 当计数器达到给定的超时值时,触发一个中断(仅适用于窗口型看门狗)或产生系统复位. ...
- Oracle trunc的使用
在生产环境中我们经常会用到只取年月日或者时间处理的场景,大多数人用的都是to_char(string,'yyyy-mm-dd')或者to_date(string,'yyyy-mm-dd')来处理,不说 ...
- Linux 服务器防火墙开放端口命令(iptables、firewalld和ufw)
本文主要介绍Linux中,Centos.Ubuntu和Debian开放防火墙端口的命令(iptables.firewalld和ufw)方法. 1.Centos中开放端口 1.systemctl sta ...
- MySQL主从复制-原理实战
一.原理 主从复制架构图:主从复制原理: Mysql 中有一种日志叫做 bin 日志(二进制日志).这个日志会记录下所有修改了数据库的SQL 语句(insert,update,delete,creat ...
- vue-element-admin改为从后台获取菜单
一.修改文件\src\router\index.js 文件的asyncRoutes清理为 export const asyncRoutes = [ { path: '*', redirect: '/4 ...
- 0帧起手将腾讯混元大模型集成到Spring AI的全过程解析
在前面,我们已经为大家铺垫了大量的知识点,并深入解析了Spring AI项目的相关内容.今天,我们将正式进入实战环节,从零开始,小雨将带领大家一步步完成将第三方大模型集成到Spring AI中的全过程 ...
- 【忍者算法】从生活场景到回文链表:探索对称性检测|LeetCode 234 回文链表
从生活场景到回文链表:探索对称性检测 生活中的回文现象 在日常生活中,回文无处不在.比如"上海自来水来自海上"."12321"这样正着读和倒着读都一样的字符串或 ...
- halcon中是怎么实现半导体/Led中的GoldenDie的检测方法的 基于局部可变形模板匹配 variation_model模型
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/18739196 这篇简单介绍一下halcon中的print_check_single_chars ...