又来一个挑战 Elastic 的,初识 SigLens
Elastic Stack 在日志领域具备无与伦比的地位,各类新兴的开源项目都声称比 Elastic 更节省资源,同时检索速度也不慢,比如 ClickHouse、Loki、OpenObserve、VMLogs,今天我们来看看另一个项目:SigLens。

SigLens 的官网是:https://www.siglens.com/,其在官网声称了几点选择 SigLens 的理由:
- 高效扩展:在一台 8 核机器上可以处理 8TB/day 的数据,在 800 核的集群上可以处理 1PB/day 的数据。
- 全文检索:可以在任意字段上做全文检索,支持通配符和正则表达式。看起来不是类似 ElasticSearch 的倒排索引的实现。
- 在查询时提取字段:在查询的时候从现有的日志中提取数据作为新字段,新字段可以参与后续的 Pipeline query 过程。
- 快速的数据摄入:创新的微索引功能使您能够以闪电般的速度进行索引。“微索引”是 SigLens 的一个重要概念。
- 查询兼容性:支持多种查询语言,包括 Splunk QL、Elastic DSL、SQL、Loki LogQL。这点好,尤其是 Splunk QL 和 SQL 的支持。
- 支持接入多种数据格式:支持对接各类日志采集器,即 SigLens 不做采集只做存储,支持包括 OpenTelemetry、Fluentd、Fluent Bit、Logstash、Vector、Splunk HEC、Promtail、S3/SQS/SNS 等等。
- 快速安装:提供 git 编译安装、Docker、Helm 等多种方式,我测试过 git 编译安装了,确实很方便。
