storm从入门到放弃(二),任务分配过程-核心机密
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了100多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来。

集群环境
storm机器有4台节点(物理机),三台是supervisor,每一台supervisor上面启动4个work进程(JVM进程),一共有12个work进程。
Topology程序
public class WordCountTopologyMain {
public static void main(String[] args) throws Exception {
TopologyBuilder intsmaze= new TopologyBuilder();
intsmaze.setSpout("spout", new RandomSentenceSpout(),3);
intsmaze.setBolt("split", new SplitSentenceBolt(),9).shuffleGrouping("spout");
intsmaze.setBolt("count", new WordCountBolt(),3).fieldsGrouping("split",new Fields("word"));
Config conf = new Config();
conf.setDebug(false);
//定义你希望集群分配多少个工作进程给你来执行这个topology,这里3个进程(work)来运行15个execute(线程)
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
}
supervisor1上面的task编号为1(spout); ,,(bolt task split); (bolt task wordcount) supervisor2上面的task编号为2(spout); ,,(bolt task split); (bolt task wordcount) supervisor3上面的task编号为3(spout); ,,(bolt task split); (bolt task wordcount)
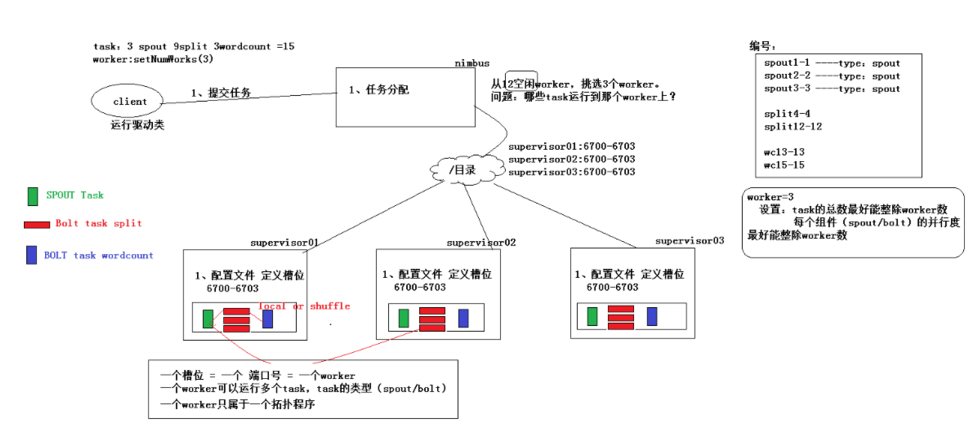
Topology程序
public class WordCountTopologyMain {
public static void main(String[] args) throws Exception {
TopologyBuilder intsmaze= new TopologyBuilder();
intsmaze.setSpout("spout", new RandomSentenceSpout(),3).setNumTasks(9);
//3是说明该spout启动几个线程来运行。该组件每个线程执行3个task.
intsmaze.setBolt("split", new SplitSentenceBolt(),9).shuffleGrouping("spout");
//不指定默认一个线程一个task任务
intsmaze.setBolt("count", new WordCountBolt(),3).fieldsGrouping("split",new Fields("word"));
Config conf = new Config();
conf.setDebug(false);
//定义你希望集群分配多少个工作进程给你来执行这个topology,这里3个进程(work)来运行15个execute(线程)
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
}
supervisor1上面的task编号为spout -,spout1-(spout); split -, split -, split -(bolt task split); wordcount -(bolt task wordcount) supervisor2上面的task编号为spout2-,spout -(spout); split -, split -, split -(bolt task split); wordcount -(bolt task wordcount) supervisor3上面的task编号为spout -,spout -(spout); split -, split -, split -(bolt task split); wordcount -(bolt task wordcount)
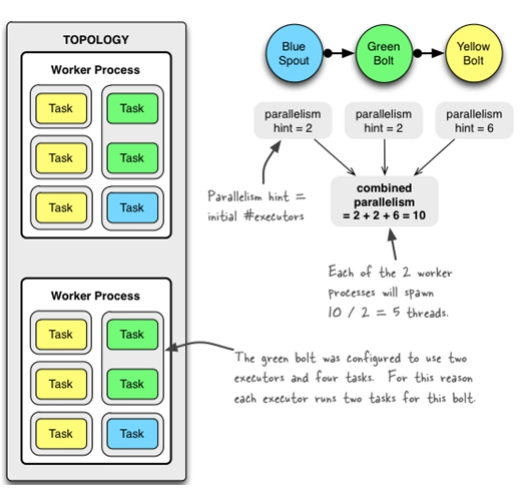
配置并行度
efaults.yaml < storm.yaml < topology-specific configuration < internal component-specific configuration < external component-specific configuration
tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置。
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过storm rebalance 命令任意调整。
storm从入门到放弃(二),任务分配过程-核心机密的更多相关文章
- hive从入门到放弃(二)——DDL数据定义
前一篇文章,介绍了什么是 hive,以及 hive 的架构.数据类型,没看的可以点击阅读:hive从入门到放弃(一)--初识hive 今天讲一下 hive 的 DDL 数据定义 创建数据库 CREAT ...