- 架构简单:开源版貌似只支持单机版,当然,人家单机版已经声称非常牛逼,一台 SigLens 就抵得上几十台 ElasticSearch。
- 统一查看面板:SigLens 不止做底层存储,还做上层 Metrics、Logs、Traces 的统一查看面板。野心挺大哦。
SigLens 对比 ElasticSearch
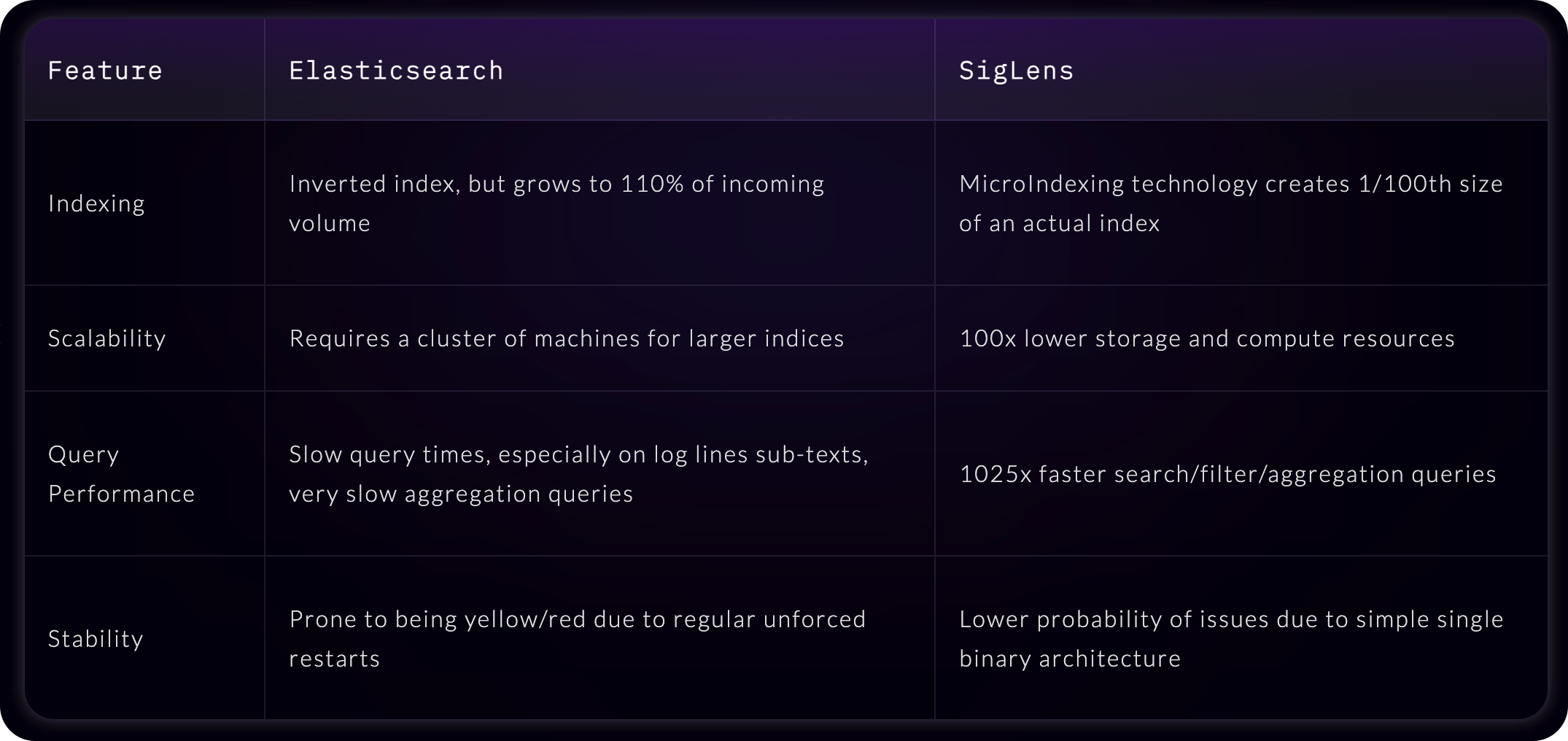
- ElasticSearch 是倒排索引,实际存储量是来源数据的 110% 左右,SigLens 采用微索引技术,存储只需要 1% 哦
- ElasticSearch 通常需要集群才能搞定大数据量,SigLens 单机就可以搞定
- ElasticSearch 的查询速度慢,尤其是那种非结构化字段的查询聚合,而 SigLens 的查询、过滤、聚合是 ElasticSearch 的 1025 倍
- 由于一些节点重启,ElasticSearch 集群动不动就变成 Yellow 状态,有时甚至会变成 Red 状态,SigLens 架构简单,通常没有这些乱七八糟的问题
总之,SigLens 号称自己比 ElasticSearch 牛逼多了。
SigLens 对比 ClickHouse

- ClickHouse 需要预先定义 Engine 才能较好压缩数据,比如使用 MergeTree 引擎,Siglens 采用动态列压缩,零配置
- ClickHouse 需要预先定义物化视图来提升聚合查询性能,SigLens 采用 AgileAggsTree,零配置也可以做到快速聚合查询
- 由于上面提到的各种预定义需求,ClickHouse 运维负担较重,而 SigLens 都是动态零配置,哼哼
- ClickHouse 写入数据需要攒批,否则性能会很差,但是这不符合真正的日志场景,日志就是连续输入的,SigLens 支持连续输入
- ClickHouse 不支持查询时提取字段,SigLens 支持
总之,SigLens 号称自己比 ClickHouse 牛逼多了。
SigLens 对比 Loki

- Loki 只索引日志的元数据,SigLens 索引所有字段
- Loki 查询慢,动不动需要几分钟,SigLens 是亚秒级响应(这吹得有点过了,笔者都看不下去了)
- Loki 使用 S3 作为存储,查询时需要高昂的带宽成本,SigLens 微索引是本地的,本地的最新数据(高度压缩),S3 中的旧数据,由于微索引,从 S3 中提取的数据很少
- Loki 聚合查询慢,而 SigLens,因为 AgileAgssTree 创新带来的闪电般的聚合查询
一句话,SigLens 号称自己比 Loki 牛逼多了。
SigLens 对比 OpenObserve 等
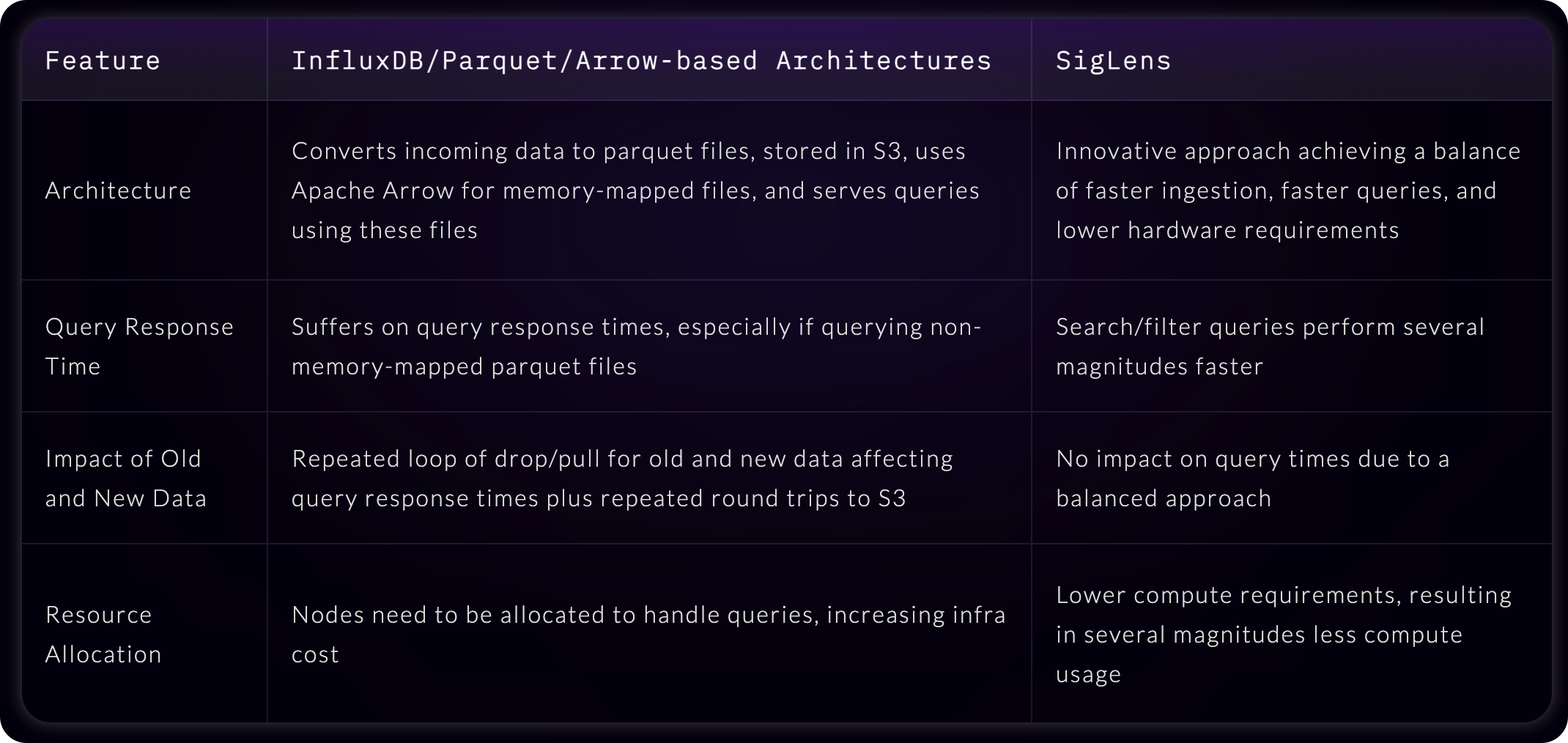
你们这些利用 Parquet/Arrow 格式的存储引擎,我就不多说了,如上图,在 SigLens 眼里,你们都是弟弟。
SigLens 和多种日志存储方案做了对比,不过没有对比 VMLogs,不知道是啥原因,觉得 VMLogs 不够格吗?还是 VMLogs 还没成熟?还是 SigLens 觉得和 VMLogs 半斤八两?
SigLens 安装
SigLens 建议咱们试用 Docker 安装,说一条命令搞定:
curl -L https://siglens.com/install.sh | sh
但是现在这个破网络环境,我还是自己下载代码编译安装吧。SigLens 是 go 写的,我机器上有 go 环境,直接 git clone 下来编译就行了。