- storm从入门到放弃(一),storm介绍
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了100多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来. 原文和作者一起讨论:http:// ...
- storm从入门到放弃(三),放弃使用《StreamId》特性。
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- Go语言从入门到放弃(二) 优势/关键字
本来这里是写数据类型的,但是规划了一下还是要一步步来,那么本篇就先介绍一下Go语言的 优势/关键字 吧 本章转载 <The Way to Go>一书 Go语言起源和发展 Go 语 言 起 ...
- storm从入门到放弃(三),放弃使用 StreamId 特性
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- FlaskWeb开发从入门到放弃(二)
第5章 章节五 01 内容概要 02 内容回顾 03 面向对象相关补充:metaclass(一) 04 面向对象相关补充:metaclass(二) 05 WTforms实例化流程分析(一) 06 WT ...
- robotium从入门到放弃 二 第一个实例
1.导入被测试的源码 我们先下载加你计算器源码,下载地址: https://robotium.googlecode.com/files/AndroidCalculator.zip 如果地址被墙无法现在 ...
- MyBatis从入门到放弃二:传参
前言 我们在mapper.xml写sql,如果都是一个参数,则直接配置parameterType,那实际业务开发过程中多个参数如何处理呢? 从MyBatis API中发现selectOne和selec ...
- Ldap 从入门到放弃(二)
OpenLDAP 服务器安装与配置 本文内容是自己通过官网文档.网络和相关书籍学习和理解并整理成文档,其中有错误或者疑问请在文章下方留言. 一.概述 本文以Centos 6.8(64bit)为例介绍 ...
随机推荐
- 摘抄自知乎的redis相关
1.知乎日报的基础数据和统计信息是用 Redis 存储的,这使得请求的平均响应时间能在 10ms 以下.其他数据仍然需要存放在另外的地方,其实完全用 Redis 也是可行的,主要的考量是内存占用.就使 ...
- .htaccess伪静态(URL重写)绑定域名到子目录实现子站点
Apache主机一般支持.htaccess伪静态,即可以实现绑定域名到子目录.一个空间多个站点. 应用举例:绑定htaccess.800m.net到htaccess目录 根目录下.htaccess内容 ...
- .Net WebApi基本操作
一.服务端 1.新建webapi项目 2.配置WebApiConfig public const string DEFAULT_ROUTE_NAME = "DB";// DB指数据 ...
- 关于HTML学习整理(一)
新人,自己整理,第一次发,以后慢慢整理,欢迎指点,那些链接怎么做的,希望有人告知一下,谢谢! HTML页面写法,标签成对出现,可嵌套使用 <html> <head> <t ...
- css实现居中的五中方法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 7.modifier插件的自定义和使用
1.在plugins下面创建一个文件 modifier.changeDate.php 编写: <?php function smarty_modifier_changeDate($utime,$ ...
- html5小游戏基础知识
显示一个DIV和隐藏一个DIV 首先,我们要显示一个DIV和隐藏一个DIV需要使用css里面使用: .hide{ display:none;} .show{display:block;} 在需要显示或 ...
- mybatis学习笔记(二)-- 使用mybatisUtil工具类体验基于xml和注解实现
项目结构 基础入门可参考:mybatis学习笔记(一)-- 简单入门(附测试Demo详细过程) 开始体验 1.新建项目,新建类MybatisUtil.java,路径:src/util/Mybatis ...
- maven仓库--搭建局域网私服(windows版)
使用nexus搭建局域网私服 一. 认识maven仓库 1.1 maven仓库的作用 回想之前不用maven的时候,我们用eclipse原始的项目骨架构建项目时,在工程目录下往往有一个lib文件夹 ...
- EasyNetQ之多态发布和订阅
你能够订阅一个接口,然后发布基于这个接口的实现. 让我们看下一个示例.我有一个接口IAnimal和两个实现Cat和Dog: public interface IAnimal { string Name ...