git clone https://github.com/siglens/siglens.git
cd siglens
go build -o siglens cmd/siglens/main.go
./siglens --config server.yaml
上面的命令是编译并启动 SigLens 的命令,server.yaml 是配置文件,默认在当前目录下。server.yaml 的内容要看一下,配置项比较少,其中 UI 查询端口默认是 5122,接收数据的接口是 8081。
SigLens 接入日志数据
我之前本地测试过 vector,文章参考:高性能日志转发神器 Vector 的 Github Star 19K 了,对接一下夜莺的日志。那对这个配置稍作修改就可以复用了,我的 vector 的配置文件如下:
data_dir: "/Users/ulric/works/vector-test/data_dir"
api:
enabled: true
sources:
app_logs:
type: "file"
include:
- "/Users/ulric/works/gopath/src/nightingale/logs/*.log"
transforms:
parse_log:
type: "remap"
inputs:
- "app_logs"
source: |
. |= parse_regex!(.message, r'(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{6}) (?P<level>\w+) (?P<source_location>[^ ]+) (?P<message>.+)')
.timestamp = parse_timestamp(.timestamp, format: "%Y-%m-%d %H:%M:%S.6%f") ?? now()
.@timestamp = del(.timestamp)
sinks:
print:
type: "console"
inputs:
- "parse_log"
encoding:
codec: "json"
es:
type: "elasticsearch"
inputs:
- "parse_log"
endpoints:
- http://localhost:8081/elastic/
mode: bulk
healthcheck:
enabled: false
可以看出来,SigLens 是兼容 ElasticSearch 接口的,即 /elastic/ 接口路径,伪装成 ElasticSearch 的样子。很快,你就可以在 SigLens 的 UI 上看到数据了。
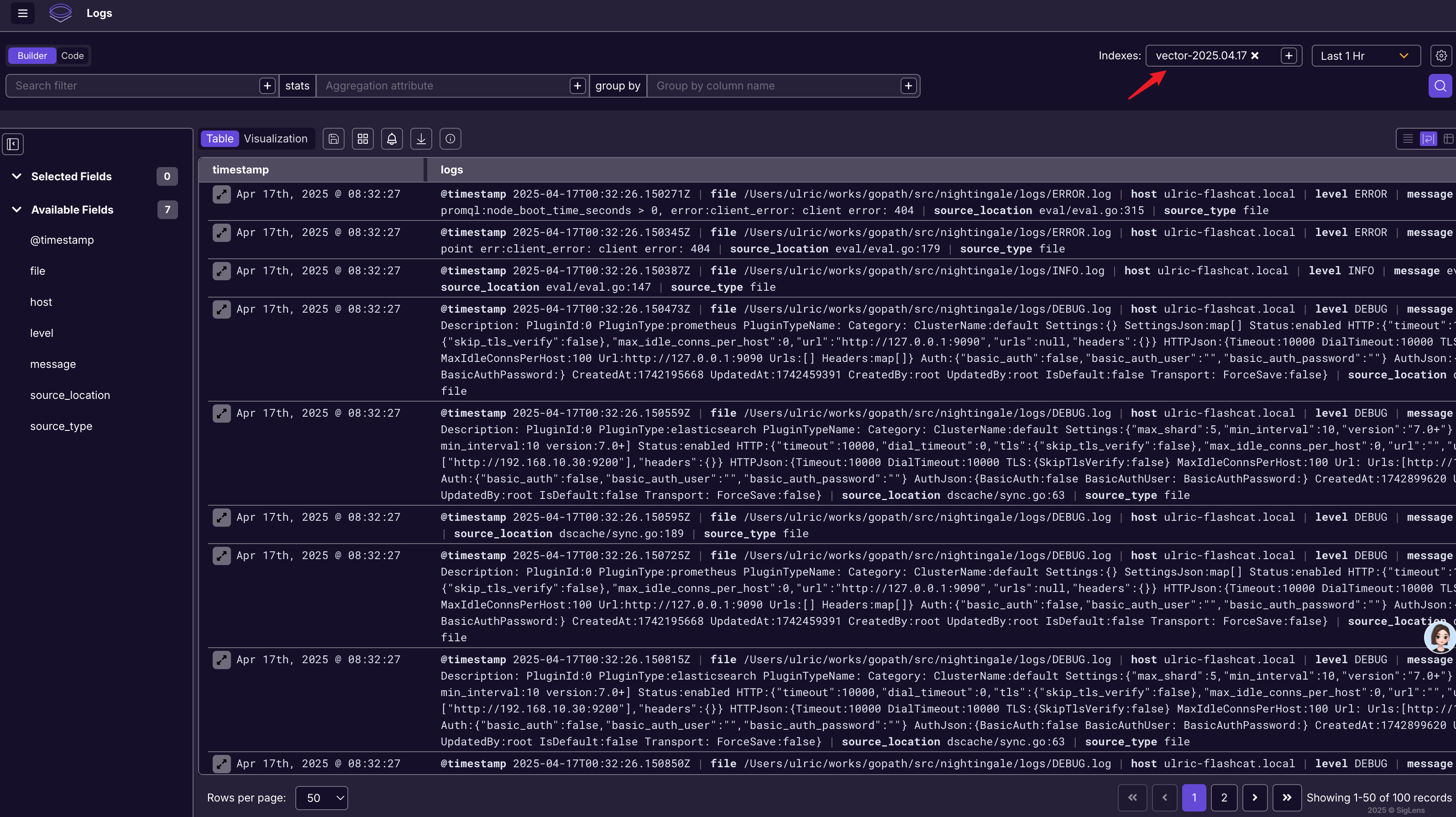
右上角可以看出来,SigLens 也是每天一个索引文件,因为我的采集器是 vector,索引有个 vector 的前缀,不知道是在哪个环节加的。
我大概体验了一下日志检索和聚合功能,感觉还可以,UI 上有些细节处理不到位无关痛痒。不过不支持日志上下文查询功能,就是我看到一条关键日志,想查看这条日志的上面10行和下面10行,目前还没有找到这个功能。难道是要通过 Splunk QL 来写吗?我对 Splunk QL 还不熟悉,有熟悉的小伙伴可以留言指点一下哈。
另外我想查询 vector 作为前缀的所有索引,也没有找到这个功能,即类似 Elastic 里的 index pattern 的功能。这个不支持的话,告警规则就没法用了,按理说应该支持才对。难道 UI 不支持需要调用接口?那就不太方便了。SigLens 的文档不支持检索,找起来有点费劲。
SigLens 接入指标数据
SigLens 支持 Prometheus remote write 方式写入数据,其接口地址为:
http://localhost:8081/promql/api/v1/write
我用 categraf 直接采集了数据推过去,是可以推送成功的。简单查询也可以,比如:
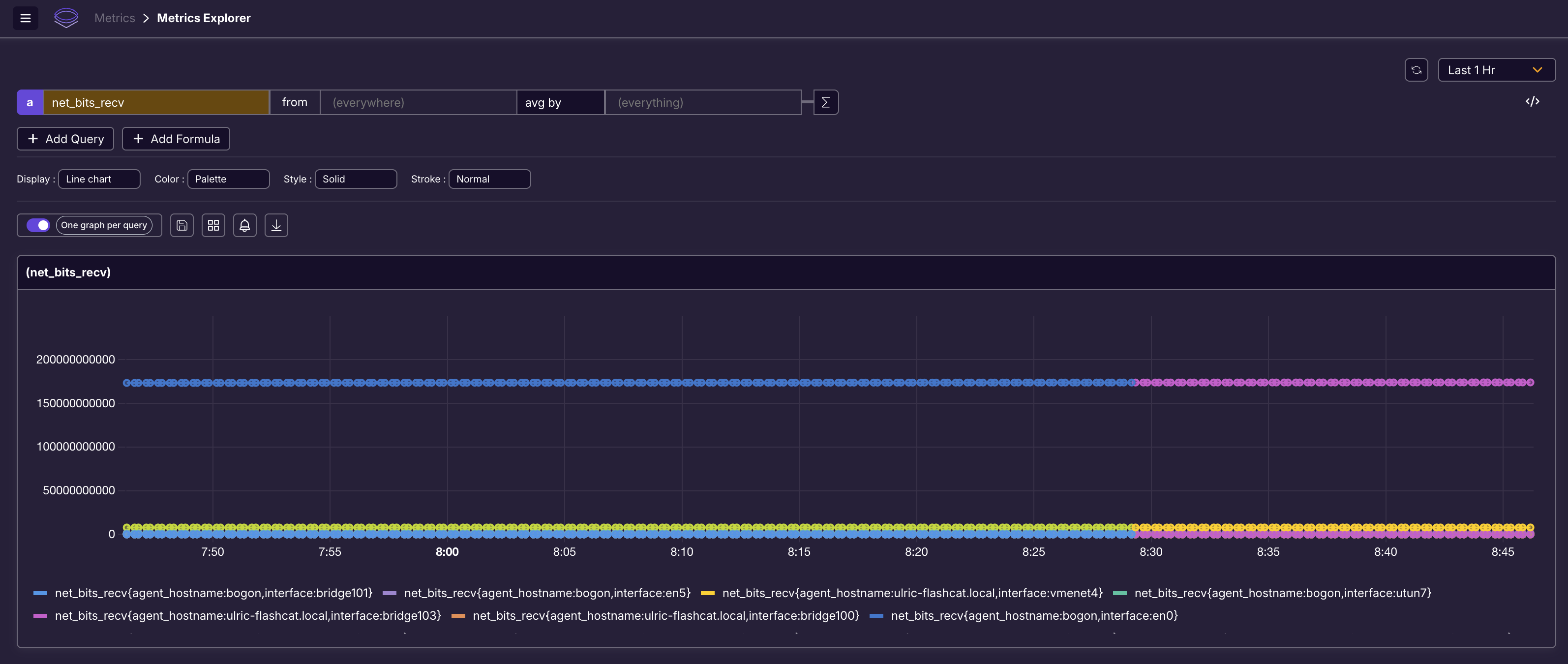
上面查询的是 net_bits_recv 指标,这是一个 Counter 类型的数据,显然大家更关心的是 rate 或 increase 计算之后的结果,于是,我利用它的 UI,增加了 rate 函数:

GG 了,竟然没有让我输入 rate 函数的参数,直接就给我执行了,结果是错误的。好在我切到 code 视图,自己手写 Promql 是可以的:
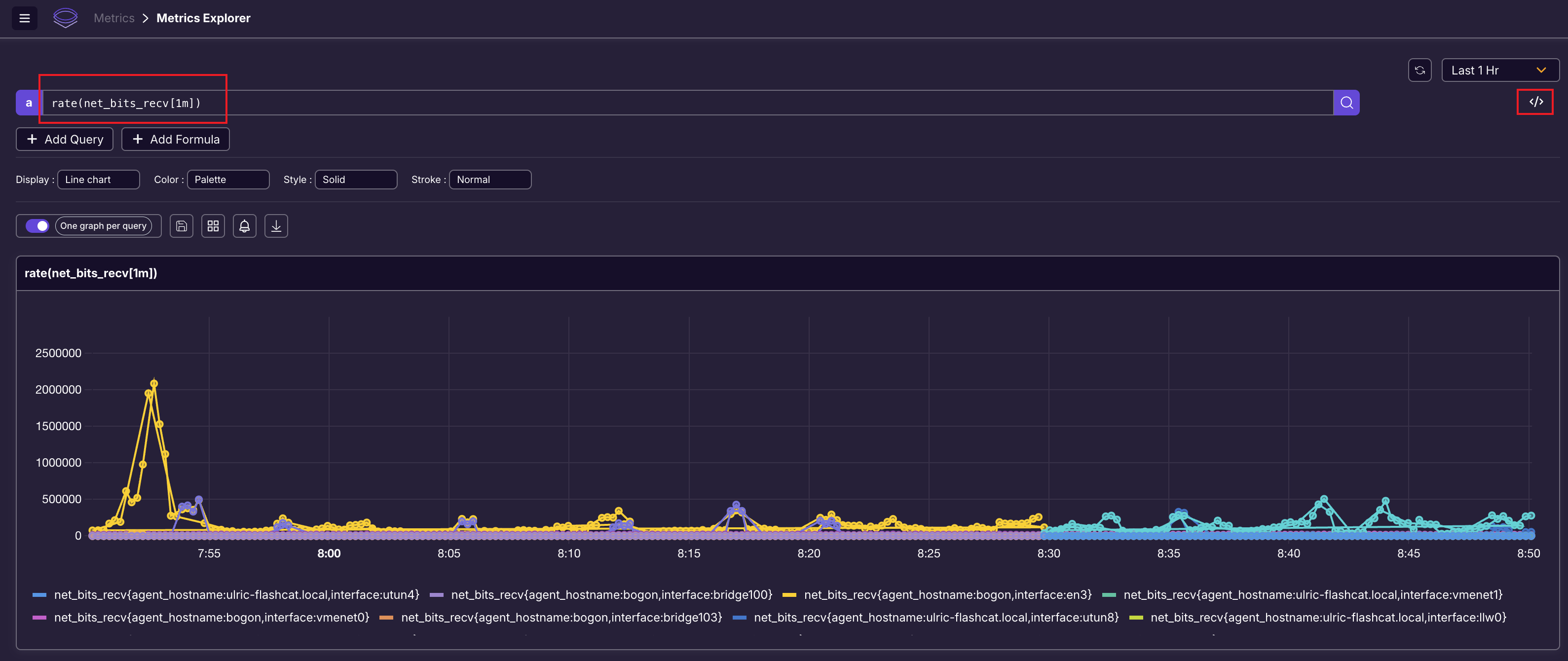
SigLens 的告警能力
上面提了,我没有找到 SigLens 的 index pattern 功能,所以告警规则按理是没法用的(因为每天都会生成一个索引文件,而告警永远是针对最新索引的,所以告警规则里应该指定 index pattern)。但是实际情况并非如此。我昨天 4.16 号配置了一条告警规则,相关属性如下:
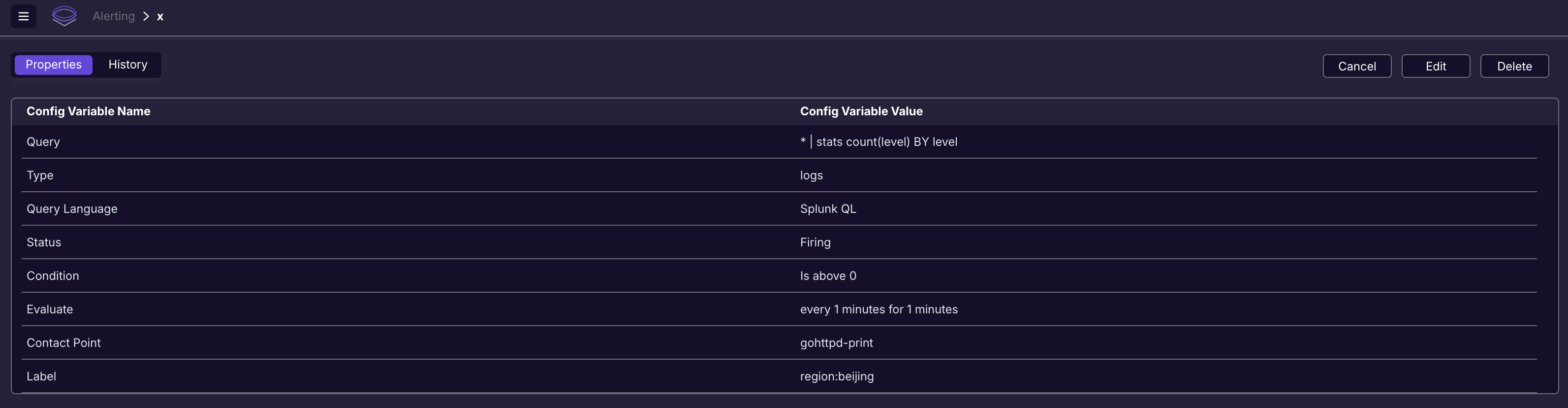
上面的属性中,并没有 index 相关的信息,这就奇怪了,拿到 SigLens 是对所有日志数据都做这个告警判定吗?还是说,SigLens 期望不同的 App 要单独部署一个 SigLens 实例?今天 4.17 号,我重新打开这个告警规则,点击编辑:
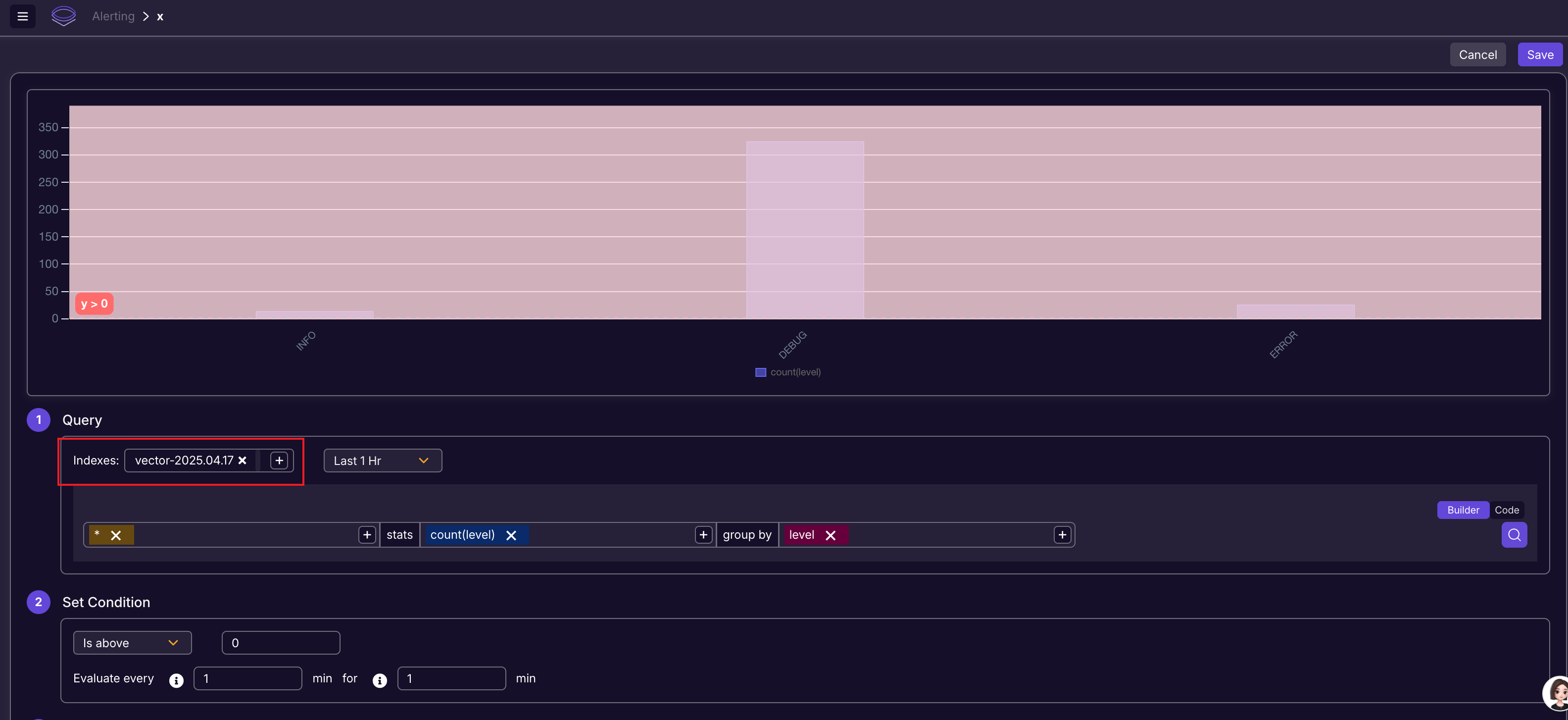
它自动帮我选择了 vector-2025.04.17 这个今天最新生成的索引让我预览数据。不知道它到底是怎么个逻辑,已懵圈。
点评
昨天大概研究了一天,底层数据存储吹得很牛逼,需要大数据量压测一下,如果真有他说的这么好,那前途不可限量。UI 层面有一些乱七八糟的小问题,再给点时间,按理说都可以修复。国内也有类似的创业公司,比如 GreptimeDB,也是尝试把 Metrics、Logs、Traces 统一存储,但是 GreptimeDB 目前是专注做存储没有涉及上层可观测性产品,否则就跟我们是竞品了,哈哈。而 SigLens 是从底层存储到上层可观测性产品都做了,上层做的还比较简陋,未来会如何尚不得而知。
指标、日志等数据都采集了,就是告警,通常各个公司都有多套告警相关的系统,导致告警散落各处,没法统一做告警降噪、排班、认领、升级,我们创业做了一个统一告警响应平台:Flashduty,注册就可以免费试用,创业不易感谢大家支持了解:https://flashcat.cloud/product/flashduty/。
又来一个挑战 Elastic 的,初识 SigLens的更多相关文章
- Elastic Static初识(01)
写在前面 Elastic Static 是指由Elasticsearch,Logstash,Kibana,Beats等组件结合起来而构成的一个数据收集,分析,可视化的一个架构.我们经常听说过的ELK就 ...
- AI 的下一个重大挑战:理解语言的细微差别
简评:人类语言非常博大精妙,同一句话在不同的语境下,就有不同的含义.连人类有时候都不能辨别其中细微的差别,机器能吗?这就是人工智能的下一个巨大挑战:理解语言的细微差别.本文原作者是 Salesforc ...
- 初识pipeline
1.pipeline的产生 从一个现象说起,有一家咖啡吧生意特别好,每天来的客人络绎不绝,客人A来到柜台,客人B紧随其后,客人C排在客人B后面,客人D排在客人C后面,客人E排在客人D后面,一直排到店面 ...
- 做为一个前端工程师,是往node方面转,还是往HTML5方面转
文章背景:问题本身来自于知乎,但是我感觉这个问题很典型,有必要把问题在整理一下,重新分享出来. 当看到这个问题之前,我也碰到过很多有同样疑惑的同学,他们都有一个共同的疑问该学php还是nodejs,包 ...
- 60分钟Python快速学习(给发哥一个交代)
60分钟Python快速学习 之前和同事谈到Python,每次下班后跑步都是在听他说,例如Python属于“胶水语言啦”,属于“解释型语言啦!”,是“面向对象的语言啦!”,另外没有数据类型,逻辑全靠空 ...
- 通向高可扩展性之路(推特篇) ---- 一个推特用来支撑1亿5千万活跃用户、30万QPS、22MB每秒Firehose、以及5秒内推送信息的架构
原文链接:http://highscalability.com/blog/2013/7/8/the-architecture-twitter-uses-to-deal-with-150m-active ...
- 转:鏖战双十一-阿里直播平台面临的技术挑战(webSocket, 敏感词过滤等很不错)
转自:http://www.infoq.com/cn/articles/alibaba-broadcast-platform-technology-challenges 鏖战双十一-阿里直播平台面临的 ...
- 初识CSS3之媒体查询(2015年05月31日)
一.什么是媒体查询 媒体查询是面向不同设备提供不同样式的一种实现方式,它可以为每种类型的用户提供最佳的体验,也是响应式设计的实现方式. 现今每天都有更多的手机和平板电脑问市.消费者能够拥有可想象到的各 ...
- 最艰难的采访IT公司ThoughtWorks代码挑战——FizzBuzzWhizz游戏
最近的互联网招聘平台拉勾网在五月推出了"最艰难的采访IT公司"码挑战活动,评选出了5个最难面试的IT公司,即:ThoughtWorks.Google.Unisys.Rackspac ...
- 使用 Node.js 搭建一个 API 网关
原文地址:Building an API Gateway using Node.js 外部客户端访问微服务架构中的服务时,服务端会对认证和传输有一些常见的要求.API 网关提供共享层来处理服务协议之间 ...
随机推荐
- 独立看门狗IWDG
一.简介 STM32F10xxx内置两个看门狗(独立看门狗是12位递减计数器,窗口看门狗是7位递减计数器),提供了更高的安全性.时间的精确性和使用的灵活性.两个看门狗设备(独立看门狗和窗口看门 ...
- ADALM-Pluto修改芯片类型为AD9364模式
ADALM-Pluto 使用芯片AD9363(325 MHz - 3.8 GHz),但可切换至 AD9364(70 MHz - 6 GHz)模式,此篇随笔将采用串口调试的方式将 Pluto 设置为 A ...
- Prometheus修改数据存储位置
Prometheus修改数据存储位置 Prometheus的数据存储位置可以通过配置文件中的 --storage.tsdb.path 参数来指定.默认情况下,数据存储在Prometheus安装目录下的 ...
- 在flink消费一段时间kafka后,kafka-group的offset被重置了是怎么回事?
一.背景 腾讯Flink使用 KafkaSource API创建source端,源码中默认开启了checkpoint的时候提交offset 到kafka-broker.读取kafka数据写入到iceb ...
- vue-element-template改为从后台获取菜单
一.后端接口获取菜单信息 1.返回数据样式 { "code": 20000, "data": [{ "menuId": "2000 ...
- flutter-延时执行
//1秒后这个i行 Future.delayed(Duration(milliseconds: 1000), () { //代码省略 });
- 刷入Magisk错误:1教程
面具是目前使用最多的授权APP了,兼容主流安卓版本,基本上已彻底的替代的之前的supersu授权,面具magisk不仅支持给APP进行授权ROOT,还支持隐藏root功能magiskhide,使得手机 ...
- Java进阶 - [1-4] 反射
一.类加载区别 当我们刚接触java语言的时候,我们最常见的代码应该就是初始化某个对象,然后调用该对象的方法. 1.使用new创建对象,返回对象的引用.Student student = new St ...
- 机器学习 | 强化学习(2) | 动态规划求解(Planning by Dynamic Programming)
动态规划求解(Planning by Dynamic Programming) 动态规划概论 动态(Dynamic):序列性又或是时序性的问题部分 规划(Programming):最优化一个程序(Pr ...
- PDManer 入门教程:超强代码生成工具!
PDManer 入门教程:超强代码生成工具!https://www.51cto.com/article/753161.